Distribuție aleatorie uniformă. Conversia unei variabile aleatoare distribuite uniform într-una cu distribuție normală
Ca exemplu de variabilă aleatoare continuă, luați în considerare o variabilă aleatoare X distribuită uniform pe intervalul (a; b). Spunem că variabila aleatoare X distribuite uniform pe intervalul (a; b), dacă densitatea sa de distribuție nu este constantă pe acest interval:
Din condiția de normalizare, determinăm valoarea constantei c . Aria de sub curba densității distribuției ar trebui să fie egală cu unu, dar în cazul nostru este aria unui dreptunghi cu o bază (b - α) și o înălțime c (Fig. 1). 
Orez. 1 Densitate uniformă de distribuție
De aici găsim valoarea constantei c: ![]()
Deci, densitatea unei variabile aleatoare distribuite uniform este egală cu 
Să găsim acum funcția de distribuție prin formula:
1) pentru ![]()
2) pentru
3) pentru 0+1+0=1.
În acest fel, 
Funcția de distribuție este continuă și nu scade (Fig. 2). 
Orez. 2 Funcția de distribuție a unei variabile aleatoare distribuite uniform
Sa gasim așteptarea matematică a unei variabile aleatoare distribuite uniform dupa formula:
Varianta uniformă de distribuție se calculează prin formula și este egal cu
Exemplul #1. Valoarea diviziunii la scară a instrumentului de măsură este 0,2. Citirile instrumentului sunt rotunjite la cea mai apropiată diviziune întreagă. Aflați probabilitatea ca în timpul citirii să se facă o eroare: a) mai mică de 0,04; b) mare 0,02
Soluţie. Eroarea de rotunjire este o variabilă aleatoare distribuită uniform pe intervalul dintre diviziunile întregi adiacente. Considerați intervalul (0; 0,2) ca o astfel de împărțire (Fig. a). Rotunjirea poate fi efectuată atât spre marginea stângă - 0, cât și spre dreapta - 0,2, ceea ce înseamnă că o eroare mai mică sau egală cu 0,04 poate fi făcută de două ori, care trebuie luată în considerare la calcularea probabilității: 

P = 0,2 + 0,2 = 0,4
Pentru al doilea caz, valoarea erorii poate depăși, de asemenea, 0,02 pe ambele granițe de diviziune, adică poate fi fie mai mare decât 0,02, fie mai mică de 0,18. 
Atunci probabilitatea unei erori ca aceasta:
Exemplul #2. S-a presupus că stabilitatea situației economice din țară (absența războaielor, dezastrelor naturale etc.) în ultimii 50 de ani poate fi judecată după natura distribuției populației pe vârstă: într-o situație calmă, ar trebui să fie uniformă. În urma studiului, s-au obținut următoarele date pentru una dintre țări.
Există vreun motiv să credem că a existat o situație instabilă în țară?Efectuăm decizia folosind calculatorul Testarea ipotezei. Tabel pentru calcularea indicatorilor.
| Grupuri | Interval mijloc, x i | Cantitate, fi | x i * f i | Frecvența cumulativă, S | |x - x cf |*f | (x - x sr) 2 *f | Frecvența, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
medie ponderată
Indicatori de variație.
Rate absolute de variație.
Gama de variație este diferența dintre valorile maxime și minime ale atributului seriei primare.
R = X max - X min
R=70 - 0=70
Dispersia- caracterizează măsura răspândirii în jurul valorii sale medii (măsura dispersiei, adică abaterea de la medie).
Deviație standard.
Fiecare valoare a seriei diferă de valoarea medie de 43 cu cel mult 23,92
Testarea ipotezelor despre tipul de distribuție.
4. Testarea ipotezei despre distributie uniforma populatia generala.
Pentru a testa ipoteza despre distribuția uniformă a lui X, i.e. conform legii: f(x) = 1/(b-a) în intervalul (a,b)
necesar:
1. Estimați parametrii a și b - capetele intervalului în care au fost observate valorile posibile ale lui X, conform formulelor (* indică estimările parametrilor):
2. Aflați densitatea de probabilitate a distribuției estimate f(x) = 1/(b * - a *)
3. Găsiți frecvențele teoretice:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Comparați frecvențele empirice și teoretice folosind testul Pearson, presupunând numărul de grade de libertate k = s-3, unde s este numărul de intervale inițiale de eșantionare; dacă totuși s-a făcut o combinație de frecvențe mici și, prin urmare, intervalele în sine, atunci s este numărul de intervale rămase după combinație.
Soluţie:
1. Găsiți estimările parametrilor a * și b * ai distribuției uniforme folosind formulele:
2. Aflați densitatea distribuției uniforme presupuse:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Găsiți frecvențele teoretice:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Restul n s vor fi egali:
n s = n*f(x)(x i - x i-1)
| i | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Prin urmare, regiunea critică pentru această statistică este întotdeauna dreapta: dacă densitatea sa de probabilitate este constantă în acest interval, iar în afara ei este 0 (adică, o variabilă aleatorie X concentrat pe segmentul [ A, b], pe care are o densitate constantă). Conform acestei definiții, densitatea unui segment distribuit uniform pe segment [ A, b] variabilă aleatorie X se pare ca:
Unde Cu există un număr. Cu toate acestea, este ușor de găsit folosind proprietatea densității de probabilitate pentru r.v. concentrat pe segmentul [ A,
b]:
 . De aici rezultă că
. De aici rezultă că  , Unde
, Unde  . Prin urmare, densitatea distribuită uniform pe segmentul [ A,
b] variabilă aleatorie X se pare ca:
. Prin urmare, densitatea distribuită uniform pe segmentul [ A,
b] variabilă aleatorie X se pare ca:
 .
.
Pentru a judeca uniformitatea distribuției n.s.v. X posibil din următoarele considerente. O variabilă aleatoare continuă are o distribuție uniformă pe intervalul [ A, b] dacă ia valori doar din acest segment, iar orice număr din acest segment nu are un avantaj față de alte numere din acest segment în sensul de a putea fi valoarea acestei variabile aleatoare.
Variabilele aleatoare cu o distribuție uniformă includ variabile precum timpul de așteptare al unui vehicul la oprire (la un interval constant de mișcare, timpul de așteptare este distribuit uniform pe acest interval), eroarea de rotunjire a numărului la un număr întreg (distribuit uniform). pe [−0,5 , 0.5 ]) si altii.
Tipul funcției de distribuție F(X)
A,
b] variabilă aleatorie X este căutată după densitatea de probabilitate cunoscută f(X)
folosind formula conexiunii lor  . În urma calculelor corespunzătoare, obținem următoarea formulă pentru funcția de distribuție F(X)
segment distribuit uniform [ A,
b] variabilă aleatorie X
:
. În urma calculelor corespunzătoare, obținem următoarea formulă pentru funcția de distribuție F(X)
segment distribuit uniform [ A,
b] variabilă aleatorie X
:
 .
.
Cifrele prezintă grafice ale densității de probabilitate f(X) și funcții de distribuție f(X) segment distribuit uniform [ A, b] variabilă aleatorie X :


Așteptările matematice, varianța, abaterea standard, modul și mediana unui segment distribuit uniform [ A, b] variabilă aleatorie X calculată din densitatea de probabilitate f(X) în mod obișnuit (și pur și simplu din cauza aspectului simplu f(X) ). Rezultatul sunt următoarele formule:
ci moda d(X) este orice număr al intervalului [ A, b].
Să găsim probabilitatea de a lovi segmentul uniform distribuit [ A,
b] variabilă aleatorie Xîn interval  , complet întins înăuntru [ A,
b]. Ținând cont de forma cunoscută a funcției de distribuție, obținem:
, complet întins înăuntru [ A,
b]. Ținând cont de forma cunoscută a funcției de distribuție, obținem:
Astfel, probabilitatea de a lovi segmentul uniform distribuit [ A,
b] variabilă aleatorie Xîn interval  , complet întins înăuntru [ A,
b], nu depinde de poziția acestui interval, ci depinde doar de lungimea acestuia și este direct proporțional cu această lungime.
, complet întins înăuntru [ A,
b], nu depinde de poziția acestui interval, ci depinde doar de lungimea acestuia și este direct proporțional cu această lungime.
Exemplu. Intervalul cu autobuzul este de 10 minute. Care este probabilitatea ca un pasager care sosește într-o stație de autobuz să aștepte mai puțin de 3 minute pentru autobuz? Care este timpul mediu de așteptare pentru un autobuz?
Distributie normala
Această distribuție este cel mai des întâlnită în practică și joacă un rol excepțional în teoria probabilităților și statistica matematică și aplicațiile lor, deoarece atât de multe variabile aleatoare din științe naturale, economie, psihologie, sociologie, științe militare și așa mai departe au o astfel de distribuție. Această distribuție este legea limitativă, care este abordată (în anumite condiții naturale) de multe alte legi ale distribuției. Cu ajutorul legii distribuției normale sunt descrise și fenomene care sunt supuse acțiunii multor factori aleatori independenți de orice natură și oricărei legi a distribuției lor. Să trecem la definiții.
O variabilă aleatoare continuă se numește distribuită legea normală (sau legea gaussiană), dacă densitatea sa de probabilitate are forma:
 ,
,
unde sunt numerele Ași σ (σ>0 ) sunt parametrii acestei distribuții.
După cum sa menționat deja, legea Gauss a distribuției variabilelor aleatoare are numeroase aplicații. Conform acestei legi, sunt distribuite erorile de măsurare prin instrumente, abaterea de la centrul țintei în timpul tragerii, dimensiunile pieselor fabricate, greutatea și înălțimea oamenilor, precipitațiile anuale, numărul de nou-născuți și multe altele.
Formula de mai sus pentru densitatea de probabilitate a unei variabile aleatoare distribuite normal conține, după cum sa spus, doi parametri Ași σ , și, prin urmare, definește o familie de funcții care variază în funcție de valorile acestor parametri. Dacă aplicăm metodele obișnuite de analiză matematică a studiului funcțiilor și a graficului la densitatea de probabilitate a unei distribuții normale, putem trage următoarele concluzii.

sunt punctele sale de inflexiune.
Pe baza informațiilor primite, construim un grafic al densității de probabilitate f(X) distribuție normală (se numește curba Gauss - figură).

Să aflăm cum afectează modificarea parametrilor Ași σ pe forma curbei Gauss. Este evident (acest lucru se poate observa din formula pentru densitatea distribuției normale) că modificarea parametrului A nu schimbă forma curbei, ci doar duce la deplasarea acesteia la dreapta sau la stânga de-a lungul axei X. Dependență σ mai dificil. Din studiul de mai sus se poate observa cum valoarea maximului si coordonatele punctelor de inflexie depind de parametru σ . În plus, trebuie luat în considerare faptul că pentru orice parametri Ași σ aria de sub curba Gauss rămâne egală cu 1 (aceasta este o proprietate generală a densității de probabilitate). Din cele spuse rezultă că cu o creștere a parametrului σ curba devine mai plată și se întinde de-a lungul axei X. Figura prezintă curbele gaussiene pentru diferite valori ale parametrului σ (σ 1 < σ< σ 2 ) și aceeași valoare a parametrului A.

Aflați semnificația probabilistică a parametrilor Ași σ
distributie normala. Deja din simetria curbei Gauss față de linia verticală care trece prin număr A pe osie X este clar că valoarea medie (adică așteptarea matematică M(X)) a unei variabile aleatoare distribuite normal este egal cu A. Din aceleași motive, și modul și mediana trebuie să fie egale cu numărul a. Calculele exacte conform formulelor corespunzătoare confirmă acest lucru. Dacă scriem expresia de mai sus pentru f(X)
înlocuiți în formulă varianța  , apoi după calculul (destul de dificil) al integralei, obținem în răspuns numărul σ
2
. Astfel, pentru o variabilă aleatoare X distribuite conform legii normale, s-au obţinut următoarele caracteristici numerice principale:
, apoi după calculul (destul de dificil) al integralei, obținem în răspuns numărul σ
2
. Astfel, pentru o variabilă aleatoare X distribuite conform legii normale, s-au obţinut următoarele caracteristici numerice principale:
Prin urmare, sensul probabilistic al parametrilor distribuției normale Ași σ Următorul. Dacă r.v. XAși σ A σ.
Să găsim acum funcția de distribuție F(X)
pentru o variabilă aleatoare X, distribuit conform legii normale, folosind expresia de mai sus pentru densitatea de probabilitate f(X)
si formula  . La înlocuire f(X)
obţinem o integrală „neluată”. Tot ce se poate face pentru a simplifica expresia pentru F(X),
aceasta este reprezentarea acestei funcții sub forma:
. La înlocuire f(X)
obţinem o integrală „neluată”. Tot ce se poate face pentru a simplifica expresia pentru F(X),
aceasta este reprezentarea acestei funcții sub forma:
 ,
,
Unde F(x)- asa numitul Funcția Laplace, care arată ca
 .
.
Integrala în termenii căreia este exprimată funcția Laplace este, de asemenea, neluată (dar pentru fiecare X această integrală poate fi calculată aproximativ cu orice precizie predeterminată). Cu toate acestea, nu este necesar să se calculeze, deoarece la sfârșitul oricărui manual despre teoria probabilității există un tabel pentru determinarea valorilor funcției F(x) la o valoare dată X. În cele ce urmează, vom avea nevoie de proprietatea ciudată a funcției Laplace: F(−x)=−F(x) pentru toate numerele X.
Să găsim acum probabilitatea ca un r.v distribuit normal. X va lua o valoare din intervalul numeric dat (α, β) . Din proprietățile generale ale funcției de distribuție Р(α< X< β)= F(β) − F(α) . Înlocuind α și β în expresia de mai sus pentru F(X) , primim
 .
.
După cum sa menționat mai sus, dacă r.v. X distribuite normal cu parametri Ași σ , atunci valoarea sa medie este egală cu A, iar abaterea standard este egală cu σ. De aceea in medie abaterea valorilor acestui r.v. când se testează din număr A egală σ. Dar aceasta este abaterea medie. Prin urmare, sunt posibile și abateri mai mari. Aflăm cât de posibil aceste sau acele abateri de la valoarea medie. Să găsim probabilitatea ca valoarea unei variabile aleatoare să fie distribuită conform legii normale X abate de la media sa M(X)=a mai mic decât un număr δ, adică R(| X− A|<δ ) : . În acest fel,
 .
.
Înlocuind în această egalitate δ=3σ, obținem probabilitatea ca valoarea r.v. X(într-o singură încercare) se va abate de la medie de mai puțin de trei ori σ (cu o abatere medie, după cum ne amintim, egală cu σ ): (sens F(3) luate din tabelul de valori ale funcției Laplace). Este aproape 1 ! Apoi probabilitatea evenimentului opus (ca valoarea să se abate cu cel puțin 3σ) este egal cu 1 −0.997=0.003 , care este foarte aproape de 0 . Prin urmare, acest eveniment este „aproape imposibil” − se întâmplă foarte rar (în medie 3 timpul a expirat 1000 ). Acest raționament este rațiunea pentru binecunoscuta „regulă a trei sigma”.
Regula trei sigma. Variabilă aleatoare distribuită în mod normal într-un singur test practic nu se abate de la media sa mai mult decât 3σ.
Încă o dată, subliniem că vorbim despre un singur test. Dacă există multe încercări ale unei variabile aleatoare, atunci este foarte posibil ca unele dintre valorile acesteia să se deplaseze mai departe de medie decât 3σ. Acest lucru confirmă următoarele
Exemplu. Care este probabilitatea ca după 100 de încercări ale unei variabile aleatoare distribuite normal X cel puțin una dintre valorile sale se va abate de la medie cu mai mult de trei ori abaterea standard? Ce zici de 1000 de încercări?
Soluţie. Lasă evenimentul DARînseamnă că atunci când se testează o variabilă aleatoare X valoarea sa a deviat de la medie cu mai mult de 3σ. După cum tocmai s-a aflat, probabilitatea acestui eveniment p=P(A)=0,003. Au fost efectuate 100 de astfel de teste. Trebuie să găsim probabilitatea ca evenimentul DAR s-a întâmplat macar ori, adica vin de la 1 inainte de 100 o singura data. Aceasta este o problemă tipică a schemei Bernoulli cu parametri n=100 (număr de studii independente), p=0,003(probabilitatea evenimentului DARîntr-un singur test) q=1− p=0.997 . Am vrut să găsesc R 100 (1≤ k≤100) . În acest caz, desigur, este mai ușor să găsiți mai întâi probabilitatea evenimentului opus R 100 (0) − probabilitatea ca evenimentul DAR nu sa întâmplat niciodată (adică s-a întâmplat de 0 ori). Luând în considerare legătura dintre probabilitățile evenimentului în sine și opusul său, obținem:
Nu atât de puțin. Se poate întâmpla foarte bine (apare în medie la fiecare a patra astfel de serie de teste). La 1000 teste după aceeași schemă, se poate obține că probabilitatea a cel puțin o abatere este mai mare decât 3σ, este egal cu: . Deci, este sigur să așteptați cel puțin o astfel de abatere.
Exemplu. Înălțimea bărbaților dintr-o anumită grupă de vârstă este în mod normal distribuită cu așteptări matematice A, și abaterea standard σ . Ce proporție de costume k-a-a creștere ar trebui inclusă în producția totală pentru o anumită grupă de vârstă dacă k-a-a crestere este determinata de urmatoarele limite:
1 creştere : 158 − 164 cm 2 creştere : 164 - 170 cm 3 creştere : 170 - 176 cm 4 creştere : 176 - 182 cm
Soluţie. Să rezolvăm problema cu următoarele valori ale parametrilor: a=178,σ=6,k=3
. Lasă r.v. X
−
înălțimea unui bărbat selectat aleatoriu (este distribuită în funcție de condiția în mod normal cu parametrii dați). Găsiți probabilitatea de care va avea nevoie un bărbat ales aleatoriu 3
creşterea. Folosind ciudățenia funcției Laplace F(x)și un tabel cu valorile sale: P(170
Distribuția probabilității unei variabile aleatoare continue X, care preia toate valorile din interval , se numește uniformă, dacă densitatea sa de probabilitate pe acest segment este constantă, iar în exterior este egală cu zero. Astfel, densitatea de probabilitate a unei variabile aleatoare continue X, distribuit uniform pe segment , se pare ca:

Să definim valorea estimata, dispersie iar pentru o variabilă aleatoare cu o distribuţie uniformă.
, ![]() ,
, ![]() .
.
Exemplu. Toate valorile unei variabile aleatoare distribuite uniform se află pe segment . Aflați probabilitatea ca o variabilă aleatoare să cadă în interval (3;5) .
a=2, b=8,  .
.
Distribuție binomială
Lasă-l să fie produs n teste și probabilitatea de apariție a unui eveniment Aîn fiecare test este pși nu depinde de rezultatul altor studii (procese independente). Deoarece probabilitatea producerii unui eveniment Aîntr-un singur test este p, atunci probabilitatea neapariției sale este egală cu q=1-p.
Lasă evenimentul A a venit în nîncercări m o singura data. Acest eveniment complex poate fi scris ca un produs:
![]() .
.
Apoi probabilitatea ca n eveniment de testare A va veni m ori , se calculează prin formula:
![]() sau
sau ![]() (1)
(1)
Formula (1) se numește formula Bernoulli.
Lăsa X este o variabilă aleatorie egală cu numărul de apariții ale evenimentului Aîn n teste, care iau valori cu probabilități:
Legea de distribuție rezultată a unei variabile aleatoare se numește legea distribuției binomiale.
| X | m | n | ||||
| P |
Valorea estimata, dispersieși deviație standard variabilele aleatoare distribuite conform legii binomiale sunt determinate de formulele:
, , .
Exemplu. Trei focuri sunt trase în țintă, iar probabilitatea de a lovi fiecare lovitură este de 0,8. Considerăm o variabilă aleatoare X- numărul de lovituri pe țintă. Găsiți legea distribuției, așteptările matematice, varianța și abaterea standard.
p=0,8, q=0,2, n=3, ![]() , ,
, , ![]() .
.
![]() - probabilitatea de 0 lovituri;
- probabilitatea de 0 lovituri;
Probabilitatea unei lovituri;
Probabilitatea a două lovituri;
![]() este probabilitatea a trei lovituri.
este probabilitatea a trei lovituri.
Obținem legea distribuției:
| X | ||||
| P | 0,008 | 0,096 | 0,384 | 0,512 |
Sarcini
1. O monedă este aruncată de 7 ori. Găsiți probabilitatea ca acesta să cadă cu susul în jos de 4 ori.
2. O monedă este aruncată de 8 ori. Găsiți probabilitatea ca stema să apară de cel mult trei ori.
3. Probabilitatea de a lovi ținta la tragerea cu pistolul p=0,6. Găsiți așteptarea matematică a numărului total de lovituri dacă sunt trase 10 focuri.
4. Găsiți așteptarea matematică a numărului de bilete de loterie care vor câștiga dacă sunt achiziționate 20 de bilete, iar probabilitatea de a câștiga pentru un bilet este de 0,3.
Funcția de distribuție în acest caz, conform (5.7), va lua forma:
unde: m este așteptarea matematică, s este abaterea standard.
Distribuția normală este numită și Gauss după matematicianul german Gauss. Faptul că o variabilă aleatoare are o distribuţie normală cu parametrii: m,, se notează astfel: N (m, s), unde: m =a =M ;
Destul de des, în formule, așteptarea matematică este notă cu A . Dacă o variabilă aleatoare este distribuită conform legii N(0,1), atunci se numește valoare normală normalizată sau standardizată. Funcția de distribuție a acesteia are forma:
|
|
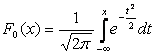 .
.Graficul densității distribuției normale, care se numește curbă normală sau curba Gauss, este prezentat în Fig. 5.4.

Orez. 5.4. Densitatea normală de distribuție
Determinarea caracteristicilor numerice ale unei variabile aleatoare prin densitatea acesteia este considerată pe un exemplu.
Exemplul 6.
O variabilă aleatoare continuă este dată de densitatea distribuției: ![]() .
.
Determinați tipul de distribuție, găsiți așteptarea matematică M(X) și varianța D(X).
Comparând densitatea distribuției dată cu (5.16), putem concluziona că legea distribuției normale cu m =4 este dată. Prin urmare, așteptarea matematică M(X)=4, varianța D(X)=9.
Abaterea standard s=3.
Funcția Laplace, care are forma:
|
|
 ,
,este legată de funcția de distribuție normală (5.17), prin relația:
F 0 (x) \u003d F (x) + 0,5.
Funcția Laplace este impară.
Ф(-x)=-Ф(x).
Valorile funcției Laplace Ф(х) sunt tabulate și luate din tabel în funcție de valoarea lui x (vezi Anexa 1).
Distribuția normală a unei variabile aleatoare continue joacă un rol important în teoria probabilității și în descrierea realității; este foarte răspândită în fenomenele naturale aleatorii. În practică, de foarte multe ori există variabile aleatoare care se formează tocmai ca rezultat al însumării mai multor termeni aleatori. În special, analiza erorilor de măsurare arată că acestea sunt suma diferitelor tipuri de erori. Practica arată că distribuția probabilităților de eroare de măsurare este apropiată de legea normală.
Folosind funcția Laplace, se pot rezolva probleme de calcul a probabilității de a se încadra într-un interval dat și a unei abateri date a unei variabile aleatoare normale.
Această problemă a fost mult timp studiată în detaliu, iar metoda coordonatelor polare, propusă de George Box, Mervyn Muller și George Marsaglia în 1958, a fost cea mai utilizată. Această metodă vă permite să obțineți o pereche de variabile aleatoare independente distribuite normal cu așteptări matematice 0 și varianță 1, după cum urmează:
Unde Z 0 și Z 1 sunt valorile dorite, s \u003d u 2 + v 2 și u și v sunt variabile aleatoare distribuite uniform pe segmentul (-1, 1), selectate astfel încât condiția 0< s < 1.
Mulți folosesc aceste formule fără să se gândească și mulți nici măcar nu bănuiesc existența lor, deoarece folosesc implementări gata făcute. Dar sunt oameni care au întrebări: „De unde a venit această formulă? Și de ce obțineți o pereche de valori deodată? În cele ce urmează, voi încerca să dau un răspuns clar la aceste întrebări.
Pentru început, permiteți-mi să vă reamintesc care sunt densitatea de probabilitate, funcția de distribuție a unei variabile aleatoare și funcția inversă. Să presupunem că există o variabilă aleatoare, a cărei distribuție este dată de funcția de densitate f(x), care are următoarea formă:

Aceasta înseamnă că probabilitatea ca valoarea acestei variabile aleatoare să fie în intervalul (A, B) este egală cu aria zonei umbrite. Și, în consecință, aria întregii zone umbrite trebuie să fie egală cu unitatea, deoarece, în orice caz, valoarea variabilei aleatoare va intra în domeniul funcției f.
Funcția de distribuție a unei variabile aleatoare este o integrală a funcției de densitate. Și în acest caz, forma sa aproximativă va fi după cum urmează:

Aici sensul este că valoarea variabilei aleatoare va fi mai mică decât A cu probabilitatea B. Și, ca urmare, funcția nu scade niciodată, iar valorile sale se află în intervalul .
O funcție inversă este o funcție care returnează argumentul funcției inițiale dacă treceți valoarea funcției originale în ea. De exemplu, pentru funcția x 2 inversul va fi funcția de extracție a rădăcinii, pentru sin (x) este arcsin (x), etc.
Deoarece majoritatea generatoarelor de numere pseudo-aleatoare dau doar o distribuție uniformă la ieșire, adesea devine necesară convertirea acesteia în alta. În acest caz, la un Gaussian normal:

Baza tuturor metodelor de transformare a unei distribuții uniforme în orice altă distribuție este metoda transformării inverse. Funcționează după cum urmează. Se găsește o funcție care este inversă funcției distribuției necesare și o variabilă aleatoare distribuită uniform pe segmentul (0, 1) îi este transmisă ca argument. La ieșire, obținem o valoare cu distribuția necesară. Pentru claritate, iată următoarea imagine.

Astfel, un segment uniform este, parcă, mânjit în conformitate cu noua distribuție, fiind proiectat pe o altă axă printr-o funcție inversă. Dar problema este că integrala densității distribuției Gauss nu este ușor de calculat, așa că oamenii de știință de mai sus au trebuit să trișeze.
Există o distribuție chi-pătrat (distribuția Pearson), care este distribuția sumei pătratelor a k variabile aleatoare normale independente. Și în cazul în care k = 2, această distribuție este exponențială.

Aceasta înseamnă că, dacă un punct dintr-un sistem de coordonate dreptunghiular are coordonate aleatoare X și Y distribuite normal, atunci după conversia acestor coordonate în sistemul polar (r, θ), pătratul razei (distanța de la origine la punct) va fi distribuit exponențial, întrucât pătratul razei este suma pătratelor coordonatelor (conform legii pitagoreice). Densitatea de distribuție a unor astfel de puncte pe plan va arăta astfel:


Deoarece este egal în toate direcțiile, unghiul θ va avea o distribuție uniformă în intervalul de la 0 la 2π. Este adevărat și invers: dacă specificați un punct în sistemul de coordonate polar folosind două variabile aleatoare independente (unghiul distribuit uniform și raza distribuită exponențial), atunci coordonatele dreptunghiulare ale acestui punct vor fi variabile aleatoare normale independente. Și deja este mult mai ușor să obțineți o distribuție exponențială dintr-una uniformă, folosind aceeași metodă de transformare inversă. Aceasta este esența metodei polare Box-Muller.
Acum să luăm formulele.
![]() (1)
(1)
Pentru a obține r și θ, este necesar să se genereze două variabile aleatoare distribuite uniform pe segmentul (0, 1) (să le numim u și v), a căror distribuție (să zicem v) trebuie convertită în exponențială în obțineți raza. Funcția de distribuție exponențială arată astfel:
Funcția sa inversă:
![]()
Deoarece distribuția uniformă este simetrică, transformarea va funcționa similar cu funcția
![]()
Din formula de distribuție chi-pătrat rezultă că λ = 0,5. Inlocuim λ, v in aceasta functie si obtinem patratul razei si apoi raza in sine:

Obținem unghiul prin întinderea segmentului unitar la 2π:
Acum înlocuim r și θ în formulele (1) și obținem:
 (2)
(2)
Aceste formule sunt gata de utilizare. X și Y vor fi independente și distribuite normal cu o varianță de 1 și o medie de 0. Pentru a obține o distribuție cu alte caracteristici, este suficient să înmulțiți rezultatul funcției cu abaterea standard și să adăugați media.
Dar este posibil să scăpați de funcțiile trigonometrice prin specificarea unghiului nu direct, ci indirect prin coordonatele dreptunghiulare ale unui punct aleatoriu dintr-un cerc. Apoi, prin aceste coordonate, va fi posibil să se calculeze lungimea vectorului rază, iar apoi să se găsească cosinusul și sinusul împărțind x și respectiv y la acesta. Cum și de ce funcționează?
Alegem un punct aleatoriu din distribuit uniform în cercul de rază unitară și notăm pătratul lungimii vectorului de rază a acestui punct cu litera s:

Alegerea se face prin atribuirea aleatoare de coordonate dreptunghiulare x și y distribuite uniform în intervalul (-1, 1), și eliminând punctele care nu aparțin cercului, precum și punctul central la care este unghiul vectorului rază. nedefinit. Adică condiția 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Obținem formulele, ca la începutul articolului. Dezavantajul acestei metode este respingerea punctelor care nu sunt incluse în cerc. Adică folosind doar 78,5% din variabilele aleatoare generate. Pe computerele mai vechi, lipsa funcțiilor trigonometrice era încă un mare avantaj. Acum, când o instrucțiune de procesor calculează simultan sinus și cosinus într-o clipă, cred că aceste metode pot concura în continuare.
Personal, mai am două întrebări:
- De ce valoarea lui s este distribuită uniform?
- De ce este distribuită exponențial suma pătratelor a două variabile aleatoare normale?

Dacă se face o transformare similară pentru o variabilă aleatorie normală, atunci funcția de densitate a pătratului său se va dovedi a fi similară cu o hiperbolă. Și adăugarea a două pătrate de variabile aleatoare normale este deja un proces mult mai complex asociat cu dubla integrare. Iar faptul că rezultatul va fi o distribuție exponențială, personal, îmi rămâne să o verific cu o metodă practică sau să o accept ca pe o axiomă. Și pentru cei interesați, vă sugerez să vă familiarizați cu subiectul mai îndeaproape, extragând cunoștințe din aceste cărți:
- Wentzel E.S. Teoria probabilității
- Knut D.E. Arta programarii Volumul 2
În concluzie, voi da un exemplu de implementare a unui generator de numere aleatoare distribuite normal în JavaScript:
Funcția Gauss() ( var gata = fals; var secundă = 0.0; this.next = function(mean, dev) ( mean = mean == nedefinit ? 0.0: mean; dev = dev == nedefinit ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1,0; s = u * u + v * v; ) în timp ce (s > 1,0 || s == 0,0); var r = Math.sqrt(-2,0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = nou Gauss(); // creează un obiect a = g.next(); // generează o pereche de valori și obținem prima b = g.next(); // obținem al doilea c = g.next(); // generează din nou o pereche de valori și obținem prima
Parametrii mean (așteptările matematice) și dev (deviația standard) sunt opționali. Vă atrag atenția că logaritmul este natural.
