Pearson korrelációs teszt. A regressziós és korrelációs paraméterek statisztikai jelentősége
Bevezetés. 2
1. A regressziós és korrelációs együtthatók jelentőségének felmérése Student-féle f-próba segítségével. 3
2. Regressziós és korrelációs együtthatók szignifikanciájának kiszámítása Student-féle f-próbával. 6
Következtetés. 15
A regressziós egyenlet felépítése után ellenőrizni kell a jelentőségét: speciális kritériumok segítségével határozza meg, hogy a regressziós egyenlettel kifejezett függőség véletlenszerű-e, i. használható-e előrejelzési célokra és faktoranalízisre. A statisztikában módszereket dolgoztak ki a regressziós együtthatók szignifikanciájának szigorú tesztelésére varianciaanalízissel és speciális kritériumok kiszámításával (például F-próba). A laza teszt elvégezhető az átlagos relatív lineáris eltérés (e) kiszámításával, amelyet a közelítés átlagos hibájának nevezünk:
Térjünk most tovább a bj regressziós együtthatók szignifikanciájának felmérésére és egy konfidenciaintervallum felépítésére a Ru regressziós modell paramétereihez (J=l,2,..., p).
5. blokk - a regressziós együtthatók szignifikanciájának értékelése a Student-féle ^-teszt értéke alapján. A számított ta értékeket összehasonlítjuk a megengedett értékkel
5. blokk - a regressziós együtthatók szignifikanciájának értékelése a ^-kritérium értéke alapján. A t0n számított értékeit összehasonlítjuk a megengedett 4,/ értékkel, amelyet a t-eloszlási táblázatokból határozunk meg egy adott hibavalószínűség (a) és a szabadságfokok száma (/) esetén.
A teljes modell szignifikancia ellenőrzése mellett szükséges a regressziós együtthatók szignifikanciájának tesztelése is a Student /-teszt segítségével. A br regressziós együttható minimális értékének meg kell felelnie a bifob- ^t feltételnek, ahol bi a regressziós egyenlet együtthatójának értéke természetes skálán az i-edik tényezőkarakterisztikára; ah. - az egyes együtthatók átlagos négyzethibája. a D együtthatók összehasonlíthatatlansága jelentőségükben;
A további statisztikai elemzés a regressziós együtthatók szignifikanciájának tesztelésére vonatkozik. Ehhez megtaláljuk a regressziós együtthatók ^-kritériumának értékét. Összehasonlításuk eredményeként a legkisebb ^-kritérium kerül meghatározásra. Azt a tényezőt, amelynek együtthatója megfelel a legkisebb ^-kritériumnak, kizárjuk a további elemzésből.
A regressziós és korrelációs együtthatók statisztikai szignifikanciájának értékeléséhez a Student-féle t-próbát és az egyes mutatókra vonatkozó konfidenciaintervallumokat számítjuk ki. A mutatók véletlenszerűségére vonatkozóan hipotézist állítanak fel, azaz. a nullától való jelentéktelen különbségükről. A regressziós és korrelációs együtthatók jelentőségének felmérése Student-féle f-próbával úgy történik, hogy az értékeket összehasonlítjuk a véletlen hiba nagyságával:
A tiszta regressziós együtthatók jelentőségének felmérése Student-féle /-teszttel az érték kiszámításától függ.
A munka minősége az adott munka jellemzője, amely tükrözi annak összetettségének, intenzitásának (intenzitásának), feltételeinek és gazdasági fejlődési jelentőségének mértékét. K.t. tarifarendszeren keresztül mérik, amely lehetővé teszi a bérek differenciálását a képzettségi szint (munka összetettsége), a feltételek, a munka súlyossága és intenzitása, valamint az egyes iparágak és termelések, régiók, területek fejlődése szempontjából fontosak szerint. az ország gazdasága. K.t. a munkások bérében fejeződik ki, amelyek a munkaerő-kereslet és -kínálat (sajátos munkafajták) hatására alakulnak ki a munkaerőpiacon. K.t. - összetett szerkezetű
A projekt egyéni gazdasági, társadalmi és környezeti következményeinek relatív fontosságának kapott pontszámai a továbbiakban alapot adnak az alternatív projektek és azok lehetőségeinek összehasonlítására az Ek projekt „társadalmi és környezeti-gazdasági hatékonyság komplex pontozásos dimenzió nélküli kritériuma” felhasználásával. (átlagos szignifikancia pontszámokban) a képlet segítségével
Az ágazaton belüli szabályozás biztosítja az adott iparágban dolgozók bérkülönbségét az adott iparágban az egyes termelési típusok fontosságától, a komplexitástól és a munkakörülményektől, valamint az alkalmazott javadalmazási formáktól függően.
A vizsgált vállalkozásnak az egyes mutatók jelentőségének figyelembe vétele nélküli, standard vállalkozáshoz viszonyított minősítése összehasonlító jellegű. Több vállalkozás minősítésének összehasonlításakor a legmagasabb minősítést az a vállalkozás kapja, amelyik a kapott összehasonlító értékelés minimális értékével rendelkezik.
Egy termék minőségének, mint hasznosságának mérőszámának megértése gyakorlatilag fontos kérdést vet fel a mérésével kapcsolatban. Megoldása az egyes tulajdonságok jelentőségének tanulmányozásával valósul meg egy adott igény kielégítésében. Még ugyanazon tulajdonság jelentősége is eltérő lehet a termék fogyasztási körülményeitől függően. Következésképpen egy termék hasznossága különböző felhasználási körülmények között eltérő.
A munka második szakasza a statisztikai adatok tanulmányozása és az indikátorok kapcsolatának és kölcsönhatásának azonosítása, az egyes tényezők jelentőségének és az általános mutatók változásának okainak meghatározása.
Az összes figyelembe vett mutatót úgy egyesítik egybe, hogy az eredmény a vállalkozás tevékenységének összes elemzett aspektusának átfogó értékelése legyen, figyelembe véve a tevékenység feltételeit, figyelembe véve az egyes mutatók jelentőségének mértékét a különböző típusú vállalkozások számára. befektetők:
A regressziós együtthatók a tényezők teljesítménymutatóra gyakorolt hatásának intenzitását mutatják. Ha elvégezzük a faktormutatók előzetes szabványosítását, akkor b0 egyenlő az effektív mutató átlagértékével az aggregátumban. A b, b2 ..... bl együtthatók azt mutatják, hogy az effektív mutató szintje hány egységgel tér el az átlagos értékétől, ha a faktormutató értékei egy szórással térnek el a nulla átlagától. Így a regressziós együtthatók jellemzik az egyes tényezők szignifikancia fokát a teljesítménymutató szintjének növelésére. A regressziós együtthatók fajlagos értékeit tapasztalati adatokból határozzuk meg a legkisebb négyzetek módszerével (normál egyenletrendszerek megoldása eredményeként).
2. A regressziós és korrelációs együtthatók szignifikanciájának kiszámítása Student-féle f-próbával
Tekintsük a többtényezős összefüggések lineáris formáját nemcsak a legegyszerűbbnek, hanem a PC-k számára készült alkalmazási szoftvercsomagok által biztosított formának is. Ha egy egyedi tényező és a kapott attribútum közötti kapcsolat nem lineáris, akkor az egyenletet a faktorattribútum értékének cseréjével vagy átalakításával linearizáljuk.
A többváltozós regressziós egyenlet általános formája:
ahol k a tényezőjellemzők száma.
A (8.32) egyenlet paramétereinek kiszámításához szükséges legkisebb négyzetek egyenletrendszerének egyszerűsítése érdekében általában bevezetik az összes jellemző egyedi értékének eltéréseit ezen jellemzők átlagos értékétől.
Kapunk egy k legkisebb négyzetek egyenletrendszerét:

Ezt a rendszert megoldva megkapjuk a feltételesen tiszta regressziós együtthatók értékeit b. Az egyenlet szabad tagját a képlet számítja ki
A „feltételesen tiszta regressziós együttható” kifejezés azt jelenti, hogy a bj értékek mindegyike a kapott jellemző összesített átlagos eltérését méri az átlagos értékétől, ha egy adott xj tényező mértékegységével eltér az átlagértékétől, és feltéve, hogy a regressziós egyenletben szereplő egyéb tényezők, átlagos értékeken rögzítettek, nem változnak, nem változnak.
Így a páros regressziós együtthatóval ellentétben a feltételes tiszta regressziós együttható egy faktor befolyását méri, elvonatkoztatva e tényező változásának más tényezők változásával való kapcsolatától. Ha a regressziós egyenletbe be lehetne vonni az eredményül kapott jellemző változását befolyásoló összes tényezőt, akkor a bj értékei. a tényezők tiszta befolyásának mérőszámainak tekinthetők. De mivel valóban lehetetlen minden tényezőt belefoglalni az egyenletbe, ezért a bj együtthatók. nem mentes az egyenletben nem szereplő tényezők befolyásának keveredésétől.
Lehetetlen az összes tényezőt belefoglalni a regressziós egyenletbe három ok egyike miatt, vagy az összeset egyszerre, mivel:
1) egyes tényezők ismeretlenek lehetnek a modern tudomány számára, bármely folyamat ismerete mindig hiányos;
2) néhány ismert elméleti tényezőről nincs információ, vagy az nem megbízható;
3) a vizsgált sokaság (minta) mérete korlátozott, ami lehetővé teszi, hogy a regressziós egyenletben korlátozott számú tényező szerepeljen.
Feltételes tiszta regressziós együtthatók bj. elnevezett számok különböző mértékegységekben kifejezve, és ezért összehasonlíthatatlanok egymással. Ahhoz, hogy ezeket összehasonlítható relatív mutatókká alakítsuk át, ugyanazt a transzformációt alkalmazzuk, mint a páronkénti korrelációs együttható meghatározásához. A kapott értéket standardizált regressziós együtthatónak vagy a-együtthatónak nevezzük.
Az xj faktor együtthatója határozza meg az xj faktor változásának a kapott y jellemző változására gyakorolt hatásának mértékét, elvonatkoztatva a regressziós egyenletben szereplő egyéb tényezők egyidejű változásától.
Célszerű a feltételesen tiszta regresszió együtthatóit a kapcsolat, rugalmassági együtthatók relatív összehasonlítható mutatói formájában kifejezni:
Az xj faktor rugalmassági együtthatója azt mondja, hogy ha egy adott tényező értéke 1%-kal eltér az átlagos értékétől, és elvonatkoztatva az egyenletben szereplő egyéb tényezők egyidejű eltérésétől, akkor a kapott jellemző ej százalékkal tér el az átlagos értékétől. y-tól. A rugalmassági együtthatókat gyakrabban a dinamika szempontjából értelmezik és alkalmazzák: az x tényező átlagos értékének 1%-os növekedésével a kapott karakterisztika az átlagos értékének e, százalékával növekszik.
Tekintsük a többtényezős regressziós egyenlet kiszámítását és értelmezését ugyanazon 16 farmon példaként (8.1. táblázat). Az effektív előjel a bruttó jövedelem szintje és három, azt befolyásoló tényező a táblázatban. 8.7.
Emlékezzünk még egyszer arra, hogy a megbízható és kellően pontos korrelációs mutatók eléréséhez nagyobb populációra van szükség.
8.7. táblázat
A bruttó jövedelem szintje és tényezői
| Farm számok |
Bruttó jövedelem, rub./ra |
Munkaköltség, embernap/ha x1 |
szántóterület részesedése, |
1 tehénre jutó tejhozam, |
8.8. táblázat A regressziós egyenlet indikátorai
| Függő változó: y |
|||||
| Regressziós együttható |
|||||
| Állandó-240.112905 |
|||||
| Std. hiba az est. = 79,243276 |
|||||
A megoldás a PC-hez készült „Microstat” programmal történt. Íme a táblázatok a nyomtatásból: táblázat. A 8.7 az összes jellemző átlagos értékeit és szórását adja meg. asztal A 8.8 regressziós együtthatókat és azok valószínűségi értékelését tartalmazza:
az első „var” oszlop - változók, azaz tényezők; a második oszlop „regressziós együttható” - feltételesen tiszta regressziós együtthatók bj; harmadik oszlop „std. errr" - átlagos hibák a regressziós együttható becsléseiben; negyedik oszlop - a Student-féle t-teszt értékei 12 variációs szabadságfokkal; ötödik oszlop „prob” - a nullhipotézis valószínűsége a regressziós együtthatókhoz képest;
hatodik oszlop „részleges r2” - részleges determinációs együtthatók. A 3-6. oszlopban szereplő mutatók kiszámításának tartalmát és módszertanát a 8. fejezet tárgyalja tovább. Az „állandó” az a regressziós egyenlet szabad tagja; "Std. becslés hibája.” - az effektív jellemző regressziós egyenlet segítségével történő becslésének átlagos négyzetes hibája. A többszörös regressziós egyenletet kaptuk:
y = 2,26x1 - 4,31x2 + 0,166x3 - 240.
Ez azt jelenti, hogy az 1 hektár termőföldre jutó bruttó jövedelem összege átlagosan 2,26 rubelrel nőtt. a munkaerőköltség 1 óra/ha növekedésével; átlagosan 4,31 rubellel csökkent. a szántó részaránya a termőföldön belül 1%-kal nőtt, és 0,166 rubel nőtt. tehenenkénti tejhozam 1 kg-os növekedésével. A szabad tag negatív értéke teljesen természetes, és amint azt a 8.2. bekezdésben már megjegyeztük, az effektív előjele, hogy a bruttó jövedelem jóval azelőtt nullává válik, hogy a tényezők elérnék a nulla értéket, ami a termelésben lehetetlen.
Az x^-re vonatkozó együttható negatív értéke a vizsgált gazdaságok gazdaságában jelentős bajt jelez, ahol a növénytermesztés veszteséges, és csak az állattenyésztés jövedelmező. A racionális gazdálkodási módok és az összes ágazat termékeinek normál (egyensúlyi vagy ahhoz közeli) árai mellett a bevételnek nem csökkennie, hanem a termőföld legtermékenyebb részarányának - a szántónak - növekedésével kell növekednie.
A táblázat utolsó előtti két sorának adatai alapján. 8.7 és táblázat. 8.8 A (8.34) és a (8.35) képlet alapján kiszámítjuk a p-együtthatókat és a rugalmassági együtthatókat.
Mind a jövedelemszint ingadozását, mind annak lehetséges dinamikájának változását a legerősebben az x3 - a tehenek termelékenysége -, a leggyengébb pedig az x2 - a szántóterület aránya befolyásolja. A továbbiakban a P2/ értékeket használjuk (8.9. táblázat);
8.9. táblázat A tényezők összehasonlító hatása a jövedelemszintre
| Tényezők xj |
|||

Tehát azt kaptuk, hogy az xj tényező a-együtthatója ennek a tényezőnek a rugalmassági együtthatójára vonatkozik, mivel a faktor variációs együtthatója a kapott jellemző variációs együtthatójára vonatkozik. Mivel, mint a táblázat utolsó sorából is látszik. 8.7, az összes tényező variációs együtthatója kisebb, mint a kapott jellemző variációs együtthatója; az összes?-együttható kisebb, mint a rugalmassági együttható.
Példaként tekintsük a páros és a feltételesen tiszta regressziós együttható kapcsolatát a -с tényezővel. Az y és x közötti kapcsolat páros lineáris egyenlete a következő:
y = 3,886x1 – 243,2
A feltételesen tiszta regressziós együttható x1-nél csak 58%-a a párosnak. A fennmaradó 42% annak tudható be, hogy az x1 variációt x2 x3 faktorok változása kíséri, ami viszont befolyásolja a kapott tulajdonságot. Az összes jellemző összefüggéseit és páronkénti regressziós együtthatóit a kapcsolatok grafikonja mutatja be (8.2. ábra).

Ha összeadjuk az x1 variáció y-ra gyakorolt közvetlen és közvetett hatásának becsléseit, azaz az összes „út” mentén párosított regressziós együtthatók szorzatát (8.2. ábra), akkor a következőt kapjuk: 2,26 + 12,55 0,166 + (-0,00128) (- 4,31) + (-0,00128) 17,00 0,166 = 4,344.
Ez az érték még nagyobb, mint az x1 pár csatolási együttható y-val. Következésképpen az x1 variáció közvetett hatása az egyenletben nem szereplő tényezőkön keresztül ellentétes, így összesen:
1 Ayvazyan S.A., Mkhitaryan V.S. Alkalmazott statisztika és az ökonometria alapjai. Tankönyv egyetemek számára. - M.: EGYSÉG, 2008, – 311 p.
2 Johnston J. Ökonometriai módszerek. - M.: Statisztika, 1980. – 282s.
3 Dougherty K. Bevezetés az ökonometriába. - M.: INFRA-M, 2004, – 354 p.
4 Dreyer N., Smith G., Alkalmazott regressziós elemzés. - M.: Pénzügy és Statisztika, 2006, – 191 p.
5 Magnus Y.R., Kartyshev P.K., Peresetsky A.A. Ökonometria. Kezdő tanfolyam.-M.: Delo, 2006, – 259 p.
6 Workshop on Econometria / Szerk. I. I. Eliseeva. - M.: Pénzügy és statisztika, 2004, – 248 p.
7 Ökonometria/Szerk. I. I. Eliseeva. - M.: Pénzügy és statisztika, 2004, – 541 p.
8 Kremer N., Putko B. Ökonometria - M.: UNITY-DANA, 200, – 281 p.
Ayvazyan S.A., Mkhitaryan V.S. Alkalmazott statisztika és az ökonometria alapjai. Tankönyv egyetemek számára. - M.: EGYSÉG, 2008, – p. 23.
Kremer N., Putko B. Ökonometria.- M.: UNITY-DANA, 200, – 64. o.
Dreyer N., Smith G., Alkalmazott regressziós elemzés. - M.: Pénzügy és Statisztika, 2006, – 57. o.
Workshop az ökonometriáról/Szerk. I. I. Eliseeva. – M.: Pénzügy és statisztika, 2004, – 172. o.
A Pearson korrelációs teszt egy olyan paraméteres statisztikai módszer, amely lehetővé teszi két mennyiségi mutató közötti lineáris kapcsolat meglétének vagy hiányának meghatározását, valamint annak közelségének és statisztikai szignifikanciájának értékelését. Más szóval, a Pearson korrelációs teszt lehetővé teszi annak meghatározását, hogy van-e lineáris kapcsolat két változó értékének változásai között. A statisztikai számításokban és következtetésekben a korrelációs együtthatót általában úgy jelölik r xy vagy Rxy.
1. A korrelációs kritérium kialakulásának története
A Pearson-féle korrelációs tesztet brit tudósokból álló csapat dolgozta ki, melynek élén Karl Pearson(1857-1936) a 19. század 90-es éveiben, két valószínűségi változó kovariancia elemzésének egyszerűsítése érdekében. Karl Pearson mellett a Pearson-féle korrelációs kritériumon is dolgoztak Francis EdgeworthÉs Raphael Weldon.
2. Mire használható a Pearson korrelációs teszt?
A Pearson korrelációs teszt segítségével meghatározható a korreláció szorossága (vagy erőssége) két kvantitatív skálán mért mutató között. További számítások segítségével azt is meghatározhatja, hogy az azonosított kapcsolat statisztikailag mennyire szignifikáns.
Például a Pearson-féle korrelációs kritérium segítségével választ kaphat arra a kérdésre, hogy van-e összefüggés a testhőmérséklet és a vér leukocitatartalma között akut légúti fertőzések esetén, a beteg testmagassága és testsúlya között, a fluorid tartalma között. ivóvíz és a fogszuvasodás előfordulása a lakosság körében.
3. A Pearson-khi-négyzet teszt alkalmazásának feltételei és korlátai
- Összehasonlítható mutatókban kell mérni mennyiségi skála(például pulzusszám, testhőmérséklet, fehérvérsejtszám 1 ml vérben, szisztolés vérnyomás).
- A Pearson korrelációs teszt segítségével csak azt tudjuk meghatározni a lineáris kapcsolat megléte és erőssége mennyiségek között. A kapcsolat egyéb jellemzőit, beleértve az irányt (közvetlen vagy fordított), a változások természetét (egyenes vagy görbe vonalú), valamint az egyik változótól való függőség jelenlétét regressziós elemzéssel határozzuk meg.
- Az összehasonlított mennyiségek számának kettőnek kell lennie. Három vagy több paraméter kapcsolatának elemzése esetén érdemes a módszert használni faktoranalízis.
- A Pearson korrelációs teszt az parametrikus, ezért használatának feltétele az normális eloszlásösszehasonlította a változókat. Ha szükséges a normáltól eltérő eloszlású mutatók korrelációs elemzése, beleértve az ordinális skálán mérteket is, akkor a Spearman-féle rangkorrelációs együtthatót kell használni.
- Világosan meg kell különböztetni a függőség és a korreláció fogalmát. A mennyiségek függése meghatározza közöttük a korreláció meglétét, de nem fordítva.
Például a gyermek magassága az életkorától függ, vagyis minél idősebb a gyerek, annál magasabb. Ha két különböző korú gyermeket veszünk, akkor nagy valószínűséggel a nagyobbik gyermek növekedése nagyobb lesz, mint a fiatalabbé. Ezt a jelenséget az ún függőség, ami ok-okozati összefüggést jelent a mutatók között. Természetesen köztük is van korrelációs kapcsolat, ami azt jelenti, hogy az egyik mutató változásait egy másik mutató változása kíséri.
Egy másik helyzetben vegye figyelembe a gyermek magassága és a pulzusszám (HR) közötti kapcsolatot. Mint ismeretes, mindkét érték közvetlenül függ az életkortól, így a legtöbb esetben a nagyobb magasságú (és ezért idősebb korú) gyermekek pulzusszáma alacsonyabb lesz. vagyis korrelációs kapcsolat megfigyelhető, és meglehetősen nagy zsúfoltság lehet. Ha azonban a gyerekeket visszük ugyanaz a kor, De különböző magasságúak, akkor nagy valószínűséggel a pulzusszámuk jelentéktelen mértékben fog eltérni, ezért arra a következtetésre juthatunk függetlenség Pulzusszám magasságból.
A fenti példa azt mutatja, hogy mennyire fontos különbséget tenni a statisztikákban az alapvető fogalmak között. kommunikációÉs függőségek mutatók a helyes következtetések levonásához.
4. Hogyan számítsuk ki a Pearson-féle korrelációs együtthatót?
A Pearson-korrelációs együttható a következő képlettel számítható ki:

5. Hogyan értelmezzük a Pearson-korrelációs együttható értékét?
A Pearson-korrelációs együttható értékeket abszolút értékeik alapján értelmezzük. A korrelációs együttható lehetséges értékei 0 és ±1 között változnak. Minél nagyobb az r xy abszolút értéke, annál szorosabb a kapcsolat a két mennyiség között. r xy = 0 a kommunikáció teljes hiányát jelzi. r xy = 1 – abszolút (funkcionális) kapcsolat meglétét jelzi. Ha a Pearson-féle korrelációs kritérium értéke 1-nél nagyobb vagy -1-nél kisebb, hiba történt a számításokban.
A korreláció szorosságának vagy erősségének felmérésére általában általánosan elfogadott kritériumokat alkalmaznak, amelyek szerint az r xy abszolút értékei< 0.3 свидетельствуют о gyenge kapcsolat, r xy értékek 0,3 és 0,7 között - a kapcsolatról átlagos tömítettség, r xy értéke > 0,7 - o erős kommunikáció.
A korreláció erősségének pontosabb becslése érhető el, ha használja Chaddock asztal:
Fokozat statisztikai jelentőség Az r xy korrelációs együtthatót a t-próbával kell meghatározni, a következő képlet alapján számítva:
![]()
A kapott t r értéket összehasonlítjuk a kritikus értékkel egy bizonyos szignifikanciaszinten és az n-2 szabadsági fokok számával. Ha t r meghaladja a t crit értéket, akkor következtetést vonunk le az azonosított korreláció statisztikai szignifikanciájáról.
6. Példa a Pearson-korrelációs együttható kiszámítására
A vizsgálat célja két kvantitatív mutató – a vér tesztoszteronszintje (X) és a test izomtömegének százalékos aránya (Y) közötti összefüggés szorosságának és statisztikai szignifikanciájának meghatározása, meghatározása volt. Az 5 alanyból álló minta kiindulási adatait (n = 5) a táblázat foglalja össze.
A tudományos kutatás során gyakran felmerül az igény, hogy összefüggést találjanak a kimeneti és a faktorváltozók között (a terméshozam és a csapadék mennyisége, az ember magassága és súlya homogén csoportokban nem és életkor szerint, pulzusszám és testhőmérséklet). stb.).
A második olyan jelek, amelyek hozzájárulnak a hozzájuk kapcsolódó változásokhoz (az első).
A korrelációelemzés fogalma
Sok van A fentiek alapján elmondható, hogy a korrelációelemzés egy olyan módszer, amellyel két vagy több változó statisztikai szignifikanciájára vonatkozó hipotézist teszteljük, ha a kutató képes mérni, de megváltoztatni nem.
A szóban forgó fogalomnak más definíciói is vannak. A korrelációs elemzés egy olyan feldolgozási módszer, amely magában foglalja a változók közötti korrelációs együtthatók tanulmányozását. Ebben az esetben az egy pár vagy több jellemzőpár közötti korrelációs együtthatókat összehasonlítják a köztük lévő statisztikai összefüggések megállapítása érdekében. A korrelációelemzés egy olyan módszer, amely a szigorú funkcionális jellegű opcionális jelenlétét mutató valószínűségi változók közötti statisztikai függést vizsgálja, amelyben az egyik valószínűségi változó dinamikája egy másik valószínűségi változó matematikai elvárásának dinamikájához vezet.
A hamis korreláció fogalma
A korrelációelemzés elvégzésekor figyelembe kell venni, hogy bármely jellemzőkészletre vonatkozóan elvégezhető, egymáshoz képest gyakran abszurd. Néha nincs ok-okozati összefüggésük egymással.
Ebben az esetben hamis összefüggésről beszélnek.
A korrelációelemzés problémái
A fenti definíciók alapján a leírt módszer alábbi feladatai fogalmazhatók meg: információ beszerzése az egyik keresett változóról egy másik segítségével; határozza meg a vizsgált változók közötti kapcsolat szorosságát.
A korrelációelemzés magában foglalja a vizsgált jellemzők közötti kapcsolat meghatározását, ezért a korrelációelemzés feladatai az alábbiakkal egészíthetők ki:
- azon tényezők azonosítása, amelyek a legnagyobb hatással vannak a kapott jellemzőre;
- az összefüggések korábban feltáratlan okainak azonosítása;
- korrelációs modell felépítése paraméteres elemzésével;
- kommunikációs paraméterek jelentőségének vizsgálata és intervallum értékelése.
A korrelációelemzés és a regresszió kapcsolata
A korrelációelemzés módszere gyakran nem korlátozódik a vizsgált mennyiségek közötti kapcsolat szorosságának megállapítására. Néha kiegészül olyan regressziós egyenletek összeállításával, amelyeket az azonos nevű elemzéssel kapunk, és amelyek a kapott és a faktor (tényező) jellemző (jellemzők) közötti korrelációs függőség leírását jelentik. Ez a módszer a vizsgált elemzéssel együtt alkotja a módszert
A módszer használatának feltételei
A hatékony tényezők egy vagy több tényezőtől függenek. A korrelációelemzés módszere akkor alkalmazható, ha az effektív és faktormutatók (tényezők) értékére vonatkozóan nagyszámú megfigyelés van, miközben a vizsgált tényezőknek kvantitatívnak kell lenniük, és konkrét forrásokban kell tükröződniük. Az elsőt a normáltörvénnyel határozhatjuk meg - ebben az esetben a korrelációs elemzés eredménye a Pearson-korrelációs együttható, vagy ha a jellemzők nem engedelmeskednek ennek a törvénynek, akkor a Spearman-féle rangkorrelációs együtthatót használjuk.

A korrelációelemzési faktorok kiválasztásának szabályai
A módszer alkalmazásakor meg kell határozni a teljesítménymutatókat befolyásoló tényezőket. Kiválasztásuk során figyelembe kell venni, hogy a mutatók között ok-okozati összefüggésnek kell lennie. Többtényezős korrelációs modell készítése esetén azokat választjuk ki, amelyek jelentős hatást gyakorolnak az eredményül kapott mutatóra, míg a 0,85-nél nagyobb párkorrelációs együtthatójú, egymással kölcsönösen függő tényezőket célszerű nem szerepeltetni a korrelációs modellben, valamint azokat, amelyek amelyeknél az eredő paraméterrel való kapcsolat nem lineáris vagy funkcionális jellegű.
Eredmények megjelenítése
A korrelációelemzés eredményei szöveges és grafikus formában is bemutathatók. Az első esetben korrelációs együtthatóként, a második esetben szórásdiagram formájában jelennek meg.
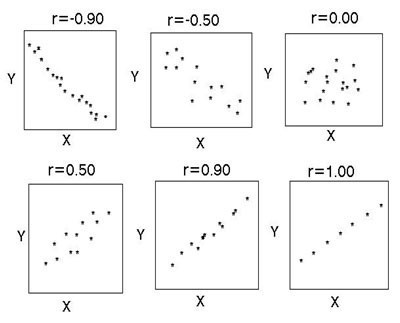
A paraméterek közötti korreláció hiányában a diagramon a pontok kaotikusan helyezkednek el, az átlagos kapcsolódási fokot nagyobb fokú rendezettség jellemzi, és a megjelölt jegyek többé-kevésbé egyenletes távolsága a mediántól. Az erős kapcsolat általában egyenes, és r=1-nél a pontdiagram egy lapos vonal. A fordított korreláció a grafikon irányában különbözik a bal felsőtől a jobb alsóig, a közvetlen korreláció - a bal alsótól a jobb felső sarokig.
Szórványdiagram 3D-s ábrázolása
A hagyományos 2D szórásdiagramos megjelenítés mellett ma már a korrelációelemzés 3D grafikus ábrázolását is használják.

Használnak egy szóródási mátrixot is, amely az összes párosított diagramot egyetlen ábrán jeleníti meg mátrix formátumban. N változó esetén a mátrix n sort és n oszlopot tartalmaz. Az i-edik sor és a j-edik oszlop metszéspontjában található diagram az Xi és Xj változók diagramja. Így minden sor és oszlop egy dimenzió, egyetlen cella kétdimenziós szóródiagramot jelenít meg.

A csatlakozás szorosságának értékelése
A korrelációs kapcsolat szorosságát a korrelációs együttható (r) határozza meg: erős - r = ±0,7 - ±1, közepes - r = ±0,3 - ±0,699, gyenge - r = 0 - ±0,299. Ez a besorolás nem szigorú. Az ábra egy kissé eltérő diagramot mutat.

Példa a korrelációelemző módszer használatára
Érdekes tanulmány készült az Egyesült Királyságban. A dohányzás és a tüdőrák kapcsolatának szentelték, és korrelációs elemzéssel végezték. Ezt a megfigyelést az alábbiakban mutatjuk be.
Szakmai csoport | halálozás |
|
Gazdák, erdészek és halászok | ||
Bányászok és kőbányai munkások | ||
Gáz-, koksz- és vegyi anyagok gyártói | ||
Üveg- és kerámiagyártók | ||
Kemencék, kovácsművek, öntödék és hengerművek dolgozói | ||
Elektromos és elektronikai munkások | ||
Mérnöki és kapcsolódó szakmák | ||
Famegmunkáló iparágak | ||
Bőrmunkások | ||
Textilmunkások | ||
Munkaruha gyártók | ||
Élelmiszer-, ital- és dohányipar dolgozói | ||
Papír- és nyomdagyártók | ||
Egyéb termékek gyártói | ||
Építők | ||
Festők és dekoratőrök | ||
Álló motorok, daruk, stb. | ||
A máshol nem szereplő munkavállalók | ||
Közlekedési és kommunikációs dolgozók | ||
Raktárosok, raktárosok, csomagolók és töltőgépesek | ||
Irodai dolgozók | ||
Eladók | ||
Sport- és rekreációs dolgozók | ||
Adminisztrátorok és menedzserek | ||
Szakemberek, technikusok és művészek |
Elkezdjük a korrelációs elemzést. Az áttekinthetőség kedvéért érdemesebb grafikus módszerrel kezdeni a megoldást, ehhez készítünk egy szóródiagramot.

Közvetlen kapcsolatot mutat. Pusztán a grafikus módszer alapján azonban nehéz egyértelmű következtetést levonni. Ezért folytatjuk a korrelációelemzést. Az alábbiakban egy példát mutatunk be a korrelációs együttható kiszámítására.
Szoftver segítségével (az alábbiakban példaként az MS Excelt ismertetjük) meghatározzuk a korrelációs együtthatót, amely 0,716, ami erős kapcsolatot jelent a vizsgált paraméterek között. Határozzuk meg a kapott érték statisztikai megbízhatóságát a megfelelő táblázat segítségével, amihez 25 értékpárból 2-t kell kivonnunk, ennek eredményeként 23-at kapunk és a táblázatban ezt a sort használva azt találjuk, hogy r kritikus p = 0,01 esetén (hiszen ezek orvosi adatok, szigorúbb függőség, más esetekben elegendő p=0,05), ami ennél a korrelációs elemzésnél 0,51. A példa bemutatta, hogy a számított r nagyobb, mint a kritikus r, és a korrelációs együttható értéke statisztikailag megbízhatónak tekinthető.
Szoftver használata korrelációelemzés során
A statisztikai adatfeldolgozás ismertetett típusa szoftver, különösen MS Excel segítségével végezhető el. A korreláció a következő paraméterek függvényekkel történő kiszámítását foglalja magában:
1. A korrelációs együtthatót a CORREL függvény segítségével határozzuk meg (tömb1; tömb2). Tömb1,2 - az eredő és faktorváltozók értékeinek intervallumának cellája.
A lineáris korrelációs együtthatót Pearson-korrelációs együtthatónak is nevezik, ezért az Excel 2007-től kezdve a függvény ugyanazokkal a tömbökkel használható.
A korrelációelemzés grafikus megjelenítése az Excelben a „Diagramok” panelen, a „Scatter Plot” kiválasztásával történik.
A kiindulási adatok megadása után grafikont kapunk.
2. A páronkénti korrelációs együttható jelentőségének felmérése Student-féle t-próba segítségével. A t-kritérium számított értékét összehasonlítják ennek a mutatónak a táblázatos (kritikus) értékével a vizsgált paraméter megfelelő értéktáblázatából, figyelembe véve a megadott szignifikanciaszintet és a szabadságfokok számát. Ezt a becslést a STUDISCOVER(valószínűség; szabadságfokok) függvény segítségével hajtjuk végre.
3. Párkorrelációs együtthatók mátrixa. Az elemzés az Adatelemző eszközzel történik, amelyben a Correlation van kiválasztva. A párkorrelációs együtthatók statisztikai értékelése abszolút értékének a táblázatos (kritikus) értékkel való összehasonlításával történik. Ha a számított páronkénti korrelációs együttható meghaladja a kritikus értéket, akkor az adott valószínűségi fokot figyelembe véve azt mondhatjuk, hogy a lineáris kapcsolat szignifikanciájára vonatkozó nullhipotézist nem utasítják el.
Végül
A korrelációelemzés módszerének tudományos kutatásban való alkalmazása lehetővé teszi a különböző tényezők és teljesítménymutatók közötti kapcsolat meghatározását. Figyelembe kell venni, hogy egy abszurd adatpárból vagy adathalmazból magas korrelációs együttható érhető el, ezért az ilyen típusú elemzést kellően nagy adattömbön kell elvégezni.
Az r számított értékének megszerzése után célszerű összehasonlítani a kritikus r-vel, hogy megerősítsük egy bizonyos érték statisztikai megbízhatóságát. A korrelációelemzés elvégezhető manuálisan képletekkel, vagy szoftverrel, különösen MS Excel segítségével. Itt is készíthet egy szórásdiagramot a korrelációelemzés vizsgált tényezői és a kapott jellemző közötti kapcsolat vizuális ábrázolása céljából.
Amint azt már többször megjegyeztük, ahhoz, hogy statisztikai következtetést lehessen levonni a vizsgált változók közötti korreláció meglétéről vagy hiányáról, ellenőrizni kell a minta korrelációs együtthatójának szignifikanciáját. Tekintettel arra, hogy a statisztikai jellemzők megbízhatósága, beleértve a korrelációs együtthatót is, a minta méretétől függ, előállhat olyan helyzet, amikor a korrelációs együttható értékét teljes egészében a számítás alapjául szolgáló mintában előforduló véletlenszerű ingadozások határozzák meg. . Ha szignifikáns kapcsolat van a változók között, akkor a korrelációs együtthatónak szignifikánsan különböznie kell a nullától. Ha a vizsgált változók között nincs korreláció, akkor a ρ populációs korrelációs együttható nullával egyenlő. A gyakorlati kutatásban általában mintamegfigyeléseken alapulnak. Mint minden statisztikai jellemző, a minta korrelációs együtthatója egy valószínűségi változó, azaz értékei véletlenszerűen oszlanak el az azonos nevű populációs paraméter (a korrelációs együttható valódi értéke) körül. A változók közötti korreláció hiányában y és x a korrelációs együttható a sokaságban nulla. De a szórás véletlenszerű jellege miatt alapvetően lehetségesek olyan helyzetek, amikor az ebből a sokaságból származó mintákból számított néhány korrelációs együttható nullától eltérő lesz.
A megfigyelt különbségek a mintában bekövetkezett véletlenszerű ingadozásoknak tulajdoníthatók, vagy a változók közötti kapcsolatok kialakulásának körülményeinek jelentős változását tükrözik? Ha a minta korrelációs együtthatójának értékei a mutató véletlenszerű természete miatt a szórási zónába esnek, akkor ez nem bizonyíték az összefüggés hiányára. A legtöbb, ami elmondható, hogy a megfigyelési adatok nem tagadják a változók közötti kapcsolat hiányát. De ha a minta korrelációs együttható értéke kívül esik az említett szórási zónán, akkor azt a következtetést vonják le, hogy szignifikánsan különbözik a nullától, és feltételezhetjük, hogy a változók között y és x statisztikailag szignifikáns kapcsolat van. A probléma megoldására használt kritériumot a különböző statisztikák eloszlása alapján szignifikancia kritériumnak nevezzük.
A szignifikancia-vizsgálati eljárás a nullhipotézis megfogalmazásával kezdődik H0 . Általánosságban elmondható, hogy nincs szignifikáns különbség a mintaparaméter és a populációs paraméter között. Alternatív hipotézis H1 az, hogy jelentős különbségek vannak e paraméterek között. Például egy populációban a korreláció tesztelésekor a nullhipotézis az, hogy a valódi korrelációs együttható nulla ( H0: ρ = 0). Ha a teszt eredményeként kiderül, hogy a nullhipotézis nem elfogadható, akkor a minta korrelációs együtthatója rAzta szignifikánsan különbözik a nullától (a nullhipotézist elvetik, és az alternatívát elfogadják H1). Más szóval, azt a feltételezést, hogy a sokaság valószínűségi változói nem korrelálnak egymással, megalapozatlannak kell tekinteni. Ezzel szemben, ha a szignifikancia teszt alapján a nullhipotézist elfogadjuk, azaz. rAzta a véletlen szórás megengedett zónájában található, akkor nincs okunk megkérdőjelezhetőnek tekinteni a nem korrelált változók feltételezését a sokaságban.
A szignifikancia-teszt során a kutató beállít egy α szignifikancia szintet, amely gyakorlati bizonyosságot ad arról, hogy téves következtetéseket csak nagyon ritka esetekben vonnak le. A szignifikancia szint azt a valószínűséget fejezi ki, hogy a nullhipotézis H0 elutasítják, amikor valóban igaz. Nyilvánvaló, hogy érdemes ezt a valószínűséget a lehető legkisebbre választani.
Legyen ismert a mintakarakterisztika eloszlása, amely a populációs paraméter torzítatlan becslése. A kiválasztott α szignifikanciaszint az eloszlás görbéje alatti árnyékolt területeknek felel meg (lásd 24. ábra). Az eloszlási görbe alatti árnyékolatlan terület határozza meg a valószínűséget P = 1 - α . Az x tengelyen az árnyékolt területek alatti szegmensek határait kritikus értékeknek nevezzük, és maguk a szegmensek alkotják a kritikus régiót vagy a hipotézis elutasításának területét.
A hipotézisvizsgálati eljárás során a megfigyelések eredményeiből számított mintakarakterisztikát összehasonlítjuk a megfelelő kritikus értékkel. Ebben az esetben különbséget kell tenni az egyoldalú és a kétoldali kritikus területek között. A kritikus terület megadásának formája a statisztikai kutatásban a probléma megfogalmazásától függ. Kétoldalú kritikus régióra akkor van szükség, ha egy mintaparaméter és egy populációs paraméter összehasonlításakor meg kell becsülni a köztük lévő eltérés abszolút értékét, azaz a vizsgált értékek közötti pozitív és negatív különbségek is érdeklődés. Ha meg kell győződni arról, hogy egy érték átlagosan szigorúan nagyobb vagy kisebb, mint egy másik, akkor egy egyoldalú kritikus tartományt (jobb vagy bal oldali) használunk. Nyilvánvaló, hogy ugyanazon kritikus érték esetén a szignifikancia szintje egyoldali kritikus tartomány használatakor kisebb, mint kétoldali esetében. Ha a mintakarakterisztika eloszlása szimmetrikus,
Rizs. 24. A H0 nullhipotézis tesztelése
akkor a kétoldali kritikus tartomány szignifikanciaszintje α, az egyoldalié pedig - (lásd 24. ábra). Korlátozzuk magunkat a probléma általános megfogalmazására. A statisztikai hipotézisek tesztelésének elméleti alapjairól részletesebb információ a szakirodalomban található. Az alábbiakban csak a különböző eljárások szignifikanciakritériumait jelöljük meg, anélkül, hogy kidolgoznánk.
A párkorrelációs együttható szignifikanciájának ellenőrzésével megállapítható a korreláció megléte vagy hiánya a vizsgált jelenségek között. Kapcsolat hiányában a populációs korrelációs együttható nulla (ρ = 0). A tesztelési eljárás a null- és alternatív hipotézisek megfogalmazásával kezdődik:
H0: különbség a minta korrelációs együtthatója között r és ρ = 0 jelentéktelen,
H1: a különbség köztük rés ρ = 0 szignifikáns, tehát a változók között nál nélÉs x jelentős összefüggés van. Az alternatív hipotézis azt jelenti, hogy kétoldalú kritikus régiót kell használnunk.
A 8.1. részben már említettük, hogy a minta korrelációs együtthatója bizonyos feltételezések mellett egy valószínűségi változóhoz kapcsolódik. t, engedelmeskedve a Hallgatói elosztásnak azzal f = n- 2 szabadságfok. A mintaeredményekből számított statisztikák
összevetjük a Student eloszlástáblázatból meghatározott kritikus értékkel egy adott α szignifikanciaszinten Ésf = n- 2 szabadságfok. A kritérium alkalmazásának szabálya a következő: ha | t| >tf,A, akkor a nullhipotézis α szignifikancia szinten elutasítva, azaz a változók közötti kapcsolat szignifikáns; ha | t| ≤tf,A, akkor az α szignifikanciaszintű nullhipotézist elfogadjuk. Értékeltérés r ρ = 0-ból véletlenszerű variációnak tulajdonítható. A mintaadatok a vizsgált hipotézist nagyon lehetségesnek és elfogadhatónak jellemzik, vagyis az összefüggés hiányának hipotézise nem vet fel kifogást.
A hipotézis tesztelésének eljárása jelentősen leegyszerűsödik, ha a statisztikák helyett t használjuk a korrelációs együttható kritikus értékeit, amelyek a Student-eloszlás kvantilisein keresztül határozhatók meg, behelyettesítve (8.38)-ba. t= tf, a és r= ρ f, V:
![]() (8.39)
(8.39)
A kritikus értékekről részletes táblázatok találhatók, amelyekből egy kivonat található a könyv mellékletében (lásd a 6. táblázatot). A hipotézis tesztelésének szabálya ebben az esetben a következőre csapódik le: ha r> ρ f, és akkor azt állíthatjuk, hogy a változók közötti kapcsolat szignifikáns. Ha r≤rf,A, akkor a megfigyelési eredményeket konzisztensnek tekintjük az összefüggés hiányának hipotézisével.
;  ;
;  .
.
Most számítsuk ki a minta szórásának értékeit:
https://pandia.ru/text/78/148/images/image443_0.gif" width="413" height="60 src=">.
A https://pandia.ru/text/78/148/images/image434_0.gif" width="25" height="24"> szint közötti korreláció a tizedik osztályosok körében annál magasabb a matematika teljesítményének átlagos szintje, és fordítva.
2. A korrelációs együttható szignifikanciájának ellenőrzése
Mivel a minta együtthatóját mintaadatokból számítják ki, ez egy valószínűségi változó . Ha , akkor felmerül a kérdés: ezt magyarázza-e valóban létező lineáris kapcsolat és https://pandia.ru/text/78/148/images/image301_1.gif" width="29" height="25 src=" >.gif" width="27" height="25">: (ha a korrelációs jel nem ismert); vagy egyoldalas https://pandia.ru/text/78/148/images/image448_0.gif" width="43" height="23 src=">.gif" width="43" height="23 src =" > (ha a korreláció előjele előre meghatározható).
1. módszer. A hipotézis tesztelésére használják https://pandia.ru/text/78/148/images/image150_1.gif" width="11" height="17 src="> - Diákok t-tesztje a képlet szerint
https://pandia.ru/text/78/148/images/image406_0.gif" width="13" height="15">.gif" width="36 height=25" height="25">.gif " width="17" height="16"> és a szabadságfok száma a kétoldali kritériumhoz.
A kritikus régiót az egyenlőtlenség adja ![]() .
.
Ha https://pandia.ru/text/78/148/images/image455_0.gif" width="99" height="29 src=">, akkor a nullhipotézist elvetik. Következtetéseket vonunk le:
§ kétoldalú alternatív hipotézis esetén – a korrelációs együttható jelentősen eltér nullától;
§ egyoldalú hipotézis esetén – statisztikailag szignifikáns pozitív (vagy negatív) összefüggés áll fenn.
2. módszer. Használhatod is a korrelációs együttható kritikus értékeinek táblázata, amelyből megtaláljuk a korrelációs együttható kritikus értékét a szabadsági fokok számával https://pandia.ru/text/78/148/images/image367_1.gif" width="17 height=16" height="16">.
Ha https://pandia.ru/text/78/148/images/image459_0.gif" width="101" height="29 src=">, akkor arra a következtetésre jutunk, hogy a korrelációs együttható jelentősen eltér 0-tól és statisztikailag szignifikáns összefüggés van.
Így egyes jelenségek egyidejűleg, de egymástól függetlenül (közös események) fordulhatnak elő vagy változhatnak ( hamis regresszió). Mások - nem egymással, hanem egy bonyolultabb ok-okozati összefüggés szerint ok-okozati kapcsolatban lenni ( közvetett regresszió). Tehát szignifikáns korrelációs együttható mellett az ok-okozati összefüggés meglétére vonatkozó végső következtetést csak a vizsgált probléma sajátosságainak figyelembevételével lehet levonni.
2. példa Határozza meg az 1. példában számított mintakorrelációs együttható szignifikanciáját!
Megoldás.
Tegyünk fel egy hipotézist: az általános populációban nincs korreláció. Mivel az 1. példa megoldásának eredményeként a korreláció előjele meghatározásra kerül - a korreláció pozitív, az alternatív hipotézis egyoldalú: https://pandia.ru/text/78/148/images/image448_0.gif " width="43" height="23 src =>>.
Keressük meg a kritérium empirikus értékét:
https://pandia.ru/text/78/148/images/image461_0.gif" width="167 height=20" height="20"> válassza ki a szignifikanciaszintet, amely egyenlő a következővel: . A „Kritikus értékek” táblázat szerint a Student-féle t-próba különböző szignifikanciaszintekre” a kritikus értéket találjuk.
A https://pandia.ru/text/78/148/images/image434_0.gif" width="25 height=24" height="24"> és a matematikai teljesítmény átlagos szintje óta statisztikailag szignifikáns összefüggés van .
Tesztfeladatok
1. Kérjük, jelöljön meg legalább két helyes választ. A minta korrelációs együtthatójának szignifikanciájának tesztelése annak a hipotézisnek a statisztikai vizsgálatán alapul, hogy...
1) nincs összefüggés az általános populációban
2) a minta korrelációs együtthatójának nullától való eltérését csak a minta véletlenszerűsége magyarázza
3) a korrelációs együttható jelentősen eltér 0-tól
4) a minta korrelációs együtthatójának nullától való eltérése nem véletlen
2. Ha a minta lineáris korrelációs együtthatója , akkor az egyik jellemző nagyobb értéke... egy másik jellemző nagyobb értékének felel meg.
1) átlagosan
3) a legtöbb megfigyelésben
4) alkalmanként
3. Mintakorrelációs együttható https://pandia.ru/text/78/148/images/image465_0.gif" width="64" height="23 src="> (a minta méretéhez és 0,05-ös szignifikanciaszintjéhez). Lehetséges-e azt mondani, hogy statisztikailag szignifikáns pozitív összefüggés van a pszichológiai tulajdonságok között?
5. Keressük meg a mintakorrelációs együtthatót a pszichológiai jellemzők közötti lineáris kapcsolat erősségének azonosításában https://pandia.ru/text/78/148/images/image466_0.gif" width="52 height=20" " height="20"> és 0,05 szignifikanciaszint). Mondhatjuk-e, hogy a minta korrelációs együtthatójának nullától való eltérését csak a minta véletlenszerűsége magyarázza?
3. témakör: rangkorrelációs együtthatók és asszociációk
1. Rangkorrelációs együttható https://pandia.ru/text/78/148/images/image130_3.gif" width="21 height=19" height="19"> és. A jellemzők értékeinek száma (mutatók, tárgyak, minőségek , tulajdonságok) bármilyen lehet, de számuk azonos legyen.
Tantárgyak | ||||
Tulajdonság rangok | ||||
Tulajdonság rangok |
Jelöljük az egyes témáknál két változó rangsorolási különbségét a https://pandia.ru/text/78/148/images/image470_0.gif" width="319" height="66"> segítségével,
ahol a rangsorolt jellemzők és mutatók értékeinek száma.
A rangkorrelációs együttható –1 és +1 közötti értékeket vesz felés a Pearson-korrelációs együttható gyors becslésének eszköze.
Mert a Spearman rangkorrelációs együttható szignifikanciájának tesztelése (ha az értékek száma https://pandia.ru/text/78/148/images/image472_0.gif" width="55" height="29"> függ a számtól és a szignifikancia szintjétől. Ha a empirikus érték nagyobb, akkor a szignifikancia szinten azt lehet mondani, hogy a jelek összefüggésben állnak egymással.
1. példa A pszichológus megtudja, hogyan függenek össze a tanulók matematikából és fizikából elért eredményei, amelyek eredményeit vezetéknév szerint rangsorolt sorozat formájában mutatja be.
Diák | Összeg |
||||||||||
Akadémiai előadás matematika | |||||||||||
Akadémiai előadás a fizikában | |||||||||||
Négyzetes különbség a rangok között |
Számítsuk ki az összeget, ekkor a Spearman rangkorrelációs együttható egyenlő:
Ellenőrizzük a talált rangkorrelációs együttható jelentősége. Keressük meg a Spearman rangkorrelációs együttható kritikus értékeit a táblázat segítségével (lásd a függelékeket):
https://pandia.ru/text/78/148/images/image480_0.gif" width="72" height="25"> nagyobb, mint a = 0,64 és a 0,79. Ez azt jelzi, hogy az érték a A korrelációs együttható szignifikancia területe, ezért vitatható, hogy a Spearman-féle rangkorrelációs együttható szignifikánsan különbözik a 0-tól, ami azt jelenti, hogy a tanulók matematika és fizika teljesítményének eredményei pozitív korreláció köti össze . Szignifikáns pozitív összefüggés van a matematika és a fizika teljesítménye között: minél jobb a matematika teljesítménye, annál jobbak az átlagos fizikai eredmények, és fordítva.
A Pearson és Spearman korrelációs együtthatókat összehasonlítva megállapítható, hogy a Pearson korrelációs együttható korrelálja az értékeket mennyiségeket, és a Spearman-korrelációs együttható az értékek rangok ezek a mennyiségek, ezért a Pearson és Spearman együtthatók értékei gyakran nem esnek egybe.
A pszichológiai kutatás során nyert kísérleti anyag teljesebb megértéséhez tanácsos együtthatókat számítani Pearson és Spearman szerint is.
Megjegyzés. Jelenlétében egyenlő rangok a rangsorokban és a rangkorrelációs együttható kiszámítására szolgáló képlet számlálójában a kifejezések hozzáadódnak - „korrekciók a rangokhoz”:  ;
;  ,
,
ahol https://pandia.ru/text/78/148/images/image130_3.gif" width="21" height="19">;
https://pandia.ru/text/78/148/images/image165_1.gif" width="16" height="19">.
Ebben az esetben a rangkorrelációs együttható kiszámításának képlete a következő formában jelenik meg: https://pandia.ru/text/78/148/images/image485_0.gif" width="16" height="19">.
A társulási együttható alkalmazásának feltételei.
1. Az összehasonlított jellemzőket dichotóm skálán mérjük.
2..gif" width="21" height="19">, amelyeket a 0 és 1 szimbólumok jeleznek, a táblázatban láthatók.
Megfigyelési szám |
