पियर्सन सहसंबंध परीक्षण. प्रतिगमन और सहसंबंध मापदंडों का सांख्यिकीय महत्व
परिचय। 2
1. छात्र के एफ-परीक्षण का उपयोग करके प्रतिगमन और सहसंबंध गुणांक के महत्व का आकलन करना। 3
2. छात्र के एफ-टेस्ट का उपयोग करके प्रतिगमन और सहसंबंध गुणांक के महत्व की गणना। 6
निष्कर्ष। 15
प्रतिगमन समीकरण का निर्माण करने के बाद, इसके महत्व की जांच करना आवश्यक है: विशेष मानदंडों का उपयोग करके, यह निर्धारित करें कि प्रतिगमन समीकरण द्वारा व्यक्त परिणामी निर्भरता यादृच्छिक है, यानी। क्या इसका उपयोग पूर्वानुमान उद्देश्यों और कारक विश्लेषण के लिए किया जा सकता है। आंकड़ों में, विचरण के विश्लेषण और विशेष मानदंडों (उदाहरण के लिए, एफ-परीक्षण) की गणना का उपयोग करके प्रतिगमन गुणांक के महत्व का कड़ाई से परीक्षण करने के लिए तरीके विकसित किए गए हैं। औसत सापेक्ष रैखिक विचलन (ई) की गणना करके एक ढीला परीक्षण किया जा सकता है, जिसे सन्निकटन की औसत त्रुटि कहा जाता है:
आइए अब हम प्रतिगमन गुणांक bj के महत्व का आकलन करने और प्रतिगमन मॉडल Ru (J=l,2,..., p) के मापदंडों के लिए एक विश्वास अंतराल का निर्माण करने के लिए आगे बढ़ें।
ब्लॉक 5 - छात्र के ^-परीक्षण के मूल्य के आधार पर प्रतिगमन गुणांक के महत्व का आकलन। टा के परिकलित मानों की तुलना अनुमेय मान से की जाती है
ब्लॉक 5 - ^-मानदंड के मूल्य के आधार पर प्रतिगमन गुणांक के महत्व का आकलन। T0n के परिकलित मानों की तुलना अनुमेय मान 4,/ से की जाती है, जो किसी दी गई त्रुटि संभावना (ए) और स्वतंत्रता की डिग्री की संख्या (/) के लिए टी-वितरण तालिकाओं से निर्धारित होता है।
संपूर्ण मॉडल के महत्व की जांच करने के अलावा, छात्र/-परीक्षण का उपयोग करके प्रतिगमन गुणांक के महत्व का परीक्षण करना आवश्यक है। प्रतिगमन गुणांक br का न्यूनतम मान bifob- ^t स्थिति के अनुरूप होना चाहिए, जहां bi i-वें कारक विशेषता के लिए प्राकृतिक पैमाने पर प्रतिगमन समीकरण के गुणांक का मान है; आह. - प्रत्येक गुणांक का माध्य वर्ग त्रुटि। उनके महत्व में गुणांक डी की अतुलनीयता;
आगे सांख्यिकीय विश्लेषण प्रतिगमन गुणांक के महत्व का परीक्षण करने से संबंधित है। ऐसा करने के लिए, हम प्रतिगमन गुणांक के लिए ^-मानदंड का मान ज्ञात करते हैं। उनकी तुलना के परिणामस्वरूप, सबसे छोटा ^-मानदंड निर्धारित किया जाता है। वह कारक जिसका गुणांक सबसे छोटे ^-मानदंड से मेल खाता है, उसे आगे के विश्लेषण से बाहर रखा गया है।
प्रतिगमन और सहसंबंध गुणांक के सांख्यिकीय महत्व का आकलन करने के लिए, प्रत्येक संकेतक के लिए छात्र के टी-परीक्षण और आत्मविश्वास अंतराल की गणना की जाती है। संकेतकों की यादृच्छिक प्रकृति के बारे में एक परिकल्पना सामने रखी गई है, अर्थात। शून्य से उनके नगण्य अंतर के बारे में। छात्र के एफ-परीक्षण का उपयोग करके प्रतिगमन और सहसंबंध गुणांक के महत्व का आकलन यादृच्छिक त्रुटि के परिमाण के साथ उनके मूल्यों की तुलना करके किया जाता है:
छात्र/-परीक्षण का उपयोग करके शुद्ध प्रतिगमन गुणांक के महत्व का आकलन करने से मूल्य की गणना होती है
श्रम की गुणवत्ता विशिष्ट श्रम की एक विशेषता है, जो आर्थिक विकास के लिए इसकी जटिलता, तीव्रता (तीव्रता), स्थितियों और महत्व की डिग्री को दर्शाती है। के.टी. एक टैरिफ प्रणाली के माध्यम से मापा जाता है जो योग्यता के स्तर (काम की जटिलता), परिस्थितियों, श्रम की गंभीरता और इसकी तीव्रता के साथ-साथ विकास के लिए व्यक्तिगत उद्योगों और उत्पादन, क्षेत्रों, क्षेत्रों के महत्व के आधार पर मजदूरी को अलग करने की अनुमति देता है। देश की अर्थव्यवस्था. के.टी. श्रमिकों की मजदूरी में अभिव्यक्ति मिलती है, जो श्रम बाजार में श्रम की मांग और आपूर्ति (विशिष्ट प्रकार के श्रम) के प्रभाव में विकसित होती है। के.टी. - संरचना में जटिल
परियोजना के व्यक्तिगत आर्थिक, सामाजिक और पर्यावरणीय परिणामों के सापेक्ष महत्व के प्राप्त अंक, एक परियोजना के "सामाजिक और पर्यावरणीय-आर्थिक दक्षता के जटिल स्कोरिंग आयामहीन मानदंड" का उपयोग करके वैकल्पिक परियोजनाओं और उनके विकल्पों की तुलना करने के लिए एक आधार प्रदान करते हैं, गणना की गई (औसत महत्व स्कोर में) सूत्र का उपयोग कर
इंट्रा-उद्योग विनियमन किसी दिए गए उद्योग में श्रमिकों के लिए मजदूरी में अंतर सुनिश्चित करता है, जो किसी दिए गए उद्योग में व्यक्तिगत प्रकार के उत्पादन के महत्व, जटिलता और कामकाजी परिस्थितियों के साथ-साथ उपयोग किए गए पारिश्रमिक के रूपों पर निर्भर करता है।
व्यक्तिगत संकेतकों के महत्व को ध्यान में रखे बिना मानक उद्यम के संबंध में विश्लेषण किए गए उद्यम का परिणामी रेटिंग मूल्यांकन तुलनात्मक है। कई उद्यमों की रेटिंग की तुलना करते समय, प्राप्त तुलनात्मक मूल्यांकन के न्यूनतम मूल्य के साथ उद्यम को उच्चतम रेटिंग दी जाती है।
किसी उत्पाद की गुणवत्ता को उसकी उपयोगिता के माप के रूप में समझना उसके माप के बारे में एक व्यावहारिक रूप से महत्वपूर्ण प्रश्न उठाता है। इसका समाधान किसी विशिष्ट आवश्यकता की पूर्ति में व्यक्तिगत गुणों के महत्व का अध्ययन करके प्राप्त किया जाता है। उत्पाद की खपत की स्थितियों के आधार पर एक ही संपत्ति का महत्व भी भिन्न हो सकता है। नतीजतन, किसी उत्पाद की उपयोगिता उसके उपयोग की विभिन्न परिस्थितियों में अलग-अलग होती है।
कार्य का दूसरा चरण सांख्यिकीय आंकड़ों का अध्ययन करना और संकेतकों के संबंध और अंतःक्रिया की पहचान करना, व्यक्तिगत कारकों के महत्व और सामान्य संकेतकों में परिवर्तन के कारणों का निर्धारण करना है।
सभी विचारित संकेतकों को एक में इस तरह से संयोजित किया जाता है कि परिणाम उद्यम की गतिविधि के सभी विश्लेषण किए गए पहलुओं का एक व्यापक मूल्यांकन होता है, इसकी गतिविधि की स्थितियों को ध्यान में रखते हुए, विभिन्न प्रकार के लिए व्यक्तिगत संकेतकों के महत्व की डिग्री को ध्यान में रखते हुए। निवेशक:
प्रतिगमन गुणांक प्रदर्शन संकेतक पर कारकों के प्रभाव की तीव्रता को दर्शाते हैं। यदि कारक संकेतकों का प्रारंभिक मानकीकरण किया जाता है, तो b0 कुल में प्रभावी संकेतक के औसत मूल्य के बराबर है। गुणांक बी, बी2 ..... बीएल दर्शाते हैं कि यदि कारक संकेतक का मान शून्य के औसत से एक मानक विचलन से विचलित होता है, तो प्रभावी संकेतक का स्तर उसके औसत मूल्य से कितनी इकाइयों तक विचलित होता है। इस प्रकार, प्रतिगमन गुणांक प्रदर्शन संकेतक के स्तर को बढ़ाने के लिए व्यक्तिगत कारकों के महत्व की डिग्री को दर्शाते हैं। प्रतिगमन गुणांक के विशिष्ट मान अनुभवजन्य डेटा से कम से कम वर्ग विधि (सामान्य समीकरणों की प्रणालियों को हल करने के परिणामस्वरूप) के अनुसार निर्धारित किए जाते हैं।
2. छात्र के एफ-टेस्ट का उपयोग करके प्रतिगमन और सहसंबंध गुणांक के महत्व की गणना
आइए बहुकारक संबंधों के रैखिक रूप को न केवल सबसे सरल मानें, बल्कि पीसी के लिए एप्लिकेशन सॉफ़्टवेयर पैकेजों द्वारा प्रदान किए गए रूप पर भी विचार करें। यदि किसी व्यक्तिगत कारक और परिणामी विशेषता के बीच संबंध रैखिक नहीं है, तो कारक विशेषता के मान को प्रतिस्थापित या परिवर्तित करके समीकरण को रैखिक बनाया जाता है।
बहुभिन्नरूपी प्रतिगमन समीकरण का सामान्य रूप है:
जहाँ k कारक विशेषताओं की संख्या है।
समीकरण (8.32) के मापदंडों की गणना के लिए आवश्यक न्यूनतम वर्ग समीकरणों की प्रणाली को सरल बनाने के लिए, इन विशेषताओं के औसत मूल्यों से सभी विशेषताओं के व्यक्तिगत मूल्यों के विचलन को आमतौर पर पेश किया जाता है।
हमें न्यूनतम वर्गों के k समीकरणों की एक प्रणाली प्राप्त होती है:

इस प्रणाली को हल करते हुए, हम सशर्त रूप से शुद्ध प्रतिगमन गुणांक बी के मान प्राप्त करते हैं। समीकरण के मुक्त पद की गणना सूत्र द्वारा की जाती है
शब्द "सशर्त रूप से शुद्ध प्रतिगमन गुणांक" का अर्थ है कि प्रत्येक मान bj उसके औसत मूल्य से परिणामी विशेषता के कुल औसत विचलन को मापता है जब कोई दिया गया कारक xj उसके माप की एक इकाई द्वारा उसके औसत मूल्य से विचलन करता है और बशर्ते कि सभी प्रतिगमन समीकरण में शामिल अन्य कारक, औसत मूल्यों पर तय होते हैं, बदलते नहीं हैं, भिन्न नहीं होते हैं।
इस प्रकार, युग्मित प्रतिगमन गुणांक के विपरीत, सशर्त शुद्ध प्रतिगमन गुणांक अन्य कारकों की भिन्नता के साथ इस कारक की भिन्नता के संबंध से अलग होकर, एक कारक के प्रभाव को मापता है। यदि प्रतिगमन समीकरण में परिणामी विशेषता की भिन्नता को प्रभावित करने वाले सभी कारकों को शामिल करना संभव होता, तो बीजे के मान। कारकों के शुद्ध प्रभाव का माप माना जा सकता है। लेकिन चूंकि समीकरण में सभी कारकों को शामिल करना वास्तव में असंभव है, तो गुणांक बी.जे. समीकरण में शामिल नहीं किए गए कारकों के प्रभाव के मिश्रण से मुक्त नहीं।
प्रतिगमन समीकरण में सभी कारकों को तीन कारणों में से किसी एक या सभी को एक साथ शामिल करना असंभव है, क्योंकि:
1) कुछ कारक आधुनिक विज्ञान के लिए अज्ञात हो सकते हैं, किसी भी प्रक्रिया का ज्ञान हमेशा अधूरा होता है;
2) कुछ ज्ञात सैद्धांतिक कारकों के बारे में कोई जानकारी नहीं है या यह अविश्वसनीय है;
3) अध्ययन की जा रही जनसंख्या का आकार (नमूना) सीमित है, जिससे प्रतिगमन समीकरण में सीमित संख्या में कारकों को शामिल करना संभव हो जाता है।
सशर्त शुद्ध प्रतिगमन गुणांक बी.जे. माप की विभिन्न इकाइयों में व्यक्त नामित संख्याएँ हैं और इसलिए एक दूसरे के साथ अतुलनीय हैं। उन्हें तुलनीय सापेक्ष संकेतकों में परिवर्तित करने के लिए, जोड़ीवार सहसंबंध गुणांक प्राप्त करने के लिए उसी परिवर्तन का उपयोग किया जाता है। परिणामी मान को मानकीकृत प्रतिगमन गुणांक या?-गुणांक कहा जाता है।
कारक xj का गुणांक परिणामी विशेषता y की भिन्नता पर कारक xj की भिन्नता के प्रभाव का माप निर्धारित करता है, जो प्रतिगमन समीकरण में शामिल अन्य कारकों की सहवर्ती भिन्नता से अलग होता है।
सशर्त रूप से शुद्ध प्रतिगमन के गुणांक को कनेक्शन के सापेक्ष तुलनीय संकेतक, लोच गुणांक के रूप में व्यक्त करना उपयोगी है:
कारक xj का लोच गुणांक कहता है कि जब किसी दिए गए कारक का मान उसके औसत मान से 1% विचलित हो जाता है और समीकरण में शामिल अन्य कारकों के सहवर्ती विचलन से अलग हो जाता है, तो परिणामी विशेषता उसके औसत मान से ej प्रतिशत तक विचलित हो जाएगी वाई से अधिक बार, लोच गुणांक की व्याख्या और गतिशीलता के संदर्भ में की जाती है: कारक x में इसके औसत मूल्य के 1% की वृद्धि के साथ, परिणामी विशेषता ई से बढ़ जाएगी। इसके औसत मूल्य का प्रतिशत।
आइए एक उदाहरण के रूप में उन्हीं 16 फ़ार्मों का उपयोग करके बहुकारक प्रतिगमन समीकरण की गणना और व्याख्या पर विचार करें (तालिका 8.1)। प्रभावी संकेत सकल आय का स्तर है और इसे प्रभावित करने वाले तीन कारक तालिका में प्रस्तुत किए गए हैं। 8.7.
आइए हम एक बार फिर याद करें कि सहसंबंध के विश्वसनीय और पर्याप्त सटीक संकेतक प्राप्त करने के लिए एक बड़ी आबादी की आवश्यकता होती है।
तालिका 8.7
सकल आय का स्तर और उसके कारक
| फार्म नंबर |
सकल आय, रु./रा |
श्रम लागत, मानव दिवस/हेक्टेयर x1 |
कृषि योग्य भूमि का हिस्सा, |
प्रति 1 गाय दूध की उपज, |
तालिका 8.8 प्रतिगमन समीकरण संकेतक
| आश्रित चर: y |
|||||
| प्रतिगमन गुणांक |
|||||
| स्थिरांक-240.112905 |
|||||
| एसटीडी. अनुमान की त्रुटि = 79.243276 |
|||||
समाधान पीसी के लिए "माइक्रोस्टेट" प्रोग्राम का उपयोग करके किया गया था। यहां प्रिंटआउट से तालिकाएं हैं: तालिका। 8.7 सभी विशेषताओं के औसत मान और मानक विचलन देता है। मेज़ 8.8 में प्रतिगमन गुणांक और उनका संभाव्य मूल्यांकन शामिल है:
पहला कॉलम "var" - चर, यानी कारक; दूसरा कॉलम "प्रतिगमन गुणांक" - सशर्त रूप से शुद्ध प्रतिगमन गुणांक बी.जे.; तीसरा कॉलम “एसटीडी. त्रुटि" - प्रतिगमन गुणांक अनुमान में औसत त्रुटियां; चौथा स्तंभ - भिन्नता की स्वतंत्रता के 12 डिग्री के साथ छात्र के टी-टेस्ट के मूल्य; पाँचवाँ स्तंभ "संभावना" - प्रतिगमन गुणांक के सापेक्ष शून्य परिकल्पना की संभावना;
छठा स्तंभ "आंशिक आर2" - निर्धारण के आंशिक गुणांक। कॉलम 3-6 में संकेतकों की गणना के लिए सामग्री और पद्धति पर अध्याय 8 में आगे चर्चा की गई है। "स्थिर" प्रतिगमन समीकरण ए का मुक्त शब्द है; "एसटीडी. अनुमान की त्रुटि।" - प्रतिगमन समीकरण का उपयोग करके प्रभावी विशेषता का अनुमान लगाने की माध्य वर्ग त्रुटि। एकाधिक प्रतिगमन समीकरण प्राप्त किया गया था:
y = 2.26x1 - 4.31x2 + 0.166x3 - 240।
इसका मतलब है कि प्रति 1 हेक्टेयर कृषि भूमि पर सकल आय की मात्रा में औसतन 2.26 रूबल की वृद्धि हुई। श्रम लागत में 1 घंटा/हेक्टेयर की वृद्धि के साथ; औसतन 4.31 रूबल की कमी हुई। कृषि भूमि में कृषि योग्य भूमि की हिस्सेदारी में 1% की वृद्धि और 0.166 रूबल की वृद्धि के साथ। प्रति गाय दूध की उपज में 1 किलो की वृद्धि के साथ। मुक्त अवधि का नकारात्मक मूल्य काफी स्वाभाविक है, और, जैसा कि पैराग्राफ 8.2 में पहले ही उल्लेख किया गया है, प्रभावी संकेत यह है कि कारकों के शून्य मूल्यों तक पहुंचने से बहुत पहले सकल आय शून्य हो जाती है, जो उत्पादन में असंभव है।
x^ के लिए गुणांक का नकारात्मक मान अध्ययन के तहत खेतों की अर्थव्यवस्था में महत्वपूर्ण परेशानी का संकेत है, जहां फसल खेती लाभहीन है, और केवल पशुधन खेती लाभदायक है। खेती के तर्कसंगत तरीकों और सभी क्षेत्रों के उत्पादों के लिए सामान्य कीमतों (संतुलन या उनके करीब) के साथ, आय में कमी नहीं होनी चाहिए, बल्कि कृषि भूमि - कृषि योग्य भूमि के सबसे उपजाऊ हिस्से में वृद्धि के साथ वृद्धि होनी चाहिए।
तालिका की अंतिम दो पंक्तियों के डेटा के आधार पर। 8.7 और तालिका. 8.8 हम सूत्रों (8.34) और (8.35) के अनुसार पी-गुणांक और लोच गुणांक की गणना करते हैं।
आय के स्तर में भिन्नता और गतिशीलता में इसके संभावित परिवर्तन दोनों कारक x3 से सबसे अधिक प्रभावित होते हैं - गायों की उत्पादकता, और x2 द्वारा सबसे कमजोर - कृषि योग्य भूमि का हिस्सा। P2/ मानों का आगे भी उपयोग किया जाएगा (तालिका 8.9);
तालिका 8.9 आय स्तर पर कारकों का तुलनात्मक प्रभाव
| कारक xj |
|||

तो, हमने पाया है कि कारक xj का ?-गुणांक इस कारक के लोच गुणांक से संबंधित है, क्योंकि कारक की भिन्नता का गुणांक परिणामी विशेषता की भिन्नता के गुणांक से संबंधित है। चूँकि, जैसा कि तालिका की अंतिम पंक्ति से देखा जा सकता है। 8.7, सभी कारकों की भिन्नता के गुणांक परिणामी विशेषता की भिन्नता के गुणांक से कम हैं; सभी?-गुणांक लोच गुणांक से कम हैं।
आइए एक उदाहरण के रूप में कारक -सी का उपयोग करके युग्मित और सशर्त रूप से शुद्ध प्रतिगमन गुणांक के बीच संबंध पर विचार करें। Y और x के बीच संबंध के लिए युग्मित रैखिक समीकरण का रूप इस प्रकार है:
y = 3.886x1 – 243.2
X1 पर सशर्त रूप से शुद्ध प्रतिगमन गुणांक युग्मित का केवल 58% है। शेष 42% इस तथ्य के कारण है कि भिन्नता x1 के साथ कारक x2 x3 में भिन्नता होती है, जो बदले में परिणामी गुण को प्रभावित करती है। सभी विशेषताओं के कनेक्शन और उनके जोड़ीवार प्रतिगमन गुणांक कनेक्शन ग्राफ (चित्र 8.2) में प्रस्तुत किए गए हैं।

यदि हम y पर भिन्नता x1 के प्रत्यक्ष और अप्रत्यक्ष प्रभाव का अनुमान जोड़ते हैं, यानी सभी "पथों" (चित्र 8.2) के साथ युग्मित प्रतिगमन गुणांक का उत्पाद, तो हमें मिलता है: 2.26 + 12.55 0.166 + (-0.00128) (- 4.31) + (-0.00128) 17.00 0.166 = 4.344।
यह मान y के साथ युग्म युग्मन गुणांक x1 से भी अधिक है। नतीजतन, समीकरण में शामिल नहीं किए गए कारकों के माध्यम से भिन्नता x1 का अप्रत्यक्ष प्रभाव विपरीत है, कुल मिलाकर:
1 अयवाज़यान एस.ए., मख़ितारियन वी.एस. व्यावहारिक आँकड़े और अर्थमिति के बुनियादी सिद्धांत। विश्वविद्यालयों के लिए पाठ्यपुस्तक. - एम.: यूनिटी, 2008, - 311 पी।
2 जॉनसन जे. अर्थमितीय विधियाँ। - एम.: सांख्यिकी, 1980। - 282s.
3 डफ़र्टी के. अर्थमिति का परिचय। - एम.: इन्फ्रा-एम, 2004, - 354 पी।
4 ड्रेयर एन., स्मिथ जी., एप्लाइड रिग्रेशन विश्लेषण। - एम.: वित्त और सांख्यिकी, 2006, - 191 पी।
5 मैग्नस वाई.आर., कार्तीशेव पी.के., पेरेसेट्स्की ए.ए. अर्थमिति। प्रारंभिक पाठ्यक्रम.-एम.: डेलो, 2006, - 259 पी.
इकोनोमेट्रिक्स/एड पर 6 कार्यशाला। आई.आई. एलिसेवा। - एम.: वित्त और सांख्यिकी, 2004, - 248 पी।
7 अर्थमिति/एड. आई.आई. एलिसेवा। - एम.: वित्त और सांख्यिकी, 2004, - 541 पी।
8 क्रेमर एन., पुटको बी. इकोनोमेट्रिक्स। - एम.: यूनिटी-दाना, 200, - 281 पी।
अयवाज़यान एस.ए., मख़ितारियन वी.एस. व्यावहारिक आँकड़े और अर्थमिति के बुनियादी सिद्धांत। विश्वविद्यालयों के लिए पाठ्यपुस्तक. - एम.: यूनिटी, 2008, - पी. 23.
क्रेमर एन., पुटको बी. इकोनोमेट्रिक्स.- एम.: यूनिटी-दाना, 200, - पी.64
ड्रेयर एन., स्मिथ जी., एप्लाइड रिग्रेशन विश्लेषण। - एम.: वित्त और सांख्यिकी, 2006, - पृष्ठ57।
अर्थमिति/एड पर कार्यशाला। आई.आई. एलिसेवा। - एम.: वित्त और सांख्यिकी, 2004, - पी. 172।
पियर्सन सहसंबंध परीक्षण पैरामीट्रिक आंकड़ों की एक विधि है जो आपको दो मात्रात्मक संकेतकों के बीच एक रैखिक संबंध की उपस्थिति या अनुपस्थिति को निर्धारित करने के साथ-साथ इसकी निकटता और सांख्यिकीय महत्व का मूल्यांकन करने की अनुमति देती है। दूसरे शब्दों में, पियर्सन सहसंबंध परीक्षण आपको यह निर्धारित करने की अनुमति देता है कि दो चर के मूल्यों में परिवर्तन के बीच कोई रैखिक संबंध है या नहीं। सांख्यिकीय गणनाओं और अनुमानों में, सहसंबंध गुणांक को आमतौर पर इस प्रकार दर्शाया जाता है आर xyया आरएक्सवाई.
1. सहसंबंध मानदंड के विकास का इतिहास
पियर्सन सहसंबंध परीक्षण किसके नेतृत्व में ब्रिटिश वैज्ञानिकों की एक टीम द्वारा विकसित किया गया था कार्ल पियर्सन(1857-1936) 19वीं शताब्दी के 90 के दशक में, दो यादृच्छिक चर के सहप्रसरण के विश्लेषण को सरल बनाने के लिए। कार्ल पियर्सन के अलावा, लोगों ने पियर्सन सहसंबंध मानदंड पर भी काम किया फ्रांसिस एडगेवर्थऔर राफेल वेल्डन.
2. पियर्सन सहसंबंध परीक्षण किसके लिए प्रयोग किया जाता है?
पियर्सन सहसंबंध परीक्षण आपको मात्रात्मक पैमाने पर मापे गए दो संकेतकों के बीच सहसंबंध की निकटता (या ताकत) निर्धारित करने की अनुमति देता है। अतिरिक्त गणनाओं का उपयोग करके, आप यह भी निर्धारित कर सकते हैं कि पहचाना गया संबंध सांख्यिकीय रूप से कितना महत्वपूर्ण है।
उदाहरण के लिए, पियर्सन सहसंबंध मानदंड का उपयोग करके, आप इस सवाल का जवाब दे सकते हैं कि क्या तीव्र श्वसन संक्रमण के दौरान शरीर के तापमान और रक्त में ल्यूकोसाइट्स की सामग्री के बीच, रोगी की ऊंचाई और वजन के बीच, फ्लोराइड सामग्री के बीच कोई संबंध है। पीने का पानी और जनसंख्या में दंत क्षय की घटनाएँ।
3. पियर्सन ची-स्क्वायर परीक्षण लागू करने की शर्तें और सीमाएँ
- तुलनीय संकेतकों को मापा जाना चाहिए मात्रात्मक पैमाना(उदाहरण के लिए, हृदय गति, शरीर का तापमान, प्रति 1 मिलीलीटर रक्त में श्वेत रक्त कोशिका की गिनती, सिस्टोलिक रक्तचाप)।
- पियर्सन सहसंबंध परीक्षण का उपयोग करके, हम केवल निर्धारित कर सकते हैं रैखिक संबंध की उपस्थिति और मजबूतीमात्राओं के बीच. दिशा (प्रत्यक्ष या विपरीत), परिवर्तनों की प्रकृति (सीधा या वक्रता), साथ ही एक चर की दूसरे पर निर्भरता की उपस्थिति सहित संबंध की अन्य विशेषताएं, प्रतिगमन विश्लेषण का उपयोग करके निर्धारित की जाती हैं।
- तुलना की गई मात्राओं की संख्या दो के बराबर होनी चाहिए। तीन या अधिक मापदंडों के संबंध का विश्लेषण करने के मामले में, आपको विधि का उपयोग करना चाहिए कारक विश्लेषण.
- पियर्सन सहसंबंध परीक्षण है पैरामीट्रिक, और इसलिए इसके उपयोग की शर्त है सामान्य वितरणतुलना किए गए चर। यदि उन संकेतकों का सहसंबंध विश्लेषण करना आवश्यक है जिनका वितरण सामान्य से भिन्न होता है, जिसमें क्रमिक पैमाने पर मापे गए संकेतक भी शामिल हैं, तो स्पीयरमैन के रैंक सहसंबंध गुणांक का उपयोग किया जाना चाहिए।
- निर्भरता और सहसंबंध की अवधारणाओं को स्पष्ट रूप से अलग किया जाना चाहिए। मात्राओं की निर्भरता उनके बीच सहसंबंध की उपस्थिति को निर्धारित करती है, लेकिन इसके विपरीत नहीं।
उदाहरण के लिए, बच्चे की लम्बाई उसकी उम्र पर निर्भर करती है, यानी बच्चा जितना बड़ा होगा, वह उतना ही लम्बा होगा। यदि हम अलग-अलग उम्र के दो बच्चों को लें, तो उच्च संभावना के साथ बड़े बच्चे की वृद्धि छोटे बच्चे की तुलना में अधिक होगी। इस घटना को कहा जाता है लत, संकेतकों के बीच कारण-और-प्रभाव संबंध को दर्शाता है। बेशक, उनके बीच भी है सहसंबंध संबंध, जिसका अर्थ है कि एक संकेतक में परिवर्तन के साथ दूसरे संकेतक में भी परिवर्तन होता है।
एक अन्य स्थिति में, बच्चे की ऊंचाई और हृदय गति (एचआर) के बीच संबंध पर विचार करें। जैसा कि ज्ञात है, ये दोनों मूल्य सीधे उम्र पर निर्भर करते हैं, इसलिए ज्यादातर मामलों में, अधिक ऊंचाई (और इसलिए अधिक उम्र) के बच्चों की हृदय गति कम होगी। वह है, सहसंबंध संबंधमनाया जाएगा और काफी अधिक भीड़ हो सकती है। हालाँकि, अगर हम बच्चों को लेते हैं समान आयु, लेकिन अलग-अलग ऊंचाई, तो, सबसे अधिक संभावना है, उनकी हृदय गति नगण्य रूप से भिन्न होगी, और इसलिए हम यह निष्कर्ष निकाल सकते हैं आजादीऊंचाई से हृदय गति.
उपरोक्त उदाहरण से पता चलता है कि सांख्यिकी में मूलभूत अवधारणाओं के बीच अंतर करना कितना महत्वपूर्ण है। संचारऔर निर्भरताएँसही निष्कर्ष निकालने के लिए संकेतक.
4. पियर्सन सहसंबंध गुणांक की गणना कैसे करें?
पियर्सन सहसंबंध गुणांक की गणना निम्न सूत्र का उपयोग करके की जाती है:

5. पियर्सन सहसंबंध गुणांक के मूल्य की व्याख्या कैसे करें?
पियर्सन सहसंबंध गुणांक मूल्यों की व्याख्या उनके निरपेक्ष मूल्यों के आधार पर की जाती है। सहसंबंध गुणांक के संभावित मान 0 से ±1 तक भिन्न होते हैं। rxy का निरपेक्ष मान जितना अधिक होगा, दोनों मात्राओं के बीच संबंध की निकटता उतनी ही अधिक होगी। r xy = 0 संचार की पूर्ण कमी को दर्शाता है। r xy = 1 - एक निरपेक्ष (कार्यात्मक) कनेक्शन की उपस्थिति को इंगित करता है। यदि पियर्सन सहसंबंध मानदंड का मान 1 से अधिक या -1 से कम हो जाता है, तो गणना में एक त्रुटि हुई है।
सहसंबंध की जकड़न, या ताकत का आकलन करने के लिए, आम तौर पर स्वीकृत मानदंड का उपयोग किया जाता है, जिसके अनुसार आरएक्सवाई के पूर्ण मान< 0.3 свидетельствуют о कमज़ोरकनेक्शन, r xy मान 0.3 से 0.7 तक - कनेक्शन के बारे में औसतजकड़न, r xy > 0.7 - o का मान मज़बूतसंचार.
यदि आप उपयोग करते हैं तो सहसंबंध की ताकत का अधिक सटीक अनुमान प्राप्त किया जा सकता है चैडॉक टेबल:
श्रेणी आंकड़ों की महत्तासहसंबंध गुणांक r xy को t-परीक्षण का उपयोग करके किया जाता है, जिसकी गणना निम्न सूत्र का उपयोग करके की जाती है:
![]()
प्राप्त t r मान की तुलना एक निश्चित महत्व स्तर पर महत्वपूर्ण मान और स्वतंत्रता की डिग्री n-2 की संख्या से की जाती है। यदि टी आर टी क्रिट से अधिक है, तो पहचाने गए सहसंबंध के सांख्यिकीय महत्व के बारे में एक निष्कर्ष निकाला जाता है।
6. पियर्सन सहसंबंध गुणांक की गणना का उदाहरण
अध्ययन का उद्देश्य दो मात्रात्मक संकेतकों के बीच सहसंबंध की निकटता और सांख्यिकीय महत्व की पहचान करना, निर्धारित करना था: रक्त में टेस्टोस्टेरोन का स्तर (एक्स) और शरीर में मांसपेशियों का प्रतिशत (वाई)। 5 विषयों (एन = 5) वाले नमूने के प्रारंभिक डेटा को तालिका में संक्षेपित किया गया है।
वैज्ञानिक अनुसंधान में, अक्सर परिणाम और कारक चर (फसल की उपज और वर्षा की मात्रा, लिंग और उम्र के अनुसार सजातीय समूहों में एक व्यक्ति की ऊंचाई और वजन, हृदय गति और शरीर का तापमान) के बीच संबंध खोजने की आवश्यकता होती है। , वगैरह।)।
दूसरे वे संकेत हैं जो उनसे जुड़े लोगों (पहले) में बदलाव में योगदान करते हैं।
सहसंबंध विश्लेषण की अवधारणा
उपरोक्त के आधार पर, हम कह सकते हैं कि सहसंबंध विश्लेषण एक ऐसी विधि है जिसका उपयोग दो या दो से अधिक चर के सांख्यिकीय महत्व के बारे में परिकल्पना का परीक्षण करने के लिए किया जाता है यदि शोधकर्ता उन्हें माप सकता है, लेकिन उन्हें बदल नहीं सकता है।
विचाराधीन अवधारणा की अन्य परिभाषाएँ भी हैं। सहसंबंध विश्लेषण एक प्रसंस्करण विधि है जिसमें चर के बीच सहसंबंध गुणांक का अध्ययन करना शामिल है। इस मामले में, एक जोड़ी या विशेषताओं के कई जोड़े के बीच सहसंबंध गुणांक की तुलना उनके बीच सांख्यिकीय संबंध स्थापित करने के लिए की जाती है। सहसंबंध विश्लेषण एक सख्त कार्यात्मक प्रकृति की वैकल्पिक उपस्थिति के साथ यादृच्छिक चर के बीच सांख्यिकीय निर्भरता का अध्ययन करने की एक विधि है, जिसमें एक यादृच्छिक चर की गतिशीलता दूसरे की गणितीय अपेक्षा की गतिशीलता की ओर ले जाती है।
गलत सहसंबंध की अवधारणा
सहसंबंध विश्लेषण करते समय, यह ध्यान रखना आवश्यक है कि इसे विशेषताओं के किसी भी सेट के संबंध में किया जा सकता है, जो अक्सर एक दूसरे के संबंध में बेतुका होता है। कभी-कभी उनका एक-दूसरे के साथ कोई कारणात्मक संबंध नहीं होता है।
इस मामले में, वे गलत सहसंबंध के बारे में बात करते हैं।
सहसंबंध विश्लेषण की समस्याएं
उपरोक्त परिभाषाओं के आधार पर, हम वर्णित विधि के निम्नलिखित कार्य तैयार कर सकते हैं: दूसरे का उपयोग करके मांगे गए चर में से एक के बारे में जानकारी प्राप्त करना; अध्ययन किए गए चरों के बीच संबंध की निकटता निर्धारित करें।
सहसंबंध विश्लेषण में अध्ययन की जा रही विशेषताओं के बीच संबंध निर्धारित करना शामिल है, और इसलिए सहसंबंध विश्लेषण के कार्यों को निम्नलिखित के साथ पूरक किया जा सकता है:
- उन कारकों की पहचान जिनका परिणामी विशेषता पर सबसे अधिक प्रभाव पड़ता है;
- कनेक्शन के पहले से अज्ञात कारणों की पहचान;
- इसके पैरामीट्रिक विश्लेषण के साथ सहसंबंध मॉडल का निर्माण;
- संचार मापदंडों के महत्व और उनके अंतराल मूल्यांकन का अध्ययन।
सहसंबंध विश्लेषण और प्रतिगमन के बीच संबंध
सहसंबंध विश्लेषण की विधि अक्सर अध्ययन की गई मात्राओं के बीच संबंध की निकटता का पता लगाने तक सीमित नहीं है। कभी-कभी इसे प्रतिगमन समीकरणों के संकलन द्वारा पूरक किया जाता है, जो एक ही नाम के विश्लेषण का उपयोग करके प्राप्त किए जाते हैं, और जो परिणामी और कारक (कारक) विशेषता (विशेषताओं) के बीच सहसंबंध निर्भरता का विवरण प्रस्तुत करते हैं। यह विधि, विचाराधीन विश्लेषण के साथ मिलकर, विधि का निर्माण करती है
विधि का उपयोग करने की शर्तें
प्रभावी कारक एक से कई कारकों पर निर्भर करते हैं। यदि प्रभावी और कारक संकेतकों (कारकों) के मूल्य के बारे में बड़ी संख्या में अवलोकन हैं, तो सहसंबंध विश्लेषण की विधि का उपयोग किया जा सकता है, जबकि अध्ययन के तहत कारक मात्रात्मक होने चाहिए और विशिष्ट स्रोतों में परिलक्षित होने चाहिए। पहले को सामान्य कानून द्वारा निर्धारित किया जा सकता है - इस मामले में, सहसंबंध विश्लेषण का परिणाम पियर्सन सहसंबंध गुणांक है, या, यदि विशेषताएँ इस कानून का पालन नहीं करती हैं, तो स्पीयरमैन रैंक सहसंबंध गुणांक का उपयोग किया जाता है।

सहसंबंध विश्लेषण कारकों के चयन के नियम
इस पद्धति को लागू करते समय, प्रदर्शन संकेतकों को प्रभावित करने वाले कारकों को निर्धारित करना आवश्यक है। उनका चयन इस तथ्य को ध्यान में रखते हुए किया जाता है कि संकेतकों के बीच कारण-और-प्रभाव संबंध होना चाहिए। एक मल्टीफैक्टर सहसंबंध मॉडल बनाने के मामले में, परिणामी संकेतक पर महत्वपूर्ण प्रभाव डालने वाले लोगों का चयन किया जाता है, जबकि सहसंबंध मॉडल में 0.85 से अधिक के युग्म सहसंबंध गुणांक वाले अन्योन्याश्रित कारकों को शामिल नहीं करना बेहतर होता है, साथ ही वे भी जिसके लिए परिणामी पैरामीटर के साथ संबंध रैखिक या कार्यात्मक चरित्र नहीं है।
परिणाम प्रदर्शित हो रहे हैं
सहसंबंध विश्लेषण के परिणाम पाठ और ग्राफिक रूपों में प्रस्तुत किए जा सकते हैं। पहले मामले में, उन्हें सहसंबंध गुणांक के रूप में प्रस्तुत किया जाता है, दूसरे में - एक बिखराव आरेख के रूप में।
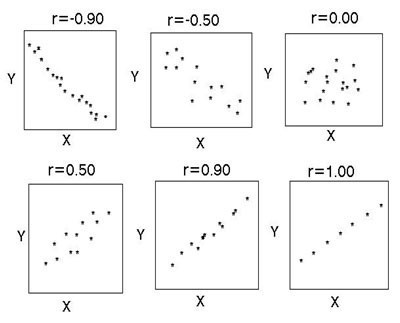
मापदंडों के बीच सहसंबंध की अनुपस्थिति में, आरेख पर बिंदु अव्यवस्थित रूप से स्थित होते हैं, कनेक्शन की औसत डिग्री को क्रम की एक बड़ी डिग्री की विशेषता होती है और मध्यिका से चिह्नित निशानों की अधिक या कम समान दूरी की विशेषता होती है। एक मजबूत कनेक्शन सीधा होता है और r=1 पर डॉट प्लॉट एक सपाट रेखा होती है। विपरीत सहसंबंध ग्राफ़ की दिशा में ऊपरी बाएं से निचले दाएं कोने तक भिन्न होता है, सीधा सहसंबंध - निचले बाएं से ऊपरी दाएं कोने तक भिन्न होता है।
स्कैटर प्लॉट का 3डी प्रतिनिधित्व
पारंपरिक 2डी स्कैटर प्लॉट डिस्प्ले के अलावा, सहसंबंध विश्लेषण का 3डी ग्राफिकल प्रतिनिधित्व अब उपयोग किया जाता है।

स्कैटरप्लॉट मैट्रिक्स का भी उपयोग किया जाता है, जो सभी युग्मित प्लॉट्स को मैट्रिक्स प्रारूप में एक ही आकृति में प्रदर्शित करता है। n वेरिएबल्स के लिए, मैट्रिक्स में n पंक्तियाँ और n कॉलम होते हैं। आई-वें पंक्ति और जे-वें कॉलम के चौराहे पर स्थित चार्ट वेरिएबल Xi बनाम Xj का एक प्लॉट है। इस प्रकार, प्रत्येक पंक्ति और स्तंभ एक आयाम है, एक एकल कक्ष दो आयामों का स्कैटरप्लॉट प्रदर्शित करता है।

कनेक्शन की मजबूती का आकलन करना
सहसंबंध कनेक्शन की निकटता सहसंबंध गुणांक (आर) द्वारा निर्धारित की जाती है: मजबूत - आर = ±0.7 से ±1, मध्यम - आर = ±0.3 से ±0.699, कमजोर - आर = 0 से ±0.299। यह वर्गीकरण सख्त नहीं है. यह आंकड़ा थोड़ा अलग आरेख दिखाता है।

सहसंबंध विश्लेषण पद्धति का उपयोग करने का एक उदाहरण
ब्रिटेन में एक दिलचस्प अध्ययन किया गया। यह धूम्रपान और फेफड़ों के कैंसर के बीच संबंध के लिए समर्पित है, और सहसंबंध विश्लेषण के माध्यम से किया गया था। यह अवलोकन नीचे प्रस्तुत किया गया है।
व्यावसायिक समूह | मृत्यु दर |
|
किसान, वनवासी और मछुआरे | ||
खनिक और खदान श्रमिक | ||
गैस, कोक और रसायन के निर्माता | ||
कांच और चीनी मिट्टी के निर्माता | ||
भट्टियों, फोर्ज, फाउंड्री और रोलिंग मिलों के श्रमिक | ||
इलेक्ट्रिकल और इलेक्ट्रॉनिक्स कर्मचारी | ||
इंजीनियरिंग और संबंधित व्यवसाय | ||
लकड़ी उद्योग | ||
चर्मकार | ||
कपड़ा श्रमिक | ||
काम के कपड़े के निर्माता | ||
भोजन, पेय और तंबाकू उद्योगों में श्रमिक | ||
कागज और प्रिंट निर्माता | ||
अन्य उत्पादों के निर्माता | ||
बिल्डर्स | ||
चित्रकार और सज्जाकार | ||
स्थिर इंजन, क्रेन आदि के चालक। | ||
ऐसे श्रमिक जो अन्यत्र शामिल नहीं हैं | ||
परिवहन और संचार कर्मचारी | ||
गोदाम कर्मचारी, स्टोरकीपर, पैकर्स और भरने वाली मशीन श्रमिक | ||
कार्यालयीन कर्मचारी | ||
सेलर्स | ||
खेल और मनोरंजन कार्यकर्ता | ||
प्रशासक और प्रबंधक | ||
पेशेवर, तकनीशियन और कलाकार |
हम सहसंबंध विश्लेषण शुरू करते हैं। स्पष्टता के लिए, समाधान को ग्राफिकल विधि से शुरू करना बेहतर है, जिसके लिए हम एक स्कैटर आरेख का निर्माण करेंगे।

यह सीधा संबंध दर्शाता है. हालाँकि, अकेले ग्राफिकल विधि के आधार पर कोई स्पष्ट निष्कर्ष निकालना मुश्किल है। इसलिए, हम सहसंबंध विश्लेषण करना जारी रखेंगे। सहसंबंध गुणांक की गणना का एक उदाहरण नीचे प्रस्तुत किया गया है।
सॉफ़्टवेयर का उपयोग करना (एमएस एक्सेल को एक उदाहरण के रूप में नीचे वर्णित किया जाएगा), हम सहसंबंध गुणांक निर्धारित करते हैं, जो 0.716 है, जिसका अर्थ है अध्ययन के तहत मापदंडों के बीच एक मजबूत संबंध। आइए संबंधित तालिका का उपयोग करके प्राप्त मूल्य की सांख्यिकीय विश्वसनीयता निर्धारित करें, जिसके लिए हमें 25 जोड़े मानों में से 2 घटाने की आवश्यकता है, परिणामस्वरूप हमें 23 मिलता है और तालिका में इस पंक्ति का उपयोग करके हम r को p = 0.01 के लिए महत्वपूर्ण पाते हैं (चूंकि ये चिकित्सा डेटा हैं, एक अधिक सख्त निर्भरता, अन्य मामलों में पी=0.05 पर्याप्त है), जो इस सहसंबंध विश्लेषण के लिए 0.51 है। उदाहरण से पता चला कि परिकलित r महत्वपूर्ण r से अधिक है, और सहसंबंध गुणांक का मान सांख्यिकीय रूप से विश्वसनीय माना जाता है।
सहसंबंध विश्लेषण करते समय सॉफ़्टवेयर का उपयोग करना
वर्णित प्रकार की सांख्यिकीय डेटा प्रोसेसिंग सॉफ़्टवेयर, विशेष रूप से एमएस एक्सेल का उपयोग करके की जा सकती है। सहसंबंध में फ़ंक्शंस का उपयोग करके निम्नलिखित मापदंडों की गणना करना शामिल है:
1. सहसंबंध गुणांक CORREL फ़ंक्शन (array1; array2) का उपयोग करके निर्धारित किया जाता है। Array1,2 - परिणामी और कारक चर के मानों के अंतराल का सेल।
रैखिक सहसंबंध गुणांक को पियर्सन सहसंबंध गुणांक भी कहा जाता है, और इसलिए, एक्सेल 2007 से शुरू करके, आप समान सरणियों के साथ फ़ंक्शन का उपयोग कर सकते हैं।
एक्सेल में सहसंबंध विश्लेषण का ग्राफिकल प्रदर्शन "स्कैटर प्लॉट" चयन के साथ "चार्ट" पैनल का उपयोग करके किया जाता है।
प्रारंभिक डेटा निर्दिष्ट करने के बाद, हमें एक ग्राफ़ मिलता है।
2. छात्र के टी-टेस्ट का उपयोग करके जोड़ीवार सहसंबंध गुणांक के महत्व का आकलन करना। टी-मानदंड के परिकलित मूल्य की तुलना इस सूचक के सारणीबद्ध (महत्वपूर्ण) मूल्य के साथ विचाराधीन पैरामीटर के मूल्यों की संबंधित तालिका से की जाती है, जो महत्व के निर्दिष्ट स्तर और स्वतंत्रता की डिग्री की संख्या को ध्यान में रखता है। यह अनुमान STUDISCOVER (प्रायिकता; डिग्री_ऑफ़_फ्रीडम) फ़ंक्शन का उपयोग करके किया जाता है।
3. युग्म सहसंबंध गुणांक का मैट्रिक्स। विश्लेषण डेटा विश्लेषण उपकरण का उपयोग करके किया जाता है, जिसमें सहसंबंध का चयन किया जाता है। जोड़ी सहसंबंध गुणांक का सांख्यिकीय मूल्यांकन सारणीबद्ध (महत्वपूर्ण) मूल्य के साथ इसके पूर्ण मूल्य की तुलना करके किया जाता है। जब गणना की गई जोड़ीदार सहसंबंध गुणांक महत्वपूर्ण एक से अधिक हो जाती है, तो हम संभाव्यता की दी गई डिग्री को ध्यान में रखते हुए कह सकते हैं कि रैखिक संबंध के महत्व के बारे में शून्य परिकल्पना को अस्वीकार नहीं किया गया है।
अंत में
वैज्ञानिक अनुसंधान में सहसंबंध विश्लेषण पद्धति का उपयोग हमें विभिन्न कारकों और प्रदर्शन संकेतकों के बीच संबंध निर्धारित करने की अनुमति देता है। यह ध्यान में रखना आवश्यक है कि एक उच्च सहसंबंध गुणांक एक बेतुके जोड़े या डेटा के सेट से प्राप्त किया जा सकता है, और इसलिए इस प्रकार का विश्लेषण डेटा के पर्याप्त बड़े सरणी पर किया जाना चाहिए।
आर का परिकलित मूल्य प्राप्त करने के बाद, एक निश्चित मूल्य की सांख्यिकीय विश्वसनीयता की पुष्टि करने के लिए इसकी तुलना महत्वपूर्ण आर से करने की सलाह दी जाती है। सहसंबंध विश्लेषण मैन्युअल रूप से सूत्रों का उपयोग करके, या सॉफ़्टवेयर का उपयोग करके, विशेष रूप से एमएस एक्सेल में किया जा सकता है। यहां आप सहसंबंध विश्लेषण के अध्ययन किए गए कारकों और परिणामी विशेषता के बीच संबंधों को दृश्य रूप से दर्शाने के उद्देश्य से एक स्कैटर आरेख भी बना सकते हैं।
जैसा कि बार-बार उल्लेख किया गया है, अध्ययन के तहत चर के बीच सहसंबंध की उपस्थिति या अनुपस्थिति के बारे में एक सांख्यिकीय निष्कर्ष निकालने के लिए, नमूना सहसंबंध गुणांक के महत्व की जांच करना आवश्यक है। इस तथ्य के कारण कि सहसंबंध गुणांक सहित सांख्यिकीय विशेषताओं की विश्वसनीयता, नमूना आकार पर निर्भर करती है, ऐसी स्थिति उत्पन्न हो सकती है जब सहसंबंध गुणांक का मूल्य पूरी तरह से नमूने में यादृच्छिक उतार-चढ़ाव से निर्धारित होता है जिसके आधार पर इसकी गणना की जाती है। . यदि चरों के बीच कोई महत्वपूर्ण संबंध है, तो सहसंबंध गुणांक शून्य से काफी भिन्न होना चाहिए। यदि अध्ययन के अंतर्गत चरों के बीच कोई सहसंबंध नहीं है, तो जनसंख्या सहसंबंध गुणांक ρ शून्य के बराबर है। व्यावहारिक अनुसंधान में, एक नियम के रूप में, वे नमूना टिप्पणियों पर आधारित होते हैं। किसी भी सांख्यिकीय विशेषता की तरह, नमूना सहसंबंध गुणांक एक यादृच्छिक चर है, यानी इसके मान एक ही नाम के जनसंख्या पैरामीटर (सहसंबंध गुणांक का सही मूल्य) के आसपास यादृच्छिक रूप से बिखरे हुए हैं। चरों के बीच सहसंबंध के अभाव में वाई और एक्सजनसंख्या में सहसंबंध गुणांक शून्य है। लेकिन प्रकीर्णन की यादृच्छिक प्रकृति के कारण, ऐसी स्थितियाँ मौलिक रूप से संभव हैं जब इस जनसंख्या के नमूनों से गणना किए गए कुछ सहसंबंध गुणांक शून्य से भिन्न होंगे।
क्या देखे गए अंतरों को नमूने में यादृच्छिक उतार-चढ़ाव के लिए जिम्मेदार ठहराया जा सकता है, या क्या वे उन स्थितियों में एक महत्वपूर्ण बदलाव को दर्शाते हैं जिनके तहत चर के बीच संबंध बने थे? यदि नमूना सहसंबंध गुणांक के मान संकेतक की यादृच्छिक प्रकृति के कारण बिखराव क्षेत्र में आते हैं, तो यह किसी रिश्ते की अनुपस्थिति का प्रमाण नहीं है। अधिकतम यही कहा जा सकता है कि अवलोकन संबंधी डेटा चरों के बीच किसी संबंध की अनुपस्थिति से इनकार नहीं करता है। लेकिन यदि नमूना सहसंबंध गुणांक का मान उल्लिखित बिखरने वाले क्षेत्र के बाहर है, तो वे निष्कर्ष निकालते हैं कि यह शून्य से काफी अलग है, और हम मान सकते हैं कि चर के बीच वाई और एक्सएक सांख्यिकीय रूप से महत्वपूर्ण संबंध है. विभिन्न आँकड़ों के वितरण के आधार पर इस समस्या को हल करने के लिए उपयोग किए जाने वाले मानदंड को महत्व मानदंड कहा जाता है।
महत्व परीक्षण प्रक्रिया शून्य परिकल्पना के निर्माण के साथ शुरू होती है एच0 . सामान्य शब्दों में, यह है कि नमूना पैरामीटर और जनसंख्या पैरामीटर के बीच कोई महत्वपूर्ण अंतर नहीं है। वैकल्पिक परिकल्पना एच1 बात यह है कि इन मापदंडों के बीच महत्वपूर्ण अंतर हैं। उदाहरण के लिए, जब किसी जनसंख्या में सहसंबंध का परीक्षण किया जाता है, तो शून्य परिकल्पना यह होती है कि वास्तविक सहसंबंध गुणांक शून्य है ( ह0: ρ = 0). यदि, परीक्षण के परिणामस्वरूप, यह पता चलता है कि शून्य परिकल्पना स्वीकार्य नहीं है, तो नमूना सहसंबंध गुणांक आरबहुत खूबशून्य से काफी भिन्न (शून्य परिकल्पना खारिज कर दी जाती है और विकल्प स्वीकार कर लिया जाता है)। एच1).दूसरे शब्दों में, यह धारणा कि जनसंख्या में यादृच्छिक चर असंबंधित हैं, निराधार मानी जानी चाहिए। इसके विपरीत, यदि महत्व परीक्षण के आधार पर शून्य परिकल्पना स्वीकार की जाती है, अर्थात। आरबहुत खूबयादृच्छिक प्रकीर्णन के अनुमेय क्षेत्र में है, तो जनसंख्या में असंबद्ध चर की धारणा को संदिग्ध मानने का कोई कारण नहीं है।
एक महत्व परीक्षण में, शोधकर्ता एक महत्व स्तर α निर्धारित करता है जो कुछ व्यावहारिक विश्वास प्रदान करता है कि गलत निष्कर्ष केवल बहुत ही दुर्लभ मामलों में निकाले जाएंगे। महत्व स्तर इस संभावना को व्यक्त करता है कि शून्य परिकल्पना ह0अस्वीकार कर दिया गया जबकि यह वास्तव में सत्य है। स्पष्ट रूप से, इस संभावना को यथासंभव छोटा चुनना समझदारी है।
नमूना विशेषता के वितरण को ज्ञात करें, जो जनसंख्या पैरामीटर का निष्पक्ष अनुमान है। चयनित महत्व स्तर α इस वितरण के वक्र के नीचे छायांकित क्षेत्रों से मेल खाता है (चित्र 24 देखें)। वितरण वक्र के नीचे अछायांकित क्षेत्र संभाव्यता निर्धारित करता है पी = 1 - α . छायांकित क्षेत्रों के नीचे एक्स-अक्ष पर खंडों की सीमाओं को महत्वपूर्ण मान कहा जाता है, और खंड स्वयं महत्वपूर्ण क्षेत्र, या परिकल्पना अस्वीकृति का क्षेत्र बनाते हैं।
परिकल्पना परीक्षण प्रक्रिया में, अवलोकनों के परिणामों से गणना की गई नमूना विशेषता की तुलना संबंधित महत्वपूर्ण मूल्य से की जाती है। इस मामले में, एक तरफा और दो तरफा महत्वपूर्ण क्षेत्रों के बीच अंतर करना चाहिए। महत्वपूर्ण क्षेत्र को निर्दिष्ट करने का रूप सांख्यिकीय अनुसंधान में समस्या के निरूपण पर निर्भर करता है। एक दो-तरफा महत्वपूर्ण क्षेत्र आवश्यक है, जब एक नमूना पैरामीटर और एक जनसंख्या पैरामीटर की तुलना करते समय, उनके बीच विसंगति के पूर्ण मूल्य का अनुमान लगाना आवश्यक होता है, अर्थात, अध्ययन किए गए मूल्यों के बीच सकारात्मक और नकारात्मक दोनों अंतर होते हैं दिलचस्पी। जब यह सुनिश्चित करना आवश्यक होता है कि औसतन एक मान दूसरे से सख्ती से अधिक या कम है, तो एक तरफा महत्वपूर्ण क्षेत्र (दाएं या बाएं तरफा) का उपयोग किया जाता है। यह बिल्कुल स्पष्ट है कि समान महत्वपूर्ण मान के लिए एक तरफा महत्वपूर्ण क्षेत्र का उपयोग करते समय महत्व का स्तर दो तरफा महत्वपूर्ण क्षेत्र का उपयोग करने से कम होता है। यदि नमूना विशेषता का वितरण सममित है,
चावल। 24. शून्य परिकल्पना H0 का परीक्षण
तब दो तरफा महत्वपूर्ण क्षेत्र का महत्व स्तर α के बराबर है, और एक तरफा - (चित्र 24 देखें)। आइए हम स्वयं को समस्या के सामान्य सूत्रीकरण तक ही सीमित रखें। सांख्यिकीय परिकल्पनाओं के परीक्षण के लिए सैद्धांतिक आधार पर अधिक विस्तृत जानकारी विशेष साहित्य में पाई जा सकती है। नीचे हम विभिन्न प्रक्रियाओं के निर्माण पर ध्यान दिए बिना केवल उनके महत्व मानदंड का संकेत देंगे।
जोड़ी सहसंबंध गुणांक के महत्व की जांच करके, अध्ययन के तहत घटनाओं के बीच सहसंबंध की उपस्थिति या अनुपस्थिति स्थापित की जाती है। कनेक्शन के अभाव में, जनसंख्या सहसंबंध गुणांक शून्य (ρ = 0) है। परीक्षण प्रक्रिया शून्य और वैकल्पिक परिकल्पनाओं के निर्माण से शुरू होती है:
ह0: नमूना सहसंबंध गुणांक के बीच अंतर आर और ρ = 0 महत्वहीन है,
एच 1: के बीच अंतर आरऔर ρ = 0 महत्वपूर्ण है, और इसलिए चर के बीच परऔर एक्सएक महत्वपूर्ण संबंध है. वैकल्पिक परिकल्पना का तात्पर्य है कि हमें दो-तरफा महत्वपूर्ण क्षेत्र का उपयोग करने की आवश्यकता है।
धारा 8.1 में पहले ही उल्लेख किया गया था कि नमूना सहसंबंध गुणांक, कुछ मान्यताओं के तहत, एक यादृच्छिक चर के साथ जुड़ा हुआ है टी, साथ छात्र वितरण का पालन करना एफ = एन- स्वतंत्रता की 2 डिग्री. नमूना परिणामों से सांख्यिकी की गणना की गई
किसी दिए गए महत्व स्तर α पर छात्र वितरण तालिका से निर्धारित महत्वपूर्ण मूल्य के साथ तुलना की जाती है औरएफ = एन- स्वतंत्रता की 2 डिग्री. मानदंड लागू करने का नियम इस प्रकार है: यदि | टी| >tf,ए, फिर महत्व स्तर α पर शून्य परिकल्पना अस्वीकृत, अर्थात चरों के बीच संबंध महत्वपूर्ण है; अगर | टी| ≤tf,ए, तो महत्व स्तर α पर शून्य परिकल्पना स्वीकार की जाती है। मूल्य विचलन आर ρ = 0 से यादृच्छिक भिन्नता को जिम्मेदार ठहराया जा सकता है। नमूना डेटा विचाराधीन परिकल्पना को बहुत संभव और प्रशंसनीय बताता है, यानी कनेक्शन की अनुपस्थिति की परिकल्पना आपत्तियां नहीं उठाती है।
किसी परिकल्पना के परीक्षण की प्रक्रिया यदि आँकड़ों के बजाय बहुत सरल हो जाती है टीसहसंबंध गुणांक के महत्वपूर्ण मूल्यों का उपयोग करें, जिसे (8.38) में प्रतिस्थापित करके छात्र वितरण की मात्राओं के माध्यम से निर्धारित किया जा सकता है। टी= tf, ए और आर= ρ एफ, ए:
![]() (8.39)
(8.39)
महत्वपूर्ण मूल्यों की विस्तृत तालिकाएँ हैं, जिनका एक अंश इस पुस्तक के परिशिष्ट में दिया गया है (तालिका 6 देखें)। इस मामले में परिकल्पना का परीक्षण करने का नियम निम्नलिखित है: यदि आर> ρ एफ, और तब हम यह दावा कर सकते हैं कि चरों के बीच संबंध महत्वपूर्ण है। अगर आर≤आरएफ,ए, तो हम अवलोकन परिणामों को कनेक्शन की अनुपस्थिति की परिकल्पना के अनुरूप मानते हैं।
;  ;
;  .
.
आइए अब नमूना मानक विचलन के मूल्यों की गणना करें:
https://pandia.ru/text/78/148/images/image443_0.gif' width='413' ऊंचाई='60 src='>.
दसवीं कक्षा के विद्यार्थियों के बीच https://pandia.ru/text/78/148/images/image434_0.gif" width="25" ऊंचाई="24"> के बीच सहसंबंध, गणित में प्रदर्शन का औसत स्तर जितना अधिक होगा, और इसके विपरीत।
2. सहसंबंध गुणांक के महत्व की जाँच करना
चूँकि नमूना गुणांक की गणना नमूना डेटा से की जाती है, यह एक यादृच्छिक चर है . यदि , तो सवाल उठता है: क्या इसे और https://pandia.ru/text/78/148/images/image301_1.gif" width="29" ऊंचाई="25 src=" के बीच वास्तव में मौजूदा रैखिक संबंध द्वारा समझाया गया है >.gif' width='27' ऊंचाई='25'>: (यदि सहसंबंध चिह्न ज्ञात नहीं है); या एक तरफा https://pandia.ru/text/78/148/images/image448_0.gif" width=”43” ऊंचाई=”23 src=”>.gif” width=”43” ऊंचाई=”23 src => (यदि सहसंबंध का संकेत पहले से निर्धारित किया जा सकता है)।
विधि 1.परिकल्पना का परीक्षण करने के लिए इसका उपयोग किया जाता है https://pandia.ru/text/78/148/images/image150_1.gif" width=”11” ऊंचाई=”17 src=”>-सूत्र के अनुसार छात्र का टी-टेस्ट
https://pandia.ru/text/78/148/images/image406_0.gif" width=”13” ऊंचाई=”15”>.gif” width=”36 ऊंचाई=25” ऊंचाई=”25”>.gif " width = "17" ऊँचाई = "16"> और दो-तरफा मानदंड के लिए स्वतंत्रता की डिग्री की संख्या।
महत्वपूर्ण क्षेत्र असमानता द्वारा दिया गया है ![]() .
.
यदि https://pandia.ru/text/78/148/images/image455_0.gif' width='99' ऊंचाई='29 src='>, तो शून्य परिकल्पना खारिज कर दी जाती है। हम निष्कर्ष निकालते हैं:
§ दोतरफा वैकल्पिक परिकल्पना के लिए - सहसंबंध गुणांक शून्य से काफी भिन्न है;
§ एकतरफ़ा परिकल्पना के लिए - एक सांख्यिकीय रूप से महत्वपूर्ण सकारात्मक (या नकारात्मक) सहसंबंध है।
विधि 2.आप भी उपयोग कर सकते हैं सहसंबंध गुणांक के महत्वपूर्ण मूल्यों की तालिका, जिससे हम स्वतंत्रता की डिग्री की संख्या द्वारा सहसंबंध गुणांक के महत्वपूर्ण मान का पता लगाते हैं https://pandia.ru/text/78/148/images/image367_1.gif" width="17 ऊंचाई=16" ऊंचाई='16'>.
यदि https://pandia.ru/text/78/148/images/image459_0.gif" width=”101” ऊंचाई=”29 src=”>, तो यह निष्कर्ष निकाला जाता है कि सहसंबंध गुणांक 0 से काफी भिन्न है और एक सांख्यिकीय रूप से महत्वपूर्ण सहसंबंध है.
इस प्रकार, कुछ घटनाएँ एक साथ, लेकिन एक-दूसरे से स्वतंत्र रूप से (संयुक्त घटनाएँ) घटित या बदल सकती हैं ( असत्यप्रतिगमन)। अन्य - एक-दूसरे के साथ नहीं, बल्कि अधिक जटिल कारण-और-प्रभाव संबंध के अनुसार कार्य-कारण संबंध में रहना ( अप्रत्यक्षप्रतिगमन)। इस प्रकार, एक महत्वपूर्ण सहसंबंध गुणांक के साथ, कारण-और-प्रभाव संबंध की उपस्थिति के बारे में अंतिम निष्कर्ष केवल अध्ययन के तहत समस्या की बारीकियों को ध्यान में रखते हुए बनाया जा सकता है।
उदाहरण 2.उदाहरण 1 में परिकलित नमूना सहसंबंध गुणांक का महत्व निर्धारित करें।
समाधान।
आइए हम एक परिकल्पना प्रस्तुत करें: कि सामान्य जनसंख्या में कोई सहसंबंध नहीं है। चूँकि उदाहरण 1 को हल करने के परिणामस्वरूप सहसंबंध का चिह्न निर्धारित होता है - सहसंबंध सकारात्मक है, वैकल्पिक परिकल्पना फॉर्म का एक तरफा है https://pandia.ru/text/78/148/images/image448_0.gif "चौड़ाई = "43" ऊँचाई = "23 स्रोत = >>।
आइए मानदंड का अनुभवजन्य मूल्य ज्ञात करें:
https://pandia.ru/text/78/148/images/image461_0.gif" width=”167 ऊंचाई=20” ऊंचाई=”20”>, के बराबर महत्व स्तर का चयन करें। तालिका के अनुसार “महत्वपूर्ण मूल्य विभिन्न महत्व स्तरों के लिए छात्र के परीक्षण में'' हम महत्वपूर्ण मूल्य पाते हैं।
चूंकि https://pandia.ru/text/78/148/images/image434_0.gif" width=”25 ऊंचाई=24” ऊंचाई=”24”> और गणित में प्रदर्शन का औसत स्तर, सांख्यिकीय रूप से महत्वपूर्ण सहसंबंध है .
परीक्षण कार्य
1. कृपया कम से कम दो सही उत्तरों को चिह्नित करें। नमूना सहसंबंध गुणांक के महत्व का परीक्षण उस परिकल्पना के सांख्यिकीय परीक्षण पर आधारित है जो...
1) सामान्य जनसंख्या में कोई सहसंबंध नहीं है
2) नमूना सहसंबंध गुणांक के शून्य से अंतर को केवल नमूने की यादृच्छिकता द्वारा समझाया गया है
3) सहसंबंध गुणांक 0 से काफी भिन्न है
4) नमूना सहसंबंध गुणांक के शून्य से अंतर आकस्मिक नहीं है
2. यदि नमूना रैखिक सहसंबंध गुणांक है, तो एक विशेषता का बड़ा मान किसी अन्य विशेषता के बड़े मान से मेल खाता है।
1) औसतन
3) अधिकांश अवलोकनों में
4) कभी-कभी
3. नमूना सहसंबंध गुणांक https://pandia.ru/text/78/148/images/image465_0.gif" width='64' ऊंचाई='23 src='> (नमूना आकार और 0.05 के महत्व स्तर के लिए)। क्या यह संभव है क्या यह कहा जा सकता है कि मनोवैज्ञानिक लक्षणों के बीच सांख्यिकीय रूप से महत्वपूर्ण सकारात्मक सहसंबंध है?
5. मनोवैज्ञानिक विशेषताओं के बीच एक रैखिक संबंध की ताकत की पहचान करने के कार्य में नमूना सहसंबंध गुणांक पाया जाए https://pandia.ru/text/78/148/images/image466_0.gif" width=”52 ऊंचाई=20 " ऊँचाई = "20"> और 0.05 का महत्व स्तर)। क्या हम कह सकते हैं कि नमूना सहसंबंध गुणांक के शून्य से अंतर केवल नमूने की यादृच्छिकता से समझाया गया है?
विषय 3. रैंक सहसंबंध गुणांक और संघ
1. रैंक सहसंबंध गुणांक https://pandia.ru/text/78/148/images/image130_3.gif" width=”21 ऊंचाई=19” ऊंचाई=”19”> और. विशेषताओं के मूल्यों की संख्या (संकेतक, विषय, गुण) , लक्षण) कोई भी हो सकते हैं, लेकिन उनकी संख्या समान होनी चाहिए।
विषयों | ||||
विशेषता रैंक | ||||
विशेषता रैंक |
आइए हम https://pandia.ru/text/78/148/images/image470_0.gif" width="319" ऊंचाई="66"> का उपयोग करके प्रत्येक विषय के लिए दो चर के रैंक के बीच अंतर को दर्शाते हैं,
रैंक की गई सुविधाओं और संकेतकों के मूल्यों की संख्या कहां है।
रैंक सहसंबंध गुणांक -1 से +1 तक के मान लेता हैऔर इसे पियर्सन सहसंबंध गुणांक का त्वरित अनुमान लगाने के साधन के रूप में देखा जाता है।
के लिए स्पीयरमैन रैंक सहसंबंध गुणांक के महत्व का परीक्षण करना (यदि मानों की संख्या https://pandia.ru/text/78/148/images/image472_0.gif' width='55' ऊंचाई='29'> संख्या और महत्व के स्तर पर निर्भर करती है। यदि अनुभवजन्य मूल्य अधिक है, तो महत्व के स्तर पर, यह तर्क दिया जा सकता है कि संकेत सहसंबंध से संबंधित हैं।
उदाहरण 1।मनोवैज्ञानिक यह पता लगाता है कि गणित और भौतिकी में छात्रों के प्रदर्शन के परिणाम कैसे संबंधित हैं, जिसके परिणाम अंतिम नाम से क्रमबद्ध श्रृंखला के रूप में प्रस्तुत किए जाते हैं।
विद्यार्थी | जोड़ |
||||||||||
अकादमिक प्रदर्शन अंक शास्त्र | |||||||||||
अकादमिक प्रदर्शन भौतिकी में | |||||||||||
रैंकों के बीच वर्ग अंतर |
आइए योग की गणना करें, फिर स्पीयरमैन रैंक सहसंबंध गुणांक बराबर है:
की जाँच करें पाए गए रैंक सहसंबंध गुणांक का महत्व. आइए तालिका का उपयोग करके स्पीयरमैन रैंक सहसंबंध गुणांक के महत्वपूर्ण मान खोजें (परिशिष्ट देखें):
https://pandia.ru/text/78/148/images/image480_0.gif" width=”72″ ऊँचाई=”25”> मान = 0.64 और मान 0.79 से अधिक है। यह इंगित करता है कि मान इसके अंतर्गत आता है सहसंबंध गुणांक के महत्व का क्षेत्र। इसलिए, यह तर्क दिया जा सकता है कि स्पीयरमैन रैंक सहसंबंध गुणांक 0 से काफी अलग है; इसका मतलब है कि गणित और भौतिकी में छात्र के प्रदर्शन के परिणाम एक सकारात्मक सहसंबंध से जुड़े हुए हैं . गणित में प्रदर्शन और भौतिकी में प्रदर्शन के बीच एक महत्वपूर्ण सकारात्मक सहसंबंध है: गणित में जितना बेहतर प्रदर्शन, औसतन भौतिकी में परिणाम उतना ही बेहतर और इसके विपरीत।
पियर्सन और स्पीयरमैन सहसंबंध गुणांक की तुलना करते हुए, हम ध्यान दें कि पियर्सन सहसंबंध गुणांक मूल्यों को सहसंबंधित करता है मात्रा, और स्पीयरमैन सहसंबंध गुणांक मान है रैंकये मात्राएँ, इसलिए पियर्सन और स्पीयरमैन गुणांक के मान अक्सर मेल नहीं खाते हैं।
मनोवैज्ञानिक अनुसंधान में प्राप्त प्रयोगात्मक सामग्री की अधिक संपूर्ण समझ के लिए, पियर्सन और स्पीयरमैन दोनों के अनुसार गुणांक की गणना करने की सलाह दी जाती है।
टिप्पणी. की उपस्थिति में समान रैंकरैंक श्रृंखला में और रैंक सहसंबंध गुणांक की गणना के लिए सूत्र के अंश में, शब्द जोड़े जाते हैं - "रैंक के लिए सुधार":  ;
;  ,
,
जहां https://pandia.ru/text/78/148/images/image130_3.gif" width="21" ऊंचाई="19">;
https://pandia.ru/text/78/148/images/image165_1.gif" width=”16” ऊंचाई=”19”>.
इस मामले में, रैंक सहसंबंध गुणांक की गणना करने का सूत्र https://pandia.ru/text/78/148/images/image485_0.gif" width="16" ऊंचाई="19"> का रूप लेता है।
एसोसिएशन गुणांक लागू करने की शर्तें.
1. तुलना की जा रही विशेषताओं को द्विभाजित पैमाने पर मापा जाता है।
2..gif' width='21' ऊंचाई='19'>, प्रतीक 0 और 1 द्वारा इंगित, तालिका में दिखाए गए हैं।
अवलोकन संख्या |
