Shpërndarja e njëtrajtshme e rastësishme. Konvertimi i një ndryshoreje të rastësishme të shpërndarë në mënyrë uniforme në një variabël të shpërndarë normalisht
Si shembull i një ndryshoreje të rastësishme të vazhdueshme, merrni parasysh një ndryshore të rastësishme X të shpërndarë në mënyrë uniforme në intervalin (a; b). Themi se ndryshorja e rastësishme X të shpërndara në mënyrë të barabartë në intervalin (a; b), nëse dendësia e shpërndarjes së tij nuk është konstante në këtë interval:
Nga kushti i normalizimit përcaktojmë vlerën e konstantës c. Zona nën kurbën e densitetit të shpërndarjes duhet të jetë e barabartë me një, por në rastin tonë është zona e një drejtkëndëshi me bazë (b - α) dhe lartësi c (Fig. 1). 
Oriz. 1 Dendësia uniforme e shpërndarjes
Nga këtu gjejmë vlerën e konstantës c: ![]()
Pra, dendësia e një ndryshoreje të rastësishme të shpërndarë në mënyrë uniforme është e barabartë me 
Tani le të gjejmë funksionin e shpërndarjes sipas formulës:
1) për ![]()
2) për
3) për 0+1+0=1.
Kështu, 
Funksioni i shpërndarjes është i vazhdueshëm dhe nuk zvogëlohet (Fig. 2). 
Oriz. 2 Funksioni i shpërndarjes së një ndryshoreje të rastësishme të shpërndarë në mënyrë uniforme
Le të gjejmë pritshmëria matematikore e një ndryshoreje të rastësishme të shpërndarë në mënyrë uniforme sipas formulës:
Varianca e shpërndarjes uniforme llogaritet me formulë dhe është e barabartë me
Shembulli #1. Vlera e ndarjes së shkallës së instrumentit matës është 0.2. Leximet e instrumentit janë të rrumbullakosura në ndarjen e plotë më të afërt. Gjeni probabilitetin që të bëhet gabim gjatë leximit: a) më pak se 0,04; b) e madhe 0.02
Zgjidhje. Gabimi i rrumbullakosjes është një ndryshore e rastësishme e shpërndarë në mënyrë uniforme në intervalin midis ndarjeve të numrave të plotë ngjitur. Konsideroni intervalin (0; 0.2) si një ndarje të tillë (Fig. a). Rrumbullakimi mund të kryhet si drejt kufirit të majtë - 0, ashtu edhe drejt së djathtës - 0.2, që do të thotë se një gabim më i vogël ose i barabartë me 0.04 mund të bëhet dy herë, i cili duhet të merret parasysh kur llogaritet probabiliteti: 

P = 0,2 + 0,2 = 0,4
Për rastin e dytë, vlera e gabimit mund të kalojë gjithashtu 0.02 në të dy kufijtë e ndarjes, domethënë mund të jetë ose më e madhe se 0.02 ose më e vogël se 0.18. 
Atëherë probabiliteti i një gabimi si ky:
Shembulli #2. Supozohej se stabiliteti i situatës ekonomike në vend (mungesa e luftërave, fatkeqësive natyrore, etj.) Gjatë 50 viteve të fundit mund të gjykohet nga natyra e shpërndarjes së popullsisë sipas moshës: në një situatë të qetë, ajo duhet të jetë uniforme. Si rezultat i studimit, janë marrë të dhënat e mëposhtme për një nga vendet.
A ka ndonjë arsye për të besuar se ka pasur një situatë të paqëndrueshme në vend?Ne e marrim vendimin duke përdorur kalkulatorin Testimi i hipotezës. Tabela për llogaritjen e treguesve.
| Grupet | Intervali i mesit, x i | Sasia, fi | x i * f i | Frekuenca kumulative, S | |x - x cf |*f | (x - x sr) 2 *f | Frekuenca, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
mesatare e ponderuar
Treguesit e variacionit.
Normat Absolute të Variacionit.
Gama e variacionit është ndryshimi midis vlerave maksimale dhe minimale të atributit të serisë primare.
R = X max - X min
R=70 - 0=70
Dispersion- karakterizon masën e përhapjes rreth vlerës mesatare të saj (masa e dispersionit, d.m.th. devijimi nga mesatarja).
Devijimi standard.
Çdo vlerë e serisë ndryshon nga vlera mesatare e 43 me jo më shumë se 23,92
Testimi i hipotezave për llojin e shpërndarjes.
4. Testimi i hipotezës rreth shpërndarje uniforme popullata e përgjithshme.
Për të testuar hipotezën për shpërndarjen uniforme të X, d.m.th. sipas ligjit: f(x) = 1/(b-a) në intervalin (a,b)
nevojshme:
1. Vlerësoni parametrat a dhe b - skajet e intervalit në të cilin janë vërejtur vlerat e mundshme të X, sipas formulave (shenja * tregon vlerësimet e parametrave):
2. Gjeni densitetin e probabilitetit të shpërndarjes së vlerësuar f(x) = 1/(b * - a *)
3. Gjeni frekuencat teorike:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Krahasoni frekuencat empirike dhe teorike duke përdorur testin Pearson, duke supozuar numrin e shkallëve të lirisë k = s-3, ku s është numri i intervaleve fillestare të kampionimit; megjithatë, nëse është bërë një kombinim i frekuencave të vogla, dhe rrjedhimisht edhe vetë intervaleve, atëherë s është numri i intervaleve që mbeten pas kombinimit.
Zgjidhja:
1. Gjeni vlerësimet e parametrave a * dhe b * të shpërndarjes uniforme duke përdorur formulat:
2. Gjeni dendësinë e shpërndarjes uniforme të supozuar:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Gjeni frekuencat teorike:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
n-të e mbetura do të jenë të barabarta:
n s = n*f(x)(x i - x i-1)
| i | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Prandaj, rajoni kritik për këtë statistikë është gjithmonë i djathtë: nëse densiteti i probabilitetit të tij është konstant në këtë segment, dhe jashtë tij është 0 (d.m.th., një ndryshore e rastësishme X fokusuar në segmentin [ a, b], në të cilën ka një dendësi konstante). Sipas këtij përkufizimi, dendësia e një të shpërndarë në mënyrë uniforme në segmentin [ a, b] ndryshore e rastësishme X duket si:
Ku Me ka një numër. Sidoqoftë, është e lehtë ta gjesh atë duke përdorur vetinë e densitetit të probabilitetit për r.v. të përqendruar në intervalin [ a,
b]:
 . Prandaj rrjedh se
. Prandaj rrjedh se  , ku
, ku  . Prandaj, dendësia e shpërndarë në mënyrë uniforme në segmentin [ a,
b] ndryshore e rastësishme X duket si:
. Prandaj, dendësia e shpërndarë në mënyrë uniforme në segmentin [ a,
b] ndryshore e rastësishme X duket si:
 .
.
Për të gjykuar uniformitetin e shpërndarjes së n.s.v. X e mundur nga konsiderata e mëposhtme. Një ndryshore e vazhdueshme e rastësishme ka një shpërndarje uniforme në intervalin [ a, b] nëse merr vlera vetëm nga ky segment dhe çdo numër nga ky segment nuk ka përparësi ndaj numrave të tjerë të këtij segmenti në kuptimin që mund të jetë vlera e kësaj ndryshoreje të rastësishme.
Variablat e rastësishëm me një shpërndarje uniforme përfshijnë variabla të tillë si koha e pritjes së një transporti në një ndalesë (në një interval konstant lëvizjeje, koha e pritjes shpërndahet në mënyrë të barabartë mbi këtë interval), gabimi i rrumbullakimit të numrit në një numër të plotë (i shpërndarë në mënyrë të barabartë më [−0,5 , 0.5 ]) dhe të tjerët.
Lloji i funksionit të shpërndarjes F(x)
a,
b] ndryshore e rastësishme X kërkohet nga dendësia e njohur e probabilitetit f(x)
duke përdorur formulën e lidhjes së tyre  . Si rezultat i llogaritjeve përkatëse, marrim formulën e mëposhtme për funksionin e shpërndarjes F(x)
segment i shpërndarë në mënyrë uniforme [ a,
b] ndryshore e rastësishme X
:
. Si rezultat i llogaritjeve përkatëse, marrim formulën e mëposhtme për funksionin e shpërndarjes F(x)
segment i shpërndarë në mënyrë uniforme [ a,
b] ndryshore e rastësishme X
:
 .
.
Shifrat tregojnë grafikët e densitetit të probabilitetit f(x) dhe funksionet e shpërndarjes f(x) segment i shpërndarë në mënyrë uniforme [ a, b] ndryshore e rastësishme X :


Pritshmëria matematikore, varianca, devijimi standard, mënyra dhe mediana e një segmenti të shpërndarë në mënyrë uniforme [ a, b] ndryshore e rastësishme X llogaritur nga dendësia e probabilitetit f(x) në mënyrën e zakonshme (dhe thjesht për shkak të pamjes së thjeshtë f(x) ). Rezultati është formulat e mëposhtme:
por moda d(X) është çdo numër i intervalit [ a, b].
Le të gjejmë probabilitetin e goditjes së segmentit të shpërndarë në mënyrë uniforme [ a,
b] ndryshore e rastësishme X në interval  , plotësisht i shtrirë brenda [ a,
b]. Duke marrë parasysh formën e njohur të funksionit të shpërndarjes, marrim:
, plotësisht i shtrirë brenda [ a,
b]. Duke marrë parasysh formën e njohur të funksionit të shpërndarjes, marrim:
Kështu, probabiliteti për të goditur segmentin e shpërndarë në mënyrë uniforme [ a,
b] ndryshore e rastësishme X në interval  , plotësisht i shtrirë brenda [ a,
b], nuk varet nga pozicioni i këtij intervali, por varet vetëm nga gjatësia e tij dhe është drejtpërdrejt proporcionale me këtë gjatësi.
, plotësisht i shtrirë brenda [ a,
b], nuk varet nga pozicioni i këtij intervali, por varet vetëm nga gjatësia e tij dhe është drejtpërdrejt proporcionale me këtë gjatësi.
Shembull. Intervali i autobusit është 10 minuta. Sa është probabiliteti që një pasagjer që arrin në një stacion autobusi të presë më pak se 3 minuta për autobusin? Sa është koha mesatare e pritjes për një autobus?
Shpërndarja normale
Kjo shpërndarje më së shpeshti haset në praktikë dhe luan një rol të jashtëzakonshëm në teorinë e probabilitetit dhe statistikat matematikore dhe aplikimet e tyre, pasi që kaq shumë variabla të rastësishëm në shkencat natyrore, ekonomi, psikologji, sociologji, shkenca ushtarake etj. kanë një shpërndarje të tillë. Kjo shpërndarje është ligji kufizues, të cilit i qasen (në kushte të caktuara natyrore) shumë ligje të tjera të shpërndarjes. Me ndihmën e ligjit të shpërndarjes normale përshkruhen edhe dukuri që i nënshtrohen veprimit të shumë faktorëve të rastësishëm të pavarur të çdo natyre dhe çdo ligji të shpërndarjes së tyre. Le të kalojmë te përkufizimet.
Një ndryshore e vazhdueshme e rastësishme quhet e shpërndarë ligji normal (ose ligji Gaussian), nëse densiteti i probabilitetit të tij ka formën:
 ,
,
ku janë numrat A Dhe σ (σ>0 ) janë parametrat e kësaj shpërndarjeje.
Siç është përmendur tashmë, ligji i Gausit i shpërndarjes së variablave të rastësishëm ka aplikime të shumta. Sipas këtij ligji, shpërndahen gabimet e matjes sipas instrumenteve, devijimi nga qendra e objektivit gjatë gjuajtjes, dimensionet e pjesëve të prodhuara, pesha dhe lartësia e njerëzve, reshjet vjetore, numri i të porsalindurve e shumë të tjera.
Formula e mësipërme për densitetin e probabilitetit të një ndryshoreje të rastësishme të shpërndarë normalisht përmban, siç u tha, dy parametra A Dhe σ , dhe për këtë arsye përcakton një familje funksionesh që ndryshojnë në varësi të vlerave të këtyre parametrave. Nëse zbatojmë metodat e zakonshme të analizës matematikore të studimit të funksioneve dhe vizatimit në densitetin e probabilitetit të një shpërndarjeje normale, mund të nxjerrim përfundimet e mëposhtme.

janë pikat e lakimit të tij.
Bazuar në informacionin e marrë, ne ndërtojmë një grafik të densitetit të probabilitetit f(x) shpërndarja normale (quhet kurba Gaussian - figura).

Le të zbulojmë se si ndikon ndryshimi i parametrave A Dhe σ në formën e kurbës Gaussian. Është e qartë (kjo mund të shihet nga formula për densitetin e shpërndarjes normale) se ndryshimi në parametrin A nuk ndryshon formën e kurbës, por vetëm çon në zhvendosjen e saj djathtas ose majtas përgjatë boshtit X. Varësi σ më i vështirë. Nga studimi i mësipërm mund të shihet se si vlera e maksimumit dhe koordinatat e pikave të lakimit varen nga parametri σ . Përveç kësaj, duhet pasur parasysh se për çdo parametër A Dhe σ sipërfaqja nën lakoren Gaussian mbetet e barabartë me 1 (kjo është një veti e përgjithshme e densitetit të probabilitetit). Nga sa u tha del se me rritjen e parametrit σ kurba bëhet më e sheshtë dhe shtrihet përgjatë boshtit X. Figura tregon kthesat Gaussian për vlera të ndryshme të parametrit σ (σ 1 < σ< σ 2 ) dhe të njëjtën vlerë parametri A.

Gjeni kuptimin probabilistik të parametrave A Dhe σ
shpërndarje normale. Tashmë nga simetria e kurbës Gaussian në lidhje me vijën vertikale që kalon nëpër numrin A në bosht Xështë e qartë se vlera mesatare (d.m.th. pritshmëria matematikore M(X)) e një ndryshoreje të rastësishme të shpërndarë normalisht është e barabartë me A. Për të njëjtat arsye, mënyra dhe mediana duhet gjithashtu të jenë të barabarta me numrin a. Llogaritjet e sakta sipas formulave përkatëse e konfirmojnë këtë. Nëse shkruajmë shprehjen e mësipërme për f(x)
zëvendësojnë në formulën e variancës  , pastaj pas llogaritjes (mjaft të vështirë) të integralit, marrim në përgjigje numrin σ
2
. Kështu, për një ndryshore të rastësishme X të shpërndara sipas ligjit normal, janë marrë këto karakteristika kryesore numerike:
, pastaj pas llogaritjes (mjaft të vështirë) të integralit, marrim në përgjigje numrin σ
2
. Kështu, për një ndryshore të rastësishme X të shpërndara sipas ligjit normal, janë marrë këto karakteristika kryesore numerike:
Prandaj, kuptimi probabilistik i parametrave të shpërndarjes normale A Dhe σ tjetër. Nëse r.v. XA Dhe σ A σ.
Tani le të gjejmë funksionin e shpërndarjes F(x)
për një ndryshore të rastësishme X, të shpërndara sipas ligjit normal, duke përdorur shprehjen e mësipërme për densitetin e probabilitetit f(x)
dhe formula  . Gjatë zëvendësimit f(x)
marrim një integral "të pamarrë". Gjithçka që mund të bëhet për të thjeshtuar shprehjen për F(x),
ky është përfaqësimi i këtij funksioni në formën:
. Gjatë zëvendësimit f(x)
marrim një integral "të pamarrë". Gjithçka që mund të bëhet për të thjeshtuar shprehjen për F(x),
ky është përfaqësimi i këtij funksioni në formën:
 ,
,
Ku F(x)- i ashtuquajturi Funksioni Laplace, e cila duket si
 .
.
Integrali në termat e të cilit shprehet funksioni Laplace gjithashtu nuk merret (por për secilën X ky integral mund të llogaritet përafërsisht me ndonjë saktësi të paracaktuar). Sidoqoftë, nuk kërkohet ta llogaritni atë, pasi në fund të çdo libri shkollor mbi teorinë e probabilitetit ekziston një tabelë për përcaktimin e vlerave të funksionit F(x) në një vlerë të caktuar X. Në vijim, do të na duhet vetia e çuditshmërisë së funksionit Laplace: F(−x)=−F(x) për të gjithë numrat X.
Le të gjejmë tani probabilitetin që një r.v i shpërndarë normalisht. X do të marrë një vlerë nga intervali i dhënë numerik (α, β) . Nga vetitë e përgjithshme të funksionit të shpërndarjes Р(α< X< β)= F(β) − F(α) . Zëvendësimi α Dhe β në shprehjen e mësipërme për F(x) , marrim
 .
.
Siç u përmend më lart, nëse r.v. X shpërndahet normalisht me parametra A Dhe σ , atëherë vlera mesatare e tij është e barabartë me A, dhe devijimi standard është i barabartë me σ. Kjo është arsyeja pse mesatare devijimi i vlerave të këtij r.v. kur testohet nga numri A barazohet σ. Por ky është devijimi mesatar. Prandaj, devijime më të mëdha janë gjithashtu të mundshme. Zbulojmë se sa të mundshme janë këto ose ato devijime nga vlera mesatare. Le të gjejmë probabilitetin që vlera e një ndryshoreje të rastësishme të shpërndahet sipas ligjit normal X devijojnë nga mesatarja e saj M(X)=a më pak se një numër δ, d.m.th. R(| X− a|<δ ) : . Kështu,
 .
.
Zëvendësimi në këtë barazi δ=3σ, marrim probabilitetin që vlera e r.v. X(në një provë) do të devijojë nga mesatarja me më pak se tre herë σ (me një devijim mesatar, siç kujtojmë, të barabartë me σ ): (që do të thotë F(3) marrë nga tabela e vlerave të funksionit Laplace). Është pothuajse 1 ! Pastaj probabiliteti i ngjarjes së kundërt (që vlera të devijon të paktën 3σ) është e barabartë me 1 −0.997=0.003 , e cila është shumë afër 0 . Prandaj, kjo ngjarje është "pothuajse e pamundur" − ndodh shumë rrallë (mesatarisht 3 herë jashtë 1000 ). Ky arsyetim është arsyetimi i "rregullit të tre sigmave" të njohur.
Rregulli tre sigma. Ndryshore e rastësishme e shpërndarë normalisht në një test të vetëm praktikisht nuk devijon nga mesatarja e tij më shumë se 3σ.
Edhe një herë theksojmë se bëhet fjalë për një test. Nëse ka shumë prova të një ndryshoreje të rastësishme, atëherë është mjaft e mundur që disa nga vlerat e saj të lëvizin më tej nga mesatarja sesa 3σ. Kjo konfirmon sa vijon
Shembull. Sa është probabiliteti që pas 100 provash të një ndryshoreje të rastësishme të shpërndarë normalisht X të paktën një nga vlerat e tij do të devijojë nga mesatarja me më shumë se tre herë devijimi standard? Po 1000 prova?
Zgjidhje. Lëreni ngjarjen A do të thotë se kur testohet një ndryshore e rastësishme X vlera e tij ka devijuar nga mesatarja me më shumë se 3σ. Siç sapo u zbulua, probabiliteti i kësaj ngjarjeje p=P(A)=0.003. Janë kryer 100 teste të tilla. Ne duhet të gjejmë probabilitetin që ngjarja A ndodhi të paktën herë, d.m.th. erdhi nga 1 para 100 një herë. Ky është një problem tipik i skemës Bernoulli me parametra n=100 (numri i gjykimeve të pavarura), p=0.003(probabiliteti i ngjarjes A në një test) q=1− fq=0.997 . Donte të gjente R 100 (1≤ k≤100) . Në këtë rast, natyrisht, është më e lehtë të gjesh së pari probabilitetin e ngjarjes së kundërt R 100 (0) − probabiliteti që ngjarja A nuk ka ndodhur kurrë (d.m.th. ka ndodhur 0 herë). Duke marrë parasysh lidhjen midis probabiliteteve të vetë ngjarjes dhe të kundërtës së saj, marrim:
Jo aq pak. Mund të ndodhë fare mirë (ndodh mesatarisht në çdo të katërtën seri të tilla testesh). Në 1000 teste sipas të njëjtës skemë, mund të merret se probabiliteti i të paktën një devijimi është më i madh se 3σ, është e barabartë me: . Pra, është e sigurt të presësh për të paktën një devijim të tillë.
Shembull. Gjatësia e meshkujve të një grupmoshe të caktuar zakonisht shpërndahet me pritshmëri matematikore a, dhe devijimi standard σ . Çfarë përqindje e kostumeve k-Rritja duhet të përfshihet në prodhimin total për një grupmoshë të caktuar nëse k- rritja përcaktohet nga kufijtë e mëposhtëm:
1 lartësia : 158 − 164 cm 2 lartësia : 164 - 170 cm 3 lartësia : 170 - 176 cm 4 lartësia : 176 - 182 cm
Zgjidhje. Le ta zgjidhim problemin me vlerat e mëposhtme të parametrave: a=178,σ=6,k=3
. Le të r.v. X
−
gjatësia e një njeriu të zgjedhur rastësisht (shpërndahet sipas gjendjes normalisht me parametrat e dhënë). Gjeni probabilitetin që do t'i duhet një burri i zgjedhur rastësisht 3
rritjes. Përdorimi i çuditshmërisë së funksionit Laplace F(x) dhe një tabelë me vlerat e saj: P (170
Shpërndarja e probabilitetit të një ndryshoreje të rastësishme të vazhdueshme X, i cili merr të gjitha vlerat nga intervali , quhet uniforme, nëse densiteti i probabilitetit të tij në këtë segment është konstant, dhe jashtë tij është i barabartë me zero. Kështu, densiteti i probabilitetit të një ndryshoreje të rastësishme të vazhdueshme X, i shpërndarë në mënyrë të barabartë në segment , duket si:

Le të përcaktojmë vlera e pritur, dispersion dhe për një ndryshore të rastësishme me një shpërndarje uniforme.
, ![]() ,
, ![]() .
.
Shembull. Të gjitha vlerat e një ndryshoreje të rastësishme të shpërndarë në mënyrë uniforme qëndrojnë në segment . Gjeni probabilitetin që një ndryshore e rastësishme të bjerë në interval (3;5) .
a=2, b=8,  .
.
Shpërndarja binomiale
Le të prodhohet n testet, dhe probabiliteti i ndodhjes së një ngjarjeje A në çdo test është fq dhe nuk varet nga rezultati i gjykimeve të tjera (gjykimet e pavarura). Meqenëse probabiliteti i ndodhjes së një ngjarjeje A në një test është fq, atëherë probabiliteti i mosndodhjes së tij është i barabartë me q=1-p.
Lëreni ngjarjen A erdhi në n gjykimet m një herë. Kjo ngjarje komplekse mund të shkruhet si produkt:
![]() .
.
Pastaj probabiliteti që n ngjarje testuese A do te vije m koha llogaritet me formulën:
![]() ose
ose ![]() (1)
(1)
Formula (1) quhet Formula e Bernulit.
Le Xështë një ndryshore e rastësishme e barabartë me numrin e dukurive të ngjarjes A V n teste, të cilat marrin vlera me probabilitete:
Ligji që rezulton i shpërndarjes së një ndryshoreje të rastësishme quhet ligji i shpërndarjes binomiale.
| X | m | n | ||||
| P |
Vlera e pritshme, dispersion Dhe devijimi standard Variablat e rastësishëm të shpërndara sipas ligjit binomial përcaktohen nga formula:
, , .
Shembull. Tre të shtëna janë qëlluar në objektiv, dhe probabiliteti për të goditur çdo goditje është 0.8. Ne konsiderojmë një ndryshore të rastësishme X- numri i goditjeve në objektiv. Gjeni ligjin e tij të shpërndarjes, pritshmërinë matematikore, variancën dhe devijimin standard.
p=0.8, q=0.2, n=3, ![]() , ,
, , ![]() .
.
![]() - probabiliteti i 0 goditjeve;
- probabiliteti i 0 goditjeve;
Probabiliteti i një goditjeje;
Probabiliteti i dy goditjeve;
![]() është probabiliteti i tre goditjeve.
është probabiliteti i tre goditjeve.
Ne marrim ligjin e shpërndarjes:
| X | ||||
| P | 0,008 | 0,096 | 0,384 | 0,512 |
Detyrat
1. Një monedhë hidhet 7 herë. Gjeni probabilitetin që të bjerë me kokë poshtë 4 herë.
2. Një monedhë hidhet 8 herë. Gjeni probabilitetin që stema të shfaqet jo më shumë se tre herë.
3. Probabiliteti i goditjes së objektivit gjatë gjuajtjes nga arma p=0.6. Gjeni pritshmërinë matematikore të numrit të përgjithshëm të goditjeve nëse bëhen 10 të shtëna.
4. Gjeni pritshmërinë matematikore të numrit të biletave të lotarisë që do të fitojnë nëse blihen 20 bileta dhe probabiliteti për të fituar për një biletë është 0.3.
Funksioni i shpërndarjes në këtë rast, sipas (5.7), do të marrë formën:
ku: m është pritshmëria matematikore, s është devijimi standard.
Shpërndarja normale quhet edhe Gaussian sipas matematikanit gjerman Gauss. Fakti që një ndryshore e rastësishme ka një shpërndarje normale me parametrat: m,, shënohet si më poshtë: N (m, s), ku: m =a =M ;
Shumë shpesh, në formula, pritshmëria matematikore shënohet me A . Nëse një ndryshore e rastësishme shpërndahet sipas ligjit N(0,1), atëherë quhet vlerë normale e normalizuar ose e standardizuar. Funksioni i shpërndarjes për të ka formën:
|
|
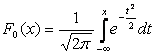 .
.Grafiku i densitetit të shpërndarjes normale, i cili quhet kurba normale ose kurba e Gausit, është paraqitur në figurën 5.4.

Oriz. 5.4. Dendësia normale e shpërndarjes
Përcaktimi i karakteristikave numerike të një ndryshoreje të rastësishme nga dendësia e saj konsiderohet në një shembull.
Shembulli 6.
Një ndryshore e vazhdueshme e rastësishme jepet nga dendësia e shpërndarjes: ![]() .
.
Përcaktoni llojin e shpërndarjes, gjeni pritshmërinë matematikore M(X) dhe variancën D(X).
Duke krahasuar densitetin e dhënë të shpërndarjes me (5.16), mund të konkludojmë se është dhënë ligji normal i shpërndarjes me m =4. Prandaj, pritshmëria matematikore M(X)=4, varianca D(X)=9.
Devijimi standard s=3.
Funksioni Laplace, i cili ka formën:
|
|
 ,
,lidhet me funksionin e shpërndarjes normale (5.17), nga relacioni:
F 0 (x) \u003d F (x) + 0,5.
Funksioni Laplace është tek.
Ф(-x)=-Ф(x).
Vlerat e funksionit Laplace Ф(х) janë tabeluar dhe janë marrë nga tabela sipas vlerës së x (shih Shtojcën 1).
Shpërndarja normale e një variabli të rastësishëm të vazhdueshëm luan një rol të rëndësishëm në teorinë e probabilitetit dhe në përshkrimin e realitetit; është shumë i përhapur në fenomenet e rastësishme natyrore. Në praktikë, shumë shpesh ka variabla të rastësishëm që formohen pikërisht si rezultat i përmbledhjes së shumë termave të rastësishëm. Në veçanti, analiza e gabimeve të matjes tregon se ato janë shuma e llojeve të ndryshme të gabimeve. Praktika tregon se shpërndarja e probabilitetit të gabimeve të matjes është afër ligjit normal.
Duke përdorur funksionin Laplace, mund të zgjidhen problemet e llogaritjes së probabilitetit të rënies në një interval të caktuar dhe një devijim të caktuar të një ndryshoreje normale të rastit.
Kjo çështje ka kohë që është studiuar në detaje dhe metoda e koordinatave polare, e propozuar nga George Box, Mervyn Muller dhe George Marsaglia në vitin 1958, është përdorur më gjerësisht. Kjo metodë ju lejon të merrni një palë ndryshoresh të pavarura të rastësishme të shpërndara normalisht me mesatare 0 dhe variancë 1 si më poshtë:
Aty ku Z 0 dhe Z 1 janë vlerat e dëshiruara, s \u003d u 2 + v 2, dhe u dhe v janë ndryshore të rastësishme të shpërndara në mënyrë uniforme në segmentin (-1, 1), të zgjedhura në atë mënyrë që kushti 0 të plotësohet< s < 1.
Shumë i përdorin këto formula pa u menduar, dhe shumë as nuk dyshojnë për ekzistencën e tyre, pasi përdorin zbatime të gatshme. Por ka njerëz që kanë pyetje: “Nga lindi kjo formulë? Dhe pse merrni një palë vlera në të njëjtën kohë? Në vijim do të përpiqem t'u jap një përgjigje të qartë këtyre pyetjeve.
Për të filluar, më lejoni t'ju kujtoj se cila është densiteti i probabilitetit, funksioni i shpërndarjes së një ndryshoreje të rastësishme dhe funksioni i anasjelltë. Supozoni se ekziston një ndryshore e rastësishme shpërndarja e së cilës jepet nga funksioni i densitetit f(x), i cili ka formën e mëposhtme:

Kjo do të thotë që probabiliteti që vlera e kësaj ndryshoreje të rastësishme të jetë në intervalin (A, B) është e barabartë me sipërfaqen e zonës së hijezuar. Dhe si pasojë, zona e të gjithë zonës së hijes duhet të jetë e barabartë me unitetin, pasi në çdo rast vlera e ndryshores së rastësishme do të bjerë në domenin e funksionit f.
Funksioni i shpërndarjes së një ndryshoreje të rastësishme është një integral i funksionit të densitetit. Dhe në këtë rast, forma e saj e përafërt do të jetë si më poshtë:

Këtu kuptimi është se vlera e ndryshores së rastësishme do të jetë më e vogël se A me probabilitet B. Dhe si rezultat, funksioni nuk zvogëlohet kurrë dhe vlerat e tij qëndrojnë në intervalin.
Një funksion invers është një funksion që kthen argumentin e funksionit origjinal nëse kaloni vlerën e funksionit origjinal në të. Për shembull, për funksionin x 2, anasjelltas do të jetë funksioni i nxjerrjes së rrënjës, për sin (x) është arcsin (x), etj.
Meqenëse shumica e gjeneratorëve të numrave pseudo të rastësishëm japin vetëm një shpërndarje uniforme në dalje, shpesh bëhet e nevojshme që të konvertohet në ndonjë tjetër. Në këtë rast, për një Gaussian normal:

Baza e të gjitha metodave për shndërrimin e një shpërndarje uniforme në çdo shpërndarje tjetër është metoda e transformimit të anasjelltë. Ajo funksionon si më poshtë. Gjendet një funksion që është i anasjelltë me funksionin e shpërndarjes së kërkuar dhe një ndryshore e rastësishme e shpërndarë në mënyrë uniforme në segmentin (0, 1) i kalohet si argument. Në dalje, marrim një vlerë me shpërndarjen e kërkuar. Për qartësi, këtu është fotografia e mëposhtme.

Kështu, një segment uniform, si të thuash, lyhet në përputhje me shpërndarjen e re, duke u projektuar në një aks tjetër përmes një funksioni të anasjelltë. Por problemi është se integrali i densitetit të shpërndarjes Gaussian nuk është i lehtë për t'u llogaritur, kështu që shkencëtarët e mësipërm duhej të mashtronin.
Ekziston një shpërndarje chi-katrore (shpërndarja Pearson), e cila është shpërndarja e shumës së katrorëve të k variablave normale të rastësishme të pavarura. Dhe në rastin kur k = 2, kjo shpërndarje është eksponenciale.

Kjo do të thotë që nëse një pikë në një sistem koordinativ drejtkëndor ka koordinata të rastësishme X dhe Y të shpërndara normalisht, atëherë pas konvertimit të këtyre koordinatave në sistemin polar (r, θ), katrori i rrezes (distanca nga origjina në pikën) do të shpërndahet në mënyrë eksponenciale, pasi katrori i rrezes është shuma e katrorëve të koordinatave (sipas ligjit të Pitagorës). Dendësia e shpërndarjes së pikave të tilla në aeroplan do të duket kështu:


Meqenëse është i barabartë në të gjitha drejtimet, këndi θ do të ketë një shpërndarje uniforme në intervalin nga 0 në 2π. E kundërta është gjithashtu e vërtetë: nëse specifikoni një pikë në sistemin e koordinatave polar duke përdorur dy ndryshore të rastësishme të pavarura (këndi i shpërndarë në mënyrë uniforme dhe rrezja e shpërndarë në mënyrë eksponenciale), atëherë koordinatat drejtkëndore të kësaj pike do të jenë variabla normale të pavarura të rastit. Dhe tashmë është shumë më e lehtë për të marrë një shpërndarje eksponenciale nga një uniforme, duke përdorur të njëjtën metodë të transformimit të anasjelltë. Ky është thelbi i metodës polare Box-Muller.
Tani le të marrim formulat.
![]() (1)
(1)
Për të marrë r dhe θ, është e nevojshme të gjenerohen dy ndryshore të rastësishme të shpërndara në mënyrë uniforme në segmentin (0, 1) (le t'i quajmë u dhe v), shpërndarja e njërës prej të cilave (le të themi v) duhet të shndërrohet në eksponenciale në merrni rrezen. Funksioni i shpërndarjes eksponenciale duket si ky:
Funksioni i tij i anasjelltë:
![]()
Meqenëse shpërndarja uniforme është simetrike, transformimi do të funksionojë në mënyrë të ngjashme me funksionin
![]()
Nga formula e shpërndarjes chi-katrore rrjedh se λ = 0.5. Ne zëvendësojmë λ, v në këtë funksion dhe marrim katrorin e rrezes, dhe më pas vetë rrezen:

Ne e marrim këndin duke e shtrirë segmentin e njësisë në 2π:
Tani ne zëvendësojmë r dhe θ në formula (1) dhe marrim:
 (2)
(2)
Këto formula janë gati për t'u përdorur. X dhe Y do të jenë të pavarur dhe normalisht të shpërndarë me një variancë 1 dhe një mesatare prej 0. Për të marrë një shpërndarje me karakteristika të tjera, mjafton të shumëzoni rezultatin e funksionit me devijimin standard dhe të shtoni mesataren.
Por është e mundur të shpëtojmë nga funksionet trigonometrike duke specifikuar këndin jo drejtpërdrejt, por indirekt përmes koordinatave drejtkëndore të një pike të rastësishme në një rreth. Pastaj, përmes këtyre koordinatave, do të mund të llogaritet gjatësia e vektorit të rrezes, dhe pastaj të gjendet kosinusi dhe sinusi duke pjesëtuar përkatësisht x dhe y me të. Si dhe pse funksionon?
Ne zgjedhim një pikë të rastësishme nga e shpërndarë në mënyrë uniforme në rrethin e rrezes së njësisë dhe shënojmë katrorin e gjatësisë së vektorit të rrezes së kësaj pike me shkronjën s:

Zgjedhja bëhet duke caktuar koordinatat drejtkëndore të rastësishme x dhe y të shpërndara në mënyrë uniforme në intervalin (-1, 1) dhe duke hedhur poshtë pikat që nuk i përkasin rrethit, si dhe pikën qendrore në të cilën është këndi i vektorit të rrezes. e pa përcaktuar. Kjo do të thotë, kushti 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Ne marrim formulat, si në fillim të artikullit. Disavantazhi i kësaj metode është refuzimi i pikave që nuk përfshihen në rreth. Kjo do të thotë, duke përdorur vetëm 78.5% të variablave të rastit të gjeneruar. Në kompjuterët e vjetër, mungesa e funksioneve trigonometrike ishte ende një avantazh i madh. Tani, kur një udhëzim i procesorit llogarit njëkohësisht sinusin dhe kosinusin në një çast, mendoj se këto metoda mund të konkurrojnë ende.
Personalisht kam edhe dy pyetje:
- Pse vlera e s shpërndahet në mënyrë të barabartë?
- Pse shuma e katrorëve të dy ndryshoreve normale të rastit shpërndahet në mënyrë eksponenciale?

Nëse bëhet një transformim i ngjashëm për një ndryshore normale të rastësishme, atëherë funksioni i densitetit të katrorit të tij do të rezultojë të jetë i ngjashëm me një hiperbolë. Dhe shtimi i dy katrorëve të ndryshoreve normale të rastit është tashmë një proces shumë më kompleks i lidhur me integrimin e dyfishtë. Dhe faktin që rezultati do të jetë një shpërndarje eksponenciale, personalisht, më mbetet ta kontrolloj me një metodë praktike ose ta pranoj si aksiomë. Dhe për ata që janë të interesuar, ju sugjeroj që të njiheni më afër me temën, duke nxjerrë njohuri nga këto libra:
- Wentzel E.S. Teoria e probabilitetit
- Knut D.E. Arti i Programimit Vëllimi 2
Si përfundim, unë do të jap një shembull të zbatimit të një gjeneruesi të numrave të rastësishëm të shpërndarë normalisht në JavaScript:
Funksioni Gauss() ( var gati = false; var sekondë = 0.0; this.next = funksion (mesatar, dev) ( mesatar = mesatar == i pacaktuar ? 0.0: mesatare; dev = dev == i pacaktuar ? 1.0: dev; nëse ( this.ready) ( this.ready = false; return this.second * dev + mean; ) other ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); kjo.e dyta = r * u; kjo. gati = e vërtetë; ktheje r * v * dev + mesatare; ) ) ) g = Gauss i ri (); // krijoni një objekt a = g.next(); // gjeneroni një palë vlerash dhe merrni të parën b = g.next(); // merrni c të dytën = g.next(); // gjeneroni një palë vlerash përsëri dhe merrni të parën
Parametrat mesatarë (pritshmëria matematikore) dhe dev (devijimi standard) janë opsionale. Unë tërheq vëmendjen tuaj për faktin se logaritmi është i natyrshëm.
