Modele matematyczne najprostszych systemów kolejkowych. Funkcje p0(t) i p1(t) określają przebieg przejściowy w jednokanałowym QS i opisują proces QS wykładniczo zbliżającego się do stanu granicznego z charakterystyczną stałą czasową d
23 października 2013 o 14:22Pisk: Modelowanie systemów kolejkowania
- programowanie,
- OOP,
- Programowanie równoległe
Na Habré jest bardzo mało informacji o takim języku programowania jak Squeak. Postaram się o tym porozmawiać w kontekście modelowania systemów kolejkowych. Pokażę jak napisać prostą klasę, opisać jej strukturę i wykorzystać ją w programie, który będzie obsługiwał żądania kilkoma kanałami.
Kilka słów o Squeak
Squeak to otwarta, wieloplatformowa implementacja języka programowania Smalltalk-80 z dynamicznym pisaniem i odśmiecaniem. Interfejs jest dość specyficzny, ale dość wygodny do debugowania i analizy. Squeak jest w pełni zgodny z koncepcją OOP. Wszystko składa się z przedmiotów, nawet struktur jeśli-to-inaczej, na chwilę realizowane z ich pomocą. Cała składnia sprowadza się do wysłania do obiektu komunikatu w postaci:<объект> <сообщение>Każda metoda zawsze zwraca obiekt i można do niego wysłać nową wiadomość.
Squeak jest często wykorzystywany do modelowania procesów, ale może być również wykorzystywany jako narzędzie do tworzenia aplikacji multimedialnych oraz różnorodnych platform edukacyjnych.
Systemy kolejkowe
Systemy kolejkowe (QS) zawierają jeden lub więcej kanałów, które przetwarzają aplikacje z kilku źródeł. Czas obsługi każdego zgłoszenia może być stały lub dowolny, a także odstępy między ich nadejściem. Może to być centrala telefoniczna, pralnia, kasjery w sklepie, biuro pisania itp. Wygląda to mniej więcej tak:
QS obejmuje kilka źródeł, które wchodzą do wspólnej kolejki i są wysyłane do obsługi, gdy kanały przetwarzania stają się wolne. W zależności od specyfiki rzeczywistych systemów, model może zawierać różną liczbę źródeł żądań i kanałów obsługi oraz mieć różne ograniczenia długości kolejki i związanej z tym możliwości utraty żądań (awaria).
Podczas modelowania QS zwykle rozwiązywane są zadania szacowania średniej i maksymalnej długości kolejki, częstotliwości odmowy usługi, średniego obciążenia kanału i określania ich liczby. W zależności od zadania model zawiera bloki oprogramowania do zbierania, gromadzenia i przetwarzania niezbędnych danych statystycznych o zachowaniu procesów. Najczęściej używanymi modelami przepływu zdarzeń w analizie QS są modele regularne i Poissona. Zwykłe charakteryzują się tym samym czasem pomiędzy wystąpieniem zdarzeń, natomiast Poissona są losowe.
Trochę matematyki
W przypadku przepływu Poissona liczba zdarzeń X mieszczący się w przedziale długości τ (tau) w sąsiedztwie punktu t, dystrybuowane zgodnie z prawem Poissona:gdzie a (t, t)- średnia liczba zdarzeń występujących w przedziale czasowym τ .
Średnia liczba zdarzeń występujących w jednostce czasu jest równa λ(t). W związku z tym średnia liczba zdarzeń w przedziale czasu τ , przylegając do chwili czasu t, będzie równa:
![]()
Czas T między dwoma wydarzeniami λ(t) = const = λ dystrybuowane zgodnie z prawem:
Gęstość rozkładu zmiennej losowej T wygląda jak:
Aby otrzymać pseudolosowe ciągi Poissona przedziałów czasowych t ja Rozwiązać równanie:
gdzie r ja jest liczbą losową równomiernie rozłożoną w przedziale.
W naszym przypadku daje to wyrażenie:
![]()
Generując liczby losowe, możesz pisać całe tomy. Tutaj, aby wygenerować liczby całkowite równomiernie rozłożone w przedziale, używamy następującego algorytmu:
gdzie R i- kolejna losowa liczba całkowita;
R- jakaś duża liczba pierwsza (np. 2311);
Q- liczba całkowita - górna granica przedziału, na przykład 2 21 = 2097152;
Rem- operacja uzyskania reszty z dzielenia liczb całkowitych.
Wartość początkowa R0 zwykle ustawiane arbitralnie, na przykład za pomocą odczytów timera:
Całkowity czasSekundy
Aby uzyskać liczby równomiernie rozłożone w przedziale, używamy operatora języka:
Klasa Rand
Aby uzyskać liczby losowe równomiernie rozłożone w przedziale, tworzymy klasę - generator liczb rzeczywistych:Float variableWordSubclass: #Rand "nazwa klasy" instanceVariableNames: "" "zmienne instancji" classVariableNames: "R" "zmienne klas" poolDictionaries: "" "wspólne słowniki" category: "Przykład" "nazwa kategorii"
Metody:
"Inicjalizacja" init R:= Czas totalSeconds.next "Następna liczba pseudolosowa" next R:= (R * 2311 + 1) rem: 2097152. ^(R/2097152) asFloat
Aby ustawić stan początkowy czujnika, wyślij wiadomość Rand init.
Aby uzyskać kolejny losowy numer, wyślij Rand dalej.
Program do rozpatrywania wniosków
Jako prosty przykład zróbmy następujące. Załóżmy, że musimy zasymulować utrzymanie regularnego przepływu żądań z jednego źródła z losowym odstępem czasu między żądaniami. Istnieją dwa kanały o różnej wydajności, które umożliwiają obsługę aplikacji odpowiednio w 2 i 7 jednostkach czasu. Konieczna jest rejestracja liczby żądań obsługiwanych przez każdy kanał w przedziale 100 jednostek czasu.Kod pisku
"Deklarowanie zmiennych tymczasowych" | proc1 proc2 t1 t2 s1 s2 sysKolejka priorytetowa kontynuacja r | "Początkowe ustawienia zmiennych" Rand init. SysTime:= 0. s1:= 0. s2:= 0. t1:= -1. t2:= -1. kontynuuj:=prawda. sysPriority:= Priorytet procesora activeProcess. Kolejka "Aktualny priorytet":= Semafor nowy. „Claim Queue Model” „Create Process — Channel Model 1” s1:= s1 + 1. proc1 suspend."Wstrzymaj proces w oczekiwaniu na zakończenie usługi" ].proc1:= nil."Usuń odwołanie do procesu 1" ]priority: (sysPriority + 1)) wznowić. "Nowy priorytet jest większy niż tło" "Utwórz proces - model kanału 2" .proc2:= zero.] priorytet: (sysPriority + 1)) wznów. „Ciągły opis głównego procesu i modelu źródłowego” whileTrue: [ r:= (Rand next * 10) zaokrąglone. (r = 0) jeśli prawda: . ((SysTime rem: r) = 0) ifTrue: . „Wyślij żądanie” „Przełącznik procesu usługi” (t1 = SysTime) ifTrue: . (t2 = SysTime) ifTrue: . SysTime:= SysTime + 1. „Czas modelu tyka” ]. PopUpMenu "Pokaż stan licznika żądań" informuje: "proc1: ",(s1 printString),", proc2: ",(s2 printString). kontynuuj:= fałsz.
Na starcie widzimy, że proces 1 zdołał przetworzyć 31 żądań, a proces 2 tylko 11:
Klasyfikacja, podstawowe pojęcia, elementy modelu, obliczanie głównych charakterystyk.
Przy rozwiązywaniu problemów racjonalnej organizacji handlu, usług konsumenckich, magazynowania itp. bardzo przydatna jest interpretacja działań struktury produkcji jak systemy kolejkowe, tj. system, w którym z jednej strony stale pojawiają się prośby o wykonanie jakiejkolwiek pracy, a z drugiej strony te prośby są stale zaspokajane.
Każda SMO zawiera cztery elementy: strumień przychodzący, kolejka, serwer, strumień wychodzący.
wymóg(klient, aplikacja) w QS jest każde indywidualne żądanie wykonania jakiejkolwiek pracy.
Usługa to wykonanie prac w celu zaspokojenia nadchodzącego zapotrzebowania. Obiekt realizujący utrzymanie wymagań nazywany jest urządzeniem serwisowym (urządzeniem) lub kanałem serwisowym.
Czas obsługi to okres, w którym wymóg usługi jest spełniony, tj. okres od początku świadczenia usługi do jej zakończenia. Okres od momentu wejścia żądania do systemu do uruchomienia usługi nazywany jest czasem oczekiwania na usługę. Czas oczekiwania na usługę wraz z czasem obsługi to czas przebywania wymagania w systemie.
SMO są klasyfikowane według różnych kryteriów..
1. W zależności od liczby kanałów serwisowych QS są podzielone na jednokanałowe i wielokanałowe.
2. W zależności od warunków oczekiwania wymóg uruchomienia usługi rozróżnia QS ze stratami (awariami) i QS z oczekiwaniem.
W QS z utratą popytu, które pojawiły się w momencie, gdy wszystkie urządzenia są zajęte konserwacją, są odrzucane, są tracone dla tego systemu i nie mają wpływu na dalszy proces konserwacji. Klasycznym przykładem awarii systemu jest centrala telefoniczna - żądanie połączenia jest odrzucane, jeśli wywoływany jest zajęty.
W przypadku systemu z awariami główną cechą efektywności działania jest prawdopodobieństwo awarii lub średni odsetek żądań, które pozostają nieobsłużone.
W CMO z żądaniem oczekującym, otrzymany w momencie, gdy wszystkie urządzenia są zajęte serwisowaniem, nie opuszcza systemu, ale ustawia się w kolejce i czeka, aż jeden z kanałów zostanie zwolniony. Po zwolnieniu kolejnego urządzenia jedna z aplikacji w kolejce jest natychmiast przyjmowana do obsługi.
W przypadku QS z oczekiwaniem głównymi cechami są matematyczne oczekiwania dotyczące długości kolejki i czasu oczekiwania.
Przykładem systemu „poczekaj i zobacz” jest proces przywracania telewizorów w warsztacie naprawczym.
Istnieją systemy, które leżą między tymi dwiema grupami ( mieszane CMO). Charakteryzują się obecnością pewnych warunków pośrednich: ograniczeniami mogą być ograniczenia czasu oczekiwania na rozpoczęcie usługi, długości kolejki itp.
Jako charakterystykę wydajności prawdopodobieństwo awarii można wykorzystać zarówno w systemach ze stratami (lub charakterystykach czasu oczekiwania), jak iw systemach z oczekiwaniem.
3. Zgodnie z dziedziną usług, QS dzielą się na systemy z priorytetem usługi i systemy bez priorytetu usługi.
Żądania mogą być obsługiwane w kolejności, w jakiej są odbierane, losowo lub na podstawie ustalonych priorytetów.
4. QS może być jednofazowy i wielofazowy.
W jednofazowy systemy, wymagania są obsługiwane przez kanały tego samego typu (na przykład pracownicy tego samego zawodu) bez przenoszenia ich z jednego kanału do drugiego, w wielozakresowy systemy takie transfery są możliwe.
5. W zależności od lokalizacji źródła wymagań, QS dzieli się na otwarte (gdy źródło wymagania znajduje się poza systemem) i zamknięte (gdy źródło znajduje się w samym systemie).
Do Zamknięte obejmują systemy, w których napływ wymagań jest ograniczony. Na przykład brygadzista, którego zadaniem jest ustawianie maszyn w warsztacie, musi je okresowo serwisować. Każda ustawiana maszyna staje się potencjalnym źródłem wymagań konfiguracyjnych w przyszłości. W takich systemach łączna liczba roszczeń w obiegu jest skończona i najczęściej stała.
Jeśli źródło zasilania ma nieskończoną liczbę wymagań, wówczas systemy nazywane są otwarty. Przykładami takich systemów są sklepy, kasy biletowe dworców, portów itp. W przypadku tych systemów przychodzący przepływ żądań można uznać za nieograniczony.
Metody i modele badania QS można warunkowo podzielić na analityczne i statystyczne (modelowanie symulacyjne procesów kolejkowania).
Metody analityczne pozwalają na uzyskanie charakterystyk układu jako niektórych funkcji parametrów jego funkcjonowania. Umożliwia to przeprowadzenie jakościowej analizy wpływu poszczególnych czynników na efektywność QS.
Niestety, analitycznie można rozwiązać tylko dość ograniczony zakres problemów teorii kolejek. Mimo ciągłego rozwoju metod analitycznych, w wielu rzeczywistych przypadkach rozwiązanie analityczne jest albo niemożliwe do uzyskania, albo wynikające z nich zależności okazują się na tyle złożone, że ich analiza staje się samodzielnym trudnym zadaniem. Dlatego, aby móc zastosować metody rozwiązań analitycznych, trzeba uciekać się do różnych założeń upraszczających, co w pewnym stopniu kompensuje możliwość zastosowania analizy jakościowej ostatecznych zależności (w tym przypadku oczywiście jest to konieczne, aby przyjęte założenia nie zniekształcały rzeczywistego obrazu procesu).
Obecnie teoretycznie najbardziej rozwinięte i wygodne w praktycznych zastosowaniach są metody rozwiązywania takich problemów kolejkowania, w których przepływ wymagań jest najprostszy ( Poissona).
Dla najprostszego przepływu częstotliwość przyjmowania wymagań do systemu jest zgodna z prawem Poissona, czyli prawdopodobieństwo przybycia w czasie t równym k wymagań jest określone wzorem:
gdzie λ jest parametrem przepływu (patrz poniżej).
Najprostszy przepływ ma trzy główne właściwości: zwykły, stacjonarny i bez efektu wtórnego.
Pospolitość przepływ oznacza praktyczną niemożność jednoczesnego otrzymania dwóch lub więcej wymagań. Na przykład prawdopodobieństwo, że kilka maszyn z grupy maszyn obsługiwanych przez zespół mechaników ulegnie awarii w tym samym czasie, jest dość małe.
Stacjonarny nazywa pływ, dla którego matematyczne oczekiwanie liczby roszczeń wprowadzanych do systemu w jednostce czasu (oznaczone przez λ) nie zmienia się w czasie. Zatem prawdopodobieństwo, że w danym przedziale czasu Δt wejdzie do systemu określona liczba klientów, zależy od jego wartości, a nie od jej pochodzenia na osi czasu.
Brak efektu końcowego! oznacza, że liczba klientów wchodzących do systemu przed czasem t nie określa, ilu klientów wejdzie do systemu w czasie t + Δt.
Na przykład, jeśli zerwanie nici nastąpi w danym momencie na krośnie i zostanie ono wyeliminowane przez tkacza, to nie przesądza to, czy w następnym momencie nastąpi nowe zerwanie na krośnie, tym bardziej, że tak jest nie wpływają na prawdopodobieństwo przerwy na innych maszynach.
Ważną cechą QS jest czas obsługi wymagań w systemie. Czas obsługi jest z reguły zmienną losową i dlatego można go opisać prawem dystrybucji. Prawo wykładnicze uzyskało największy rozkład w teorii, a zwłaszcza w zastosowaniach praktycznych. Dla tego prawa funkcja rozkładu prawdopodobieństwa ma postać:
F(t) \u003d 1 - e -μt,
tych. prawdopodobieństwo, że czas obsługi nie przekroczy pewnej wartości t jest określone wzorem (1 - e -μt), gdzie μ jest parametrem wykładniczego prawa czasu obsługi wymagań w systemie - odwrotność średniej czas obsługi, tj. .
Rozważ analityczne modele QS z oczekiwaniem(najczęstszy QS, w którym żądania odebrane w momencie, gdy wszystkie jednostki usługowe są zajęte, są kolejkowane i obsługiwane, gdy jednostki usługowe stają się wolne).
Zadania z kolejkami są typowe w warunkach produkcyjnych, na przykład przy organizacji prac regulacyjnych i naprawczych, podczas konserwacji wielu maszyn itp.
Ogólny opis problemu jest następujący.
System składa się z n kanałów obsługujących. Każdy z nich może jednocześnie obsłużyć tylko jedno żądanie. System otrzymuje najprostszy (Poissona) przepływ wymagań z parametrem λ. Jeżeli w momencie nadejścia kolejnego żądania do systemu jest już w obsłudze co najmniej n żądań (tzn. wszystkie kanały są zajęte), to żądanie to trafia do kolejki i czeka na rozpoczęcie obsługi.
Czas obsługi każdego wymagania t about jest zmienną losową, która jest zgodna z rozkładem wykładniczym z parametrem μ.
Jak wspomniano powyżej, QS z oczekiwaniem można podzielić na dwie duże grupy: zamkniętą i otwartą.
Cechy funkcjonowania każdego z tych dwóch typów systemów narzucają swój własny odcień stosowanemu aparatowi matematycznemu. Obliczenie charakterystyk różnych typów QS można przeprowadzić na podstawie obliczenia prawdopodobieństw stanów QS (formuła Erlanga).
Ponieważ system jest zamknięty, do zgłoszenia problemu należy dodać warunek: przepływ przychodzących żądań jest ograniczony, tj. system kolejkowy nie może mieć jednocześnie więcej niż m żądań (m to liczba obsługiwanych obiektów).
Jako główne kryteria charakteryzujące jakość funkcjonowania rozpatrywanego systemu wybierzemy: 1) stosunek średniej długości kolejki do największej liczby wymagań jednocześnie występujących w systemie obsługi – współczynnik przestoju obsługiwanego obiektu; 2) stosunek średniej liczby nieaktywnych obsługujących kanałów do ich całkowitej liczby jest stosunkiem bezczynności obsługiwanego kanału.
Rozważmy obliczenie niezbędnych charakterystyk probabilistycznych (wskaźniki wydajności) zamkniętego QS.
1. Prawdopodobieństwo wystąpienia k wymagań w systemie, pod warunkiem, że ich liczba nie przekracza liczby urządzeń serwisowych n:
P k = α k P 0 , (1 ≤ k ≤ n),
gdzie ![]()
λ to częstotliwość (intensywność) przyjmowania wymagań do systemu z jednego źródła;
Średni czas trwania usługi jednego wymagania;
m - największa możliwa liczba wymagań, które są jednocześnie w systemie obsługującym;
n to liczba urządzeń serwisowych;
P 0 - prawdopodobieństwo, że wszystkie urządzenia serwisowe są wolne.
2. Prawdopodobieństwo, że w systemie jest k wymagań, pod warunkiem, że ich liczba jest większa niż liczba urządzeń serwisowych:
P k = α k P 0 , (n ≤ k ≤ m),
gdzie ![]()
3. Prawdopodobieństwo, że wszystkie serwery są wolne, określa się na podstawie warunku
![]()
W konsekwencji,

4. Średnia liczba żądań oczekujących na uruchomienie usługi (średnia długość kolejki):
![]()
5. Wskaźnik przestojów w oczekiwaniu na usługę:
6. Prawdopodobieństwo, że wszystkie urządzenia serwisowe są zajęte:
7. Średnia liczba wymagań w systemie obsługi (obsługiwane i oczekujące na obsługę):
![]()
8. Wskaźnik całkowitego czasu przestoju wymagań do obsługi i oczekiwania na obsługę:
9. Średni czas bezczynności reklamacji w kolejce serwisowej:
10. Średnia liczba bezpłatnych uczestników:

11. Wskaźnik przestojów pojazdów serwisowych:
12. Prawdopodobieństwo, że liczba żądań oczekujących na obsługę jest większa niż pewna liczba B (prawdopodobieństwo, że w kolejce obsługi jest więcej niż B żądań):
![]()
W wielu dziedzinach gospodarki, finansów, produkcji i życia codziennego ważną rolę odgrywają systemy realizujące wielokrotne wykonywanie zadań tego samego typu. Takie systemy nazywają się systemy kolejkowe ( CMO ). Przykładami CMO są: banki różnego typu, organizacje ubezpieczeniowe, inspektoraty podatkowe, usługi audytorskie, różne systemy komunikacji, kompleksy załadunkowo-rozładunkowe, stacje benzynowe, różne przedsiębiorstwa i organizacje z sektora usług.
3.1.1 Ogólne informacje o systemach kolejkowych
Każdy QS jest przeznaczony do obsługi (wykonywania) określonego przepływu aplikacji (wymagań), które w większości trafiają do systemu nie regularnie, ale w przypadkowych momentach. Obsługa zgłoszeń również trwa nie przez stały, z góry określony czas, ale losowo, co zależy od wielu przypadkowych, czasem nam nieznanych przyczyn. Po obsłużeniu żądania kanał zostaje zwolniony i jest gotowy do przyjęcia kolejnego żądania. Losowy charakter przepływu aplikacji i czas ich obsługi prowadzi do nierównomiernego obciążenia QS. W pewnych przedziałach czasowych na wejściu QS mogą się kumulować żądania, co prowadzi do przeciążenia QS, natomiast w innych przedziałach czasowych, przy wolnych kanałach (urządzenia serwisowe), na wejściu QS nie będzie żadnych żądań, co prowadzi do niedociążenie systemu QS, tj. bezczynności swoich kanałów. Aplikacje, które gromadzą się na wejściu do QS, albo „wpadają” do kolejki, albo z jakiegoś powodu niemożność dalszego pozostawania w kolejce pozostawiają QS bez obsługi.
Rysunek 3.1 przedstawia schemat QS.
Głównymi elementami (funkcjami) systemów kolejkowych są:
Węzeł serwisowy (blok),
przepływ aplikacji,
Skręcać oczekiwanie na obsługę (dyscyplina kolejki).
Blok serwisowy zaprojektowane do wykonywania działań zgodnie z wymaganiami przychodzącego systemu Aplikacje.
Ryż. 3.1 Schemat systemu kolejkowego
Drugim elementem systemów kolejkowych jest wejście przepływ aplikacji. Aplikacje trafiają do systemu losowo. Zazwyczaj przyjmuje się, że strumień wejściowy podlega pewnemu prawu prawdopodobieństwa przez czas trwania odstępów między dwoma kolejno napływającymi żądaniami, a prawo dystrybucji uważa się za niezmienione przez wystarczająco długi czas. Źródło aplikacji jest nieograniczone.
Trzeci składnik to dyscyplina kolejkowa. Ta cecha opisuje kolejność obsługi zgłoszeń przychodzących do systemu. Ponieważ blok obsługujący ma zwykle ograniczoną pojemność, a żądania przychodzą nieregularnie, okresowo tworzona jest kolejka żądań oczekujących na obsługę, a czasami system obsługujący jest bezczynny, czekając na żądania.
Główną cechą procesów kolejkowania jest losowość. W tym przypadku istnieją dwie strony współdziałające: serwowane i serwujące. Losowe zachowanie przynajmniej jednej ze stron prowadzi do losowego charakteru przebiegu procesu obsługi jako całości. Źródłem losowości w interakcji tych dwóch stron są zdarzenia losowe dwojakiego rodzaju.
1. Wygląd zgłoszenia (wymagania) do obsługi. Przyczyną przypadkowości tego wydarzenia jest często masowość potrzeby obsługi.
2. Koniec doręczenia kolejnego żądania. Przyczynami losowości tego zdarzenia są zarówno losowość rozpoczęcia usługi, jak i losowy czas trwania samej usługi.
Te zdarzenia losowe tworzą system dwóch przepływów w QS: wejściowego przepływu obsługiwanych żądań i wyjściowego przepływu obsłużonych żądań.
Wynikiem interakcji tych przepływów zdarzeń losowych jest liczba zgłoszeń w SJ w danym momencie, co zwykle nazywa się stan systemu.
Każdy QS, w zależności od swoich parametrów charakteru przepływu aplikacji, ilości kanałów obsługi i ich wydajności, na zasadach organizacji pracy, ma pewną sprawność funkcjonowania (pojemność), co pozwala mu z powodzeniem radzić sobie z przepływ wniosków.
Specjalny obszar matematyki stosowanej teoria masyusługa (TMO)– zajmuje się analizą procesów w systemach kolejkowych. Przedmiotem badań teorii kolejkowania jest QS.
Celem teorii kolejkowania jest wypracowanie zaleceń dotyczących racjonalnej konstrukcji QS, racjonalnej organizacji ich pracy oraz regulacji przepływu aplikacji w celu zapewnienia wysokiej wydajności QS. Aby osiągnąć ten cel, wyznaczane są zadania teorii kolejkowania, które polegają na ustaleniu zależności sprawności funkcjonowania systemu QS od jego organizacji.
Zadania teorii kolejkowania mają charakter optymalizacyjny i docelowo mają na celu określenie takiego wariantu systemu, który zapewni minimum całkowitych kosztów z oczekiwania na usługę, straty czasu i zasobów na obsługę oraz z nieczynnej obsługi jednostka. Znajomość tych cech zapewnia menedżerowi informacje umożliwiające opracowanie ukierunkowanego wpływu na te cechy w celu zarządzania efektywnością procesów kolejkowych.
Jako charakterystykę efektywności funkcjonowania SJ wybiera się zwykle trzy główne grupy wskaźników (najczęściej przeciętnych):
Wskaźniki skuteczności wykorzystania QS:
Bezwzględna przepustowość QS to średnia liczba żądań, które QS może obsłużyć w jednostce czasu.
Względna przepustowość systemu QS to stosunek średniej liczby wniosków obsługiwanych przez system jakości w jednostce czasu do średniej liczby wniosków otrzymanych w tym samym czasie.
Przeciętny okres zatrudnienia w SMO.
Wskaźnik wykorzystania QS - średni udział czasu, w którym QS jest zajęty obsługą aplikacji itp.
Wskaźniki jakości obsługi aplikacji:
Średni czas oczekiwania na aplikację w kolejce.
Średni czas przebywania wniosku w CMO.
Prawdopodobieństwo odmowy obsługi żądania bez oczekiwania.
Prawdopodobieństwo, że przychodzące żądanie zostanie natychmiast przyjęte do obsługi.
Prawo rozkładu czasu pozostawania aplikacji w kolejce.
Prawo rozkładu czasu spędzonego przez aplikację w QS.
Średnia liczba wniosków w kolejce.
Średnia liczba aplikacji w QS itp.
Wskaźniki wydajności pary „QS - konsument”, gdzie „konsument” oznacza cały zestaw aplikacji lub niektóre z nich
Do CMO z awariami:
Do CMO z nieograniczonym oczekiwaniem zarówno bezwzględna, jak i względna przepustowość tracą znaczenie, ponieważ każde przychodzące żądanie zostanie wcześniej czy później obsłużone. Dla takiego QS ważnymi wskaźnikami są:
Do Mieszany typ CMO stosowane są obie grupy wskaźników: zarówno względne, jak i bezwzględna przepustowość i cechy oczekiwań.
W zależności od celu operacji kolejkowania, dowolny z powyższych wskaźników (lub zestaw wskaźników) można wybrać jako kryterium wydajności.
model analityczny QS to zestaw równań lub formuł, które pozwalają określić prawdopodobieństwa stanów systemu podczas jego pracy i obliczyć wskaźniki wydajności na podstawie znanych charakterystyk kanałów przepływu i obsługi.
Nie ma ogólnego modelu analitycznego dla dowolnego QS. Modele analityczne zostały opracowane dla ograniczonej liczby specjalnych przypadków QS. Modele analityczne, które mniej lub bardziej dokładnie odwzorowują rzeczywiste systemy, są z reguły złożone i trudne do zobaczenia.
Modelowanie analityczne QS jest znacznie ułatwione, jeśli procesy zachodzące w QS są markowskie (przepływy żądań są proste, czasy obsługi rozkładają się wykładniczo). W tym przypadku wszystkie procesy w SQ można opisać równaniami różniczkowymi zwyczajnymi, aw przypadku granicznym dla stanów stacjonarnych - liniowymi równaniami algebraicznymi i po ich rozwiązaniu wyznaczyć wybrane wskaźniki wydajności.
Rozważmy przykłady niektórych QS.
2.5.1. Wielokanałowe QS z awariami
Przykład 2.5. Trzech inspektorów ruchu sprawdza listy przewozowe kierowców ciężarówek. Jeśli przynajmniej jeden inspektor jest wolny, przejeżdżająca ciężarówka zostaje zatrzymana. Jeśli wszyscy inspektorzy są zajęci, ciężarówka przejeżdża bez zatrzymywania się. Przepływ ciężarówek jest najprostszy, czas kontroli jest losowy z rozkładem wykładniczym.
Sytuację taką może zasymulować trójkanałowy QS z awariami (bez kolejki). System jest otwarty, o jednorodnych zastosowaniach, jednofazowy, z absolutnie niezawodnymi kanałami.
Opis stanów:
Wszyscy inspektorzy są wolni;
Jeden inspektor jest zajęty;
Dwóch inspektorów jest zajętych;
Trzech inspektorów jest zajętych.
Wykres stanów systemu przedstawiono na ryc. 2.11.

Ryż. 2.11.
Na wykresie: - natężenie przepływu samochodów ciężarowych; - intensywność kontroli dokumentów przez jednego inspektora ruchu.
Symulacja jest przeprowadzana w celu określenia części samochodów, która nie będzie testowana.
Rozwiązanie
Pożądaną częścią prawdopodobieństwa jest prawdopodobieństwo zatrudnienia wszystkich trzech inspektorów. Ponieważ wykres stanu reprezentuje typowy schemat „śmierci i reprodukcji”, znajdziemy zależności (2.2).

Można scharakteryzować przepustowość tego stanowiska inspektorów ruchu względna przepustowość:
![]()
Przykład 2.6. Do odbierania i przetwarzania meldunków z grupy rozpoznawczej do wydziału rozpoznawczego stowarzyszenia przydzielono grupę trzech oficerów. Przewidywana szybkość raportowania to 15 raportów na godzinę. Średni czas przetwarzania jednego zgłoszenia przez jednego funkcjonariusza wynosi . Każdy oficer może otrzymywać raporty z dowolnej grupy rozpoznawczej. Zwolniony oficer przetwarza ostatni z otrzymanych raportów. Przychodzące raporty muszą być przetwarzane z prawdopodobieństwem co najmniej 95%.
Sprawdź, czy przydzielona grupa trzech funkcjonariuszy wystarczy do wykonania przydzielonego zadania.
Rozwiązanie
Grupa oficerów pracuje jako CMO z awariami, składająca się z trzech kanałów.
Przepływ raportów z intensywnością  można uznać za najprostszą, ponieważ jest to suma kilku grup rozpoznawczych. Intensywność konserwacji
można uznać za najprostszą, ponieważ jest to suma kilku grup rozpoznawczych. Intensywność konserwacji  . Prawo dystrybucji nie jest znane, ale nie jest to istotne, ponieważ wykazano, że dla systemów z awariami może być arbitralne.
. Prawo dystrybucji nie jest znane, ale nie jest to istotne, ponieważ wykazano, że dla systemów z awariami może być arbitralne.
Opis stanów i wykres stanów systemu QS będą podobne do tych podanych w przykładzie 2.5.
Ponieważ wykres stanu jest schematem „śmierci i reprodukcji”, istnieją dla niego gotowe wyrażenia dla prawdopodobieństw stanów granicznych:
Relacja nazywa się zmniejszona intensywność przepływu aplikacji. Jego fizyczne znaczenie jest następujące: wartością jest średnia liczba żądań przychodzących do QS przez średni czas obsługi jednego żądania.
W przykładzie 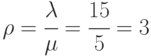 .
.
W rozważanym QS awaria występuje, gdy wszystkie trzy kanały są zajęte, czyli . Następnie:
Dlatego prawdopodobieństwo awarii w przetwarzaniu raportów jest ponad 34% (), wówczas konieczne jest zwiększenie personelu grupy. Podwoijmy skład grupy, czyli QS będzie teraz miał sześć kanałów i obliczmy:

W ten sposób tylko grupa sześciu funkcjonariuszy będzie mogła przetwarzać napływające zgłoszenia z prawdopodobieństwem 95%.
2.5.2. Wielokanałowe QS z oczekiwaniem
Przykład 2.7. Na odcinku forsowania rzeki znajduje się 15 przepraw tego samego typu. Przepływ sprzętu docierającego na skrzyżowanie wynosi średnio 1 szt./min, średni czas przekraczania jednej jednostki sprzętu wynosi 10 minut (uwzględniając powrót obiektu krzyżowego).
Oceń główne cechy przejścia, w tym prawdopodobieństwo natychmiastowego przejścia natychmiast po przybyciu elementu wyposażenia.
Rozwiązanie

Bezwzględna przepustowość, czyli wszystko, co dochodzi do skrzyżowania, jest prawie natychmiast skreślane.
Średnia liczba działających przepraw:

Wskaźniki wykorzystania krzyżowego i przestojów:
Opracowano również program do rozwiązania tego przykładu. Przedziały czasowe na przybycie sprzętu na przeprawę, czas przeprawy należy rozłożyć zgodnie z prawem wykładniczym.
Wskaźniki wykorzystania promu po 50 kursach są praktycznie takie same: ![]() .
.
WPROWADZANIE
ROZDZIAŁ I. FORMUŁOWANIE PROBLEMÓW KOLEJNEJ OBSŁUGI
1.1 Ogólna koncepcja teorii kolejkowania
1.2 Modelowanie systemów kolejkowych
1.3 Wykresy stanu QS
1.4 Procesy stochastyczne
Rozdział II. RÓWNANIA OPISUJĄCE SYSTEMY KOLEJKOWE
2.1 Równania Kołmogorowa
2.2 Procesy „narodzin - śmierć”
2.3 Ekonomiczne i matematyczne sformułowanie problemów związanych z kolejkowaniem
Rozdział III. MODELE SYSTEMÓW KOLEJKOWYCH
3.1 Jednokanałowe QS z odmową usługi
3.2 Wielokanałowe QS z odmową usługi
3.3 Model wielofazowego systemu obsługi turystycznej
3.4 Jednokanałowy QS z ograniczoną długością kolejki
3.5 Jednokanałowy QS z nieograniczoną kolejką
3.6 Wielokanałowe QS z ograniczoną długością kolejki
3.7 Wielokanałowy QS z nieograniczoną kolejką
3.8 Analiza systemu kolejkowania w supermarketach
WNIOSEK
Wstęp
Obecnie pojawiła się duża literatura poświęcona bezpośrednio teorii kolejkowania, rozwojowi jej matematycznych aspektów, a także różnym obszarom jej zastosowań - wojskowym, medycznym, transportowym, handlowym, lotniczym itp.
Teoria kolejek opiera się na teorii prawdopodobieństwa i statystyce matematycznej. Początkowy rozwój teorii kolejkowania związany jest z nazwiskiem duńskiego naukowca A.K. Erlang (1878-1929) z pracami z zakresu projektowania i eksploatacji central telefonicznych.
Teoria kolejek to dział matematyki stosowanej zajmujący się analizą procesów w systemach produkcyjnych, usługowych i sterowania, w których jednorodne zdarzenia powtarzają się wielokrotnie, np. w przedsiębiorstwach usług konsumenckich; w systemach odbierania, przetwarzania i przesyłania informacji; automatyczne linie produkcyjne itp. Wielki wkład w rozwój tej teorii wnieśli rosyjscy matematycy A.Ya. Chinchin, B.V. Gnedenko, A.N. Kołmogorowa, E.S. Wentzel i inni.
Przedmiotem teorii kolejek jest ustalenie zależności między charakterem przepływu aplikacji, liczbą kanałów obsługi, wydajnością pojedynczego kanału a wydajną obsługą w celu znalezienia najlepszych sposobów sterowania tymi procesami. Zadania teorii kolejkowania mają charakter optymalizacyjny i docelowo obejmują ekonomiczny aspekt określenia takiego wariantu systemu, który zapewni minimum całkowitych kosztów z oczekiwania na usługę, straty czasu i zasobów na obsługę oraz z przestojów kanałów usług.
W działalności komercyjnej zastosowanie teorii kolejkowania nie znalazło jeszcze pożądanego rozkładu.
Wynika to głównie z trudności w wyznaczaniu celów, potrzeby dogłębnego zrozumienia treści działań handlowych, a także rzetelnych i trafnych narzędzi, które pozwalają kalkulować różne opcje konsekwencji decyzji zarządczych w działalności handlowej.
Rozdział I . Ustawianie zadań kolejkowania
1.1 Ogólna koncepcja teorii kolejkowania
Charakter kolejkowania w różnych dziedzinach jest bardzo subtelny i złożony. Działalność handlowa wiąże się z wykonywaniem wielu operacji na etapach ruchu, na przykład masy towarowej ze sfery produkcji do sfery konsumpcji. Takie operacje to załadunek towarów, transport, rozładunek, przechowywanie, przetwarzanie, pakowanie, sprzedaż. Oprócz takich podstawowych operacji procesowi przemieszczania towarów towarzyszy duża liczba operacji wstępnych, przygotowawczych, towarzyszących, równoległych i kolejnych z dokumentami płatniczymi, kontenerami, pieniędzmi, samochodami, klientami itp.
Wymienione fragmenty działalności handlowej charakteryzują się masowym odbiorem towarów, pieniędzy, odwiedzających w losowych momentach, a następnie ich konsekwentną obsługą (zaspokojenie wymagań, próśb, wniosków) poprzez wykonanie odpowiednich operacji, których czas realizacji również jest losowy. Wszystko to powoduje nierówności w pracy, generuje niedociążenia, przestoje i przeciążenia w operacjach komercyjnych. Kolejki sprawiają wiele kłopotów np. odwiedzającym w kawiarniach, kantynach, restauracjach, czy kierowcom samochodów na składach towarowych, oczekującym na rozładunek, załadunek czy formalności. W związku z tym istnieją zadania polegające na analizie istniejących opcji wykonywania całego zestawu operacji, na przykład na parkiecie supermarketu, restauracji lub warsztatach do produkcji własnych produktów w celu oceny ich pracy, identyfikacji słabe ogniwa i rezerwy, a docelowo opracować rekomendacje mające na celu zwiększenie efektywności działań komercyjnych.
Ponadto powstają inne zadania związane z tworzeniem, organizacją i planowaniem nowej ekonomicznej, racjonalnej opcji wykonywania wielu operacji na parkiecie, cukierni, wszystkich poziomach obsługi restauracji, kawiarni, kantyny, działu planowania, działu księgowości, dział personalny itp.
Zadania organizacji kolejek powstają w prawie wszystkich sferach ludzkiej działalności, na przykład obsługa kupujących w sklepach przez sprzedawców, obsługa gości w punktach gastronomicznych, obsługa klientów w przedsiębiorstwach usług konsumenckich, prowadzenie rozmów telefonicznych w centrali telefonicznej, opieka medyczna dla pacjentów w przychodni itp. . We wszystkich powyższych przykładach istnieje potrzeba zaspokojenia potrzeb dużej liczby konsumentów.
Wymienione zadania można z powodzeniem rozwiązać za pomocą specjalnie stworzonych do tych celów metod i modeli teorii kolejek (QMT). Teoria ta wyjaśnia, że konieczne jest służenie komuś lub czemuś, co określa pojęcie „żądanie (wymaganie) usługi”, a operacje usługowe wykonuje ktoś lub coś, co nazywa się kanałami usług (węzłami). Rolę aplikacji w działalności handlowej pełnią towary, goście, pieniądze, audytorzy, dokumenty, a rolę kanałów obsługi pełnią sprzedawcy, administratorzy, kucharze, cukiernicy, kelnerzy, kasjerzy, handlowcy, ładowarki, sprzęt handlowy itp. Należy zauważyć, że w jednym wariancie na przykład kucharz w trakcie gotowania jest kanałem obsługi, a w innym działa jako prośba o usługę, na przykład do kierownika produkcji w celu odbioru towaru.
Ze względu na masowość napływów usług, wnioski tworzą przepływy, które nazywane są przychodzącymi przed wykonaniem operacji serwisowych oraz po ewentualnym oczekiwaniu na rozpoczęcie usługi, tj. przestoje w kolejce, usługa formularzy przepływa w kanałach, a następnie powstaje strumień wychodzących żądań. Ogólnie rzecz biorąc, zbiór elementów przychodzącego przepływu wniosków, kolejki, kanałów obsługi i wychodzącego przepływu wniosków tworzy najprostszy jednokanałowy system kolejkowy - QS.
System to zestaw połączonych i. celowo współdziałające części (elementy). Przykładami takich prostych QS w działalności handlowej są miejsca przyjęcia i przetwarzania towarów, centra rozliczeniowe z klientami w sklepach, kawiarnie, stołówki, praca ekonomisty, księgowego, kupca, kucharza przy dystrybucji itp.
Procedurę serwisową uważa się za zakończoną, gdy zgłoszenie serwisowe opuszcza system. Długość przedziału czasu wymaganego do realizacji procedury serwisowej zależy głównie od charakteru zgłoszenia serwisowego, stanu samego systemu serwisowego oraz kanału serwisowego.
Rzeczywiście, czas pobytu kupującego w supermarkecie zależy z jednej strony od osobistych cech kupującego, jego próśb, od asortymentu towarów, które zamierza kupić, a z drugiej strony od formy organizacji obsługi i obsługi, co może znacząco wpłynąć na czas spędzany przez kupującego w supermarkecie i intensywność obsługi. Np. opanowanie „ślepej” metody pracy na kasie przez kasjerów-kontrolerów pozwoliło na zwiększenie przepustowości węzłów rozliczeniowych o 1,3 raza i zaoszczędzenie czasu spędzonego na rozliczeniach z klientami przy każdej kasie o ponad 1,5 godziny dziennie . Wprowadzenie jednego węzła rozliczeniowego w supermarkecie daje nabywcy wymierne korzyści. Jeśli więc przy tradycyjnej formie rozliczeń czas obsługi jednego klienta wynosił średnio 1,5 minuty, to przy wprowadzeniu pojedynczego węzła rozliczeniowego – 67 sekund. Spośród nich 44 sekundy przeznacza się na dokonanie zakupu w sekcji, a 23 sekundy przeznacza się bezpośrednio na płatności za zakupy. Jeśli kupujący dokona kilku zakupów w różnych sekcjach, strata czasu zostanie zmniejszona, kupując dwa zakupy o 1,4 razy, trzy - o 1,9, pięć - o 2,9 razy.
Przez obsługę zgłoszeń rozumiemy proces zaspokojenia potrzeby. Usługa ma inny charakter. Jednak we wszystkich przykładach otrzymane żądania muszą być obsługiwane przez jakieś urządzenie. W niektórych przypadkach usługa wykonywana jest przez jedną osobę (obsługa klienta przez jednego sprzedawcę, w innych przez grupę osób (obsługa pacjenta przez komisję lekarską w przychodni), a w niektórych przypadkach przez urządzenia techniczne (sprzedaż wody sodowej , kanapki przez maszyny).Zestaw narzędzi obsługujących aplikacje nosi nazwę kanału serwisowego.
Jeśli kanały usług są w stanie zaspokoić te same żądania, wówczas kanały usług nazywane są jednorodnymi. Zbiór jednorodnych kanałów usługowych nazywany jest systemem obsługującym.
System kolejkowy otrzymuje dużą liczbę żądań w losowych momentach, których czas trwania usługi jest również zmienną losową. Kolejne przybycie klientów do systemu kolejkowego nazywamy strumieniem przychodzącym klientów, a sekwencja klientów opuszczających system kolejkowy nazywamy strumieniem wychodzącym.
