Distribuzione casuale uniforme. Conversione di una variabile casuale distribuita uniformemente in una variabile distribuita normalmente
Come esempio di variabile casuale continua, si consideri una variabile casuale X distribuita uniformemente sull'intervallo (a; b). Diciamo che la variabile casuale X distribuito uniformemente sull'intervallo (a; b), se la sua densità di distribuzione non è costante su questo intervallo:
Dalla condizione di normalizzazione determiniamo il valore della costante c . L'area sotto la curva di densità di distribuzione dovrebbe essere uguale a uno, ma nel nostro caso è l'area di un rettangolo con una base (b - α) e un'altezza c (Fig. 1). 
Riso. 1 Densità di distribuzione uniforme
Da qui troviamo il valore della costante c: ![]()
Quindi, la densità di una variabile casuale distribuita uniformemente è uguale a 
Troviamo ora la funzione di distribuzione con la formula:
1) per ![]()
2) per
3) per 0+1+0=1.
In questo modo, 
La funzione di distribuzione è continua e non diminuisce (Fig. 2). 
Riso. 2 Funzione di distribuzione di una variabile aleatoria uniformemente distribuita
Cerchiamo aspettativa matematica di una variabile aleatoria uniformemente distribuita secondo la formula:
Varianza di distribuzione uniformeè calcolato dalla formula ed è uguale a
Esempio 1. Il valore di divisione della scala dello strumento di misura è 0,2. Le letture dello strumento vengono arrotondate alla divisione intera più vicina. Trova la probabilità che si commetta un errore durante la lettura: a) minore di 0,04; b) grande 0,02
Soluzione. L'errore di arrotondamento è una variabile casuale distribuita uniformemente nell'intervallo tra divisioni intere adiacenti. Si consideri l'intervallo (0; 0,2) come tale divisione (Fig. a). L'arrotondamento può essere effettuato sia verso il bordo sinistro - 0, sia verso destra - 0,2, il che significa che è possibile eseguire due volte un errore inferiore o uguale a 0,04, che deve essere preso in considerazione nel calcolo della probabilità: 

P = 0,2 + 0,2 = 0,4
Nel secondo caso, il valore di errore può anche superare 0,02 su entrambi i limiti di divisione, ovvero può essere maggiore di 0,02 o minore di 0,18. 
Quindi la probabilità di un errore come questo:
Esempio #2. Si presumeva che la stabilità della situazione economica del Paese (assenza di guerre, disastri naturali, ecc.) negli ultimi 50 anni potesse essere giudicata dalla natura della distribuzione della popolazione per età: in una situazione di calma, dovrebbe essere uniforme. Come risultato dello studio, sono stati ottenuti i seguenti dati per uno dei paesi.
C'è qualche ragione per credere che ci fosse una situazione instabile nel Paese?Eseguiamo la decisione utilizzando il calcolatore Test di ipotesi. Tabella per il calcolo degli indicatori.
| Gruppi | Intervallo medio, x i | Quantità, fi | x io * f io | Frequenza cumulativa, S | |x - x cfr |*f | (x - x sr) 2 *f | Frequenza, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
media ponderata
Indicatori di variazione.
Tassi di variazione assoluti.
L'intervallo di variazione è la differenza tra i valori massimo e minimo dell'attributo della serie primaria.
R = X max - X min
R=70 - 0=70
Dispersione- caratterizza la misura dello spread attorno al suo valore medio (misura della dispersione, cioè deviazione dalla media).
Deviazione standard.
Ogni valore della serie differisce dal valore medio di 43 di non più di 23,92
Verifica di ipotesi sul tipo di distribuzione.
4. Testare l'ipotesi su distribuzione uniforme la popolazione generale.
Per verificare l'ipotesi sulla distribuzione uniforme di X, cioè secondo la legge: f(x) = 1/(b-a) nell'intervallo (a,b)
necessario:
1. Stimare i parametri aeb - le estremità dell'intervallo in cui sono stati osservati i possibili valori di X, secondo le formule (il * indica le stime dei parametri):
2. Trova la densità di probabilità della distribuzione stimata f(x) = 1/(b * - a *)
3. Trova le frequenze teoriche:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Confrontare le frequenze empiriche e teoriche utilizzando il test di Pearson, assumendo il numero di gradi di libertà k = s-3, dove s è il numero di intervalli di campionamento iniziali; se, invece, è stata fatta una combinazione di piccole frequenze, e quindi gli intervalli stessi, allora s è il numero di intervalli rimanenti dopo la combinazione.
Soluzione:
1. Trova le stime dei parametri a * e b * della distribuzione uniforme utilizzando le formule:
2. Trova la densità della distribuzione uniforme assunta:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Trova le frequenze teoriche:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
I restanti n s saranno uguali:
n s = n*f(x)(x io - x i-1)
| io | n io | n*i | n io - n * io | (n io - n* i) 2 | (n io - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Totale | 1 | 0.0532 |
Pertanto, la regione critica per questa statistica è sempre destrorsa: se la sua densità di probabilità è costante su questo intervallo, e al di fuori di essa è 0 (cioè una variabile casuale X focalizzato sul segmento [ un, b], su cui ha una densità costante). Secondo questa definizione, la densità di una distribuzione uniformemente distribuita sul segmento [ un, b] variabile casuale X sembra:
dove Insieme a c'è un certo numero. Tuttavia, è facile trovarlo utilizzando la proprietà della densità di probabilità per v.r. concentrata sull'intervallo [ un,
b]:
 . Quindi ne consegue che
. Quindi ne consegue che  , dove
, dove  . Pertanto, la densità uniformemente distribuita sul segmento [ un,
b] variabile casuale X sembra:
. Pertanto, la densità uniformemente distribuita sul segmento [ un,
b] variabile casuale X sembra:
 .
.
Per giudicare l'uniformità della distribuzione dei n.s.v. X possibile dalla seguente considerazione. Una variabile casuale continua ha una distribuzione uniforme sull'intervallo [ un, b] se prende valori solo da questo segmento, e qualsiasi numero da questo segmento non ha un vantaggio rispetto ad altri numeri in questo segmento nel senso di poter essere il valore di questa variabile casuale.
Le variabili casuali con una distribuzione uniforme includono variabili come il tempo di attesa di un veicolo a una fermata (a un intervallo di movimento costante, il tempo di attesa è distribuito uniformemente su questo intervallo), l'errore di arrotondamento del numero a un numero intero (distribuito uniformemente su [-0,5 , 0.5 ]) e altri.
Tipo di funzione di distribuzione F(X)
un,
b] variabile casuale X viene ricercato dalla densità di probabilità nota f(X)
usando la formula della loro connessione  . Come risultato dei calcoli corrispondenti, otteniamo la seguente formula per la funzione di distribuzione F(X)
segmento distribuito uniformemente [ un,
b] variabile casuale X
:
. Come risultato dei calcoli corrispondenti, otteniamo la seguente formula per la funzione di distribuzione F(X)
segmento distribuito uniformemente [ un,
b] variabile casuale X
:
 .
.
Le figure mostrano i grafici della densità di probabilità f(X) e funzioni di distribuzione f(X) segmento distribuito uniformemente [ un, b] variabile casuale X :


Aspettativa matematica, varianza, deviazione standard, moda e mediana di un segmento uniformemente distribuito [ un, b] variabile casuale X calcolato dalla densità di probabilità f(X) nel solito modo (e semplicemente per l'aspetto semplice f(X) ). Il risultato sono le seguenti formule:
ma moda d(X) è un numero qualsiasi dell'intervallo [ un, b].
Troviamo la probabilità di colpire il segmento uniformemente distribuito [ un,
b] variabile casuale X nell'intervallo  , completamente sdraiato all'interno [ un,
b]. Tenendo conto della forma nota della funzione di distribuzione, otteniamo:
, completamente sdraiato all'interno [ un,
b]. Tenendo conto della forma nota della funzione di distribuzione, otteniamo:
Pertanto, la probabilità di colpire il segmento uniformemente distribuito [ un,
b] variabile casuale X nell'intervallo  , completamente sdraiato all'interno [ un,
b], non dipende dalla posizione di questo intervallo, ma dipende solo dalla sua lunghezza ed è direttamente proporzionale a questa lunghezza.
, completamente sdraiato all'interno [ un,
b], non dipende dalla posizione di questo intervallo, ma dipende solo dalla sua lunghezza ed è direttamente proporzionale a questa lunghezza.
Esempio. L'intervallo di autobus è di 10 minuti. Qual è la probabilità che un passeggero che arriva a una fermata dell'autobus aspetterà meno di 3 minuti per l'autobus? Qual è il tempo medio di attesa per un autobus?
Distribuzione normale
Questa distribuzione si incontra più spesso nella pratica e gioca un ruolo eccezionale nella teoria della probabilità e nella statistica matematica e nelle loro applicazioni, poiché così tante variabili casuali nelle scienze naturali, nell'economia, nella psicologia, nella sociologia, nelle scienze militari e così via hanno una tale distribuzione. Questa distribuzione è la legge limitante, a cui si avvicinano (in determinate condizioni naturali) molte altre leggi di distribuzione. Con l'aiuto della legge della distribuzione normale, vengono descritti anche fenomeni che sono soggetti all'azione di molti fattori casuali indipendenti di qualsiasi natura ea qualsiasi legge della loro distribuzione. Passiamo alle definizioni.
Una variabile casuale continua è chiamata distribuita su legge normale (o legge gaussiana), se la sua densità di probabilità ha la forma:
 ,
,
dove sono i numeri un e σ (σ>0 ) sono i parametri di questa distribuzione.
Come già accennato, la legge di Gauss di distribuzione di variabili casuali ha numerose applicazioni. Secondo questa legge vengono distribuiti gli errori di misurazione degli strumenti, la deviazione dal centro del bersaglio durante il tiro, le dimensioni dei pezzi fabbricati, il peso e l'altezza delle persone, le precipitazioni annuali, il numero di neonati e molto altro.
La formula sopra per la densità di probabilità di una variabile casuale normalmente distribuita contiene, come è stato detto, due parametri un e σ , e quindi definisce una famiglia di funzioni che variano a seconda dei valori di questi parametri. Se applichiamo i metodi usuali di analisi matematica dello studio delle funzioni e del tracciamento alla densità di probabilità di una distribuzione normale, possiamo trarre le seguenti conclusioni.

sono i suoi punti di flesso.
Sulla base delle informazioni ricevute, costruiamo un grafico della densità di probabilità f(X) distribuzione normale (è chiamata curva gaussiana - figura).

Scopriamo come influisce la modifica dei parametri un e σ sulla forma della curva gaussiana. È ovvio (questo può essere visto dalla formula per la densità della distribuzione normale) che il parametro cambia un non cambia la forma della curva, ma porta solo al suo spostamento verso destra o sinistra lungo l'asse X. Dipendenza σ più difficile. Dallo studio precedente si evince come il valore del massimo e le coordinate dei punti di flesso dipendano dal parametro σ . Inoltre, dovrebbe essere preso in considerazione per qualsiasi parametro un e σ l'area sotto la curva gaussiana rimane uguale a 1 (questa è una proprietà generale della densità di probabilità). Da quanto detto ne consegue che con un aumento del parametro σ la curva diventa più piatta e si allunga lungo l'asse X. La figura mostra le curve gaussiane per vari valori del parametro σ (σ 1 < σ< σ 2 ) e lo stesso valore del parametro un.

Scopri il significato probabilistico dei parametri un e σ
distribuzione normale. Già dalla simmetria della curva gaussiana rispetto alla verticale passante per il numero un sull'asse Xè chiaro che il valore medio (cioè l'aspettativa matematica M(X)) di una variabile aleatoria normalmente distribuita è uguale a un. Per le stesse ragioni, anche la moda e la mediana devono essere uguali al numero a. I calcoli esatti secondo le formule corrispondenti lo confermano. Se scriviamo l'espressione sopra per f(X)
sostituire nella formula la varianza  , quindi dopo il (piuttosto difficile) calcolo dell'integrale, otteniamo nella risposta il numero σ
2
. Quindi, per una variabile casuale X distribuito secondo la legge normale, si ottengono le seguenti principali caratteristiche numeriche:
, quindi dopo il (piuttosto difficile) calcolo dell'integrale, otteniamo nella risposta il numero σ
2
. Quindi, per una variabile casuale X distribuito secondo la legge normale, si ottengono le seguenti principali caratteristiche numeriche:
Pertanto, il significato probabilistico dei parametri della distribuzione normale un e σ prossimo. Se r.v. Xun e σ un σ.
Troviamo ora la funzione di distribuzione F(X)
per una variabile casuale X, distribuito secondo la legge normale, utilizzando l'espressione sopra per la densità di probabilità f(X)
e formula  . Quando si sostituisce f(X)
otteniamo un integrale "non preso". Tutto ciò che può essere fatto per semplificare l'espressione per F(X),
questa è la rappresentazione di questa funzione nella forma:
. Quando si sostituisce f(X)
otteniamo un integrale "non preso". Tutto ciò che può essere fatto per semplificare l'espressione per F(X),
questa è la rappresentazione di questa funzione nella forma:
 ,
,
dove F(x)- il cosidetto Funzione Laplace, che sembra
 .
.
Anche l'integrale in base al quale è espressa la funzione di Laplace non è preso (ma per ciascuno X questo integrale può essere calcolato approssimativamente con qualsiasi accuratezza predeterminata). Tuttavia, non è necessario calcolarlo, poiché alla fine di qualsiasi libro di testo sulla teoria della probabilità c'è una tabella per determinare i valori della funzione F(x) ad un dato valore X. In quanto segue, avremo bisogno della proprietà oddity della funzione di Laplace: F(-x)=−F(x) per tutti i numeri X.
Troviamo ora la probabilità che un r.v. normalmente distribuito. X prenderà un valore dall'intervallo numerico specificato (α, β) . Dalle proprietà generali della funzione di distribuzione Р(α< X< β)= F(β) − F(α) . Sostituendo α e β nell'espressione sopra per F(X) , noi abbiamo
 .
.
Come accennato in precedenza, se il r.v. X distribuito normalmente con parametri un e σ , allora il suo valore medio è uguale a un, e la deviazione standard è uguale a σ. Ecco perchè media deviazione dei valori di questo r.v. quando testato dal numero unè uguale a σ. Ma questa è la deviazione media. Pertanto, sono possibili anche deviazioni maggiori. Scopriamo come sono possibili queste o quelle deviazioni dal valore medio. Troviamo la probabilità che il valore di una variabile aleatoria sia distribuito secondo la legge normale X deviare dalla sua media M(X)=a minore di un certo numero δ, cioè R(| X− un|<δ ) : . In questo modo,
 .
.
Sostituendo in questa uguaglianza δ=3σ, otteniamo la probabilità che il valore di r.v. X(in una prova) devierà dalla media di meno di tre volte σ (con una deviazione media, come ricordiamo, pari a σ ): (significato F(3) tratto dalla tabella dei valori della funzione di Laplace). È quasi 1 ! Quindi la probabilità dell'evento opposto (che il valore devii almeno di 3σ) è uguale a 1 −0.997=0.003 , che è molto vicino a 0 . Pertanto, questo evento è "quasi impossibile" − accade molto raramente (in media 3 il tempo è scaduto 1000 ). Questo ragionamento è alla base della famosa "regola dei tre sigma".
Regola dei tre sigma. Variabile casuale normalmente distribuita in una sola prova praticamente non si discosta dalla sua media oltre 3σ.
Ancora una volta, sottolineiamo che stiamo parlando di un test. Se ci sono molte prove di una variabile casuale, è del tutto possibile che alcuni dei suoi valori si spostino più lontano dalla media di 3σ. Ciò conferma quanto segue
Esempio. Qual è la probabilità che dopo 100 prove di una variabile casuale normalmente distribuita X almeno uno dei suoi valori devierà dalla media di oltre tre volte la deviazione standard? Che ne dici di 1000 prove?
Soluzione. Lascia che l'evento MA significa che quando si testa una variabile casuale X il suo valore ha deviato dalla media di più di 3σ. Come è stato appena scoperto, la probabilità di questo evento p=P(A)=0,003. Sono stati effettuati 100 di questi test. Dobbiamo trovare la probabilità che l'evento MA accaduto almeno volte, cioè venire da 1 prima 100 una volta. Questo è un tipico problema dello schema di Bernoulli con i parametri n=100 (numero di prove indipendenti), p=0,003(probabilità dell'evento MA in una prova) q=1− p=0.997 . Volevo trovare R 100 (1≤ K≤100) . In questo caso, ovviamente, è più facile trovare prima la probabilità dell'evento opposto R 100 (0) − la probabilità che l'evento MA mai successo (cioè successo 0 volte). Considerando la connessione tra le probabilità dell'evento stesso e il suo opposto, otteniamo:
Non così poco. Può benissimo succedere (si verifica in media ogni quattro di queste serie di test). In 1000 test secondo lo stesso schema, si può ottenere che la probabilità di almeno una deviazione è maggiore di 3σ, è uguale a: . Quindi è sicuro attendere almeno una di queste deviazioni.
Esempio. L'altezza degli uomini di una certa fascia di età è normalmente distribuita con aspettativa matematica un e deviazione standard σ . Che proporzione di costumi K-esima crescita dovrebbe essere inclusa nella produzione totale per una data fascia di età se K-esima crescita è determinata dai seguenti limiti:
1 crescita : 158 − 164 cm 2 crescita : 164 - 170 cm 3 crescita : 170 - 176 cm 4 crescita : 176 - 182 cm
Soluzione. Risolviamo il problema con i seguenti valori di parametro: a=178,σ=6,K=3
. Lascia che r.v. X
−
l'altezza di un uomo scelto a caso (è distribuita secondo la condizione normalmente con i parametri indicati). Trova la probabilità di cui avrà bisogno un uomo scelto a caso 3
la crescita. Usando la stranezza della funzione di Laplace F(x) e una tabella dei suoi valori: P(170
Distribuzione di probabilità di una variabile casuale continua X, che prende tutti i valori dall'intervallo , è chiamato uniforme, se la sua densità di probabilità su questo segmento è costante e al di fuori di esso è uguale a zero. Quindi, la densità di probabilità di una variabile casuale continua X, distribuito uniformemente sul segmento , sembra:

Definiamo valore atteso, dispersione e per una variabile casuale con distribuzione uniforme.
, ![]() ,
, ![]() .
.
Esempio. Tutti i valori di una variabile casuale uniformemente distribuita giacciono sul segmento . Trova la probabilità che una variabile casuale rientri nell'intervallo (3;5) .
a=2, b=8,  .
.
Distribuzione binomiale
Lascia che sia prodotto n test e la probabilità che si verifichi un evento UN in ogni prova è p e non dipende dall'esito di altre prove (prove indipendenti). Poiché la probabilità che si verifichi un evento UN in un test è p, allora la probabilità che non si verifichi è uguale a q=1-p.
Lascia che l'evento UNè venuto in n prove m una volta. Questo evento complesso può essere scritto come un prodotto:
![]() .
.
Quindi la probabilità che n evento di prova UN verrà m volte , è calcolato con la formula:
![]() o
o ![]() (1)
(1)
Viene chiamata la formula (1). Formula di Bernoulli.
Permettere Xè una variabile casuale uguale al numero di occorrenze dell'evento UN in n test, che assume valori con probabilità:
Viene chiamata la legge di distribuzione risultante di una variabile casuale legge della distribuzione binomiale.
| X | m | n | ||||
| P |
Valore atteso, dispersione e deviazione standard le variabili casuali distribuite secondo la legge del binomio sono determinate dalle formule:
, , .
Esempio. Vengono sparati tre colpi al bersaglio e la probabilità di colpire ogni colpo è 0,8. Consideriamo una variabile casuale X- il numero di colpi sul bersaglio. Trova la sua legge di distribuzione, aspettativa matematica, varianza e deviazione standard.
p=0,8, q=0,2, n=3, ![]() , ,
, , ![]() .
.
![]() - probabilità di 0 colpi;
- probabilità di 0 colpi;
Probabilità di un colpo;
Probabilità di due colpi;
![]() è la probabilità di tre risultati.
è la probabilità di tre risultati.
Otteniamo la legge di distribuzione:
| X | ||||
| P | 0,008 | 0,096 | 0,384 | 0,512 |
Compiti
1. Una moneta viene lanciata 7 volte. Trova la probabilità che cada sottosopra 4 volte.
2. Una moneta viene lanciata 8 volte. Trova la probabilità che lo stemma appaia non più di tre volte.
3. La probabilità di colpire il bersaglio quando si spara da una pistola p=0,6. Trova l'aspettativa matematica del numero totale di colpi se vengono sparati 10 colpi.
4. Trova l'aspettativa matematica del numero di biglietti della lotteria che vinceranno se vengono acquistati 20 biglietti e la probabilità di vincere per un biglietto è 0,3.
La funzione di distribuzione in questo caso, secondo la (5.7), assumerà la forma:
dove: m è l'aspettativa matematica, s è la deviazione standard.
La distribuzione normale è anche chiamata gaussiana dal matematico tedesco Gauss. Il fatto che una variabile casuale abbia una distribuzione normale con parametri: m,, è indicato come segue: N (m, s), dove: m =a =M ;
Abbastanza spesso, nelle formule, l'aspettativa matematica è indicata con un . Se una variabile casuale è distribuita secondo la legge N(0,1), allora è chiamata valore normale normalizzato o standardizzato. La funzione di distribuzione per esso ha la forma:
|
|
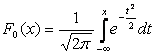 .
.Il grafico della densità della distribuzione normale, chiamato curva normale o curva gaussiana, è mostrato in Fig. 5.4.

Riso. 5.4. Densità di distribuzione normale
La determinazione delle caratteristiche numeriche di una variabile casuale in base alla sua densità è considerata su un esempio.
Esempio 6.
Una variabile casuale continua è data dalla densità di distribuzione: ![]() .
.
Determina il tipo di distribuzione, trova l'aspettativa matematica M(X) e la varianza D(X).
Confrontando la densità di distribuzione data con la (5.16), possiamo concludere che è data la legge di distribuzione normale con m =4. Pertanto, aspettativa matematica M(X)=4, varianza D(X)=9.
Deviazione standard s=3.
La funzione di Laplace, che ha la forma:
|
|
 ,
,è correlato alla funzione di distribuzione normale (5.17), dalla relazione:
F 0 (x) \u003d F (x) + 0,5.
La funzione di Laplace è dispari.
Ф(-x)=-Ф(x).
I valori della funzione di Laplace Ф(х) sono tabulati e presi dalla tabella in base al valore di x (vedi Appendice 1).
La distribuzione normale di una variabile casuale continua gioca un ruolo importante nella teoria della probabilità e nella descrizione della realtà; è molto diffusa nei fenomeni naturali casuali. In pratica, molto spesso ci sono variabili casuali che si formano proprio come risultato della somma di molti termini casuali. In particolare, l'analisi degli errori di misura mostra che sono la somma di vari tipi di errori. La pratica mostra che la distribuzione delle probabilità di errore di misura è vicina alla legge normale.
Usando la funzione di Laplace, si possono risolvere problemi di calcolo della probabilità di cadere in un dato intervallo e in una data deviazione di una normale variabile casuale.
Questo problema è stato a lungo studiato in dettaglio e il metodo delle coordinate polari, proposto da George Box, Mervyn Muller e George Marsaglia nel 1958, è stato il più ampiamente utilizzato. Questo metodo consente di ottenere una coppia di variabili casuali distribuite normalmente indipendenti con aspettativa matematica 0 e varianza 1 come segue:
Dove Z 0 e Z 1 sono i valori desiderati, s \u003d u 2 + v 2 e u e v sono variabili casuali distribuite uniformemente sul segmento (-1, 1), selezionate in modo tale che la condizione 0 sia soddisfatta< s < 1.
Molti usano queste formule senza nemmeno pensarci e molti non sospettano nemmeno della loro esistenza, poiché usano implementazioni già pronte. Ma ci sono persone che hanno delle domande: “Da dove viene questa formula? E perché ottieni una coppia di valori in una volta? Di seguito cercherò di dare una risposta chiara a queste domande.
Per cominciare, permettetemi di ricordarvi quali sono la densità di probabilità, la funzione di distribuzione di una variabile casuale e la funzione inversa. Supponiamo che esista una variabile casuale, la cui distribuzione è data dalla funzione di densità f(x), che ha la seguente forma:

Ciò significa che la probabilità che il valore di questa variabile casuale sia nell'intervallo (A, B) è uguale all'area dell'area ombreggiata. E di conseguenza, l'area dell'intera area ombreggiata dovrebbe essere uguale all'unità, poiché in ogni caso il valore della variabile casuale rientrerà nel dominio della funzione f.
La funzione di distribuzione di una variabile casuale è un integrale della funzione di densità. E in questo caso, la sua forma approssimativa sarà la seguente:

Qui il significato è che il valore della variabile casuale sarà inferiore ad A con probabilità B. E di conseguenza, la funzione non diminuisce mai e i suoi valori giacciono nell'intervallo .
Una funzione inversa è una funzione che restituisce l'argomento della funzione originale se si passa ad essa il valore della funzione originale. Ad esempio, per la funzione x 2 l'inversa sarà la funzione di estrazione della radice, per sin (x) è arcsin (x), ecc.
Poiché la maggior parte dei generatori di numeri pseudocasuali fornisce solo una distribuzione uniforme in uscita, spesso diventa necessario convertirla in un'altra. In questo caso, a una normale gaussiana:

La base di tutti i metodi per trasformare una distribuzione uniforme in qualsiasi altra distribuzione è il metodo della trasformazione inversa. Funziona come segue. Viene trovata una funzione inversa alla funzione della distribuzione richiesta e una variabile casuale distribuita uniformemente sul segmento (0, 1) le viene passata come argomento. In uscita, otteniamo un valore con la distribuzione richiesta. Per chiarezza, ecco l'immagine seguente.

Pertanto, un segmento uniforme viene, per così dire, imbrattato secondo la nuova distribuzione, proiettato su un altro asse attraverso una funzione inversa. Ma il problema è che l'integrale della densità della distribuzione gaussiana non è facile da calcolare, quindi gli scienziati di cui sopra hanno dovuto barare.
Esiste una distribuzione chi-quadrato (distribuzione di Pearson), che è la distribuzione della somma dei quadrati di k variabili casuali normali indipendenti. E nel caso in cui k = 2, questa distribuzione è esponenziale.

Ciò significa che se un punto in un sistema di coordinate rettangolare ha coordinate X e Y casuali distribuite normalmente, dopo aver convertito queste coordinate nel sistema polare (r, θ), il quadrato del raggio (la distanza dall'origine al punto) sarà distribuito in modo esponenziale, poiché il quadrato del raggio è la somma dei quadrati delle coordinate (secondo la legge di Pitagora). La densità di distribuzione di tali punti sul piano sarà simile a questa:


Poiché è uguale in tutte le direzioni, l'angolo θ avrà una distribuzione uniforme nell'intervallo da 0 a 2π. È anche vero il contrario: se si specifica un punto nel sistema di coordinate polari utilizzando due variabili casuali indipendenti (l'angolo distribuito in modo uniforme e il raggio distribuito in modo esponenziale), le coordinate rettangolari di questo punto saranno variabili casuali normali indipendenti. E la distribuzione esponenziale dalla distribuzione uniforme è già molto più facile da ottenere, usando lo stesso metodo di trasformazione inversa. Questa è l'essenza del metodo polare di Box-Muller.
Ora prendiamo le formule.
![]() (1)
(1)
Per ottenere r e θ è necessario generare due variabili casuali distribuite uniformemente sul segmento (0, 1) (chiamiamola u e v), la cui distribuzione (diciamo v) deve essere convertita in esponenziale in ottenere il raggio. La funzione di distribuzione esponenziale si presenta così:
La sua funzione inversa:
![]()
Poiché la distribuzione uniforme è simmetrica, la trasformazione funzionerà in modo simile con la funzione
![]()
Dalla formula di distribuzione del chi quadrato segue che λ = 0,5. Sostituiamo λ, v in questa funzione e otteniamo il quadrato del raggio, e quindi il raggio stesso:

Otteniamo l'angolo allungando il segmento unitario a 2π:
Ora sostituiamo r e θ nelle formule (1) e otteniamo:
 (2)
(2)
Queste formule sono pronte per l'uso. X e Y saranno indipendenti e normalmente distribuiti con varianza 1 e media 0. Per ottenere una distribuzione con altre caratteristiche basta moltiplicare il risultato della funzione per la deviazione standard e sommare la media.
Ma è possibile eliminare le funzioni trigonometriche specificando l'angolo non direttamente, ma indirettamente attraverso le coordinate rettangolari di un punto casuale in un cerchio. Quindi, attraverso queste coordinate, sarà possibile calcolare la lunghezza del vettore raggio, e quindi trovare il coseno e il seno dividendo rispettivamente x e y per esso. Come e perché funziona?
Scegliamo un punto casuale da uniformemente distribuito nel cerchio di raggio unitario e indichiamo il quadrato della lunghezza del raggio vettore di questo punto con la lettera s:

La scelta avviene assegnando casuali coordinate rettangolari xey uniformemente distribuite nell'intervallo (-1, 1), e scartando i punti che non appartengono alla circonferenza, nonché il punto centrale in cui è l'angolo del vettore raggio non definito. Cioè, la condizione 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Otteniamo le formule, come all'inizio dell'articolo. Lo svantaggio di questo metodo è il rifiuto dei punti che non sono inclusi nel cerchio. Cioè, utilizzando solo il 78,5% delle variabili casuali generate. Sui computer più vecchi, la mancanza di funzioni trigonometriche era ancora un grande vantaggio. Ora, quando un'istruzione del processore calcola simultaneamente seno e coseno in un istante, penso che questi metodi possano ancora competere.
Personalmente ho altre due domande:
- Perché il valore di s è distribuito uniformemente?
- Perché la somma dei quadrati di due normali variabili casuali è distribuita in modo esponenziale?

Se viene eseguita una trasformazione simile per una normale variabile casuale, la funzione di densità del suo quadrato risulterà simile a un'iperbole. E l'aggiunta di due quadrati di normali variabili casuali è già un processo molto più complesso associato alla doppia integrazione. E il fatto che il risultato sarà una distribuzione esponenziale, personalmente, mi resta da verificare con un metodo pratico o accettarlo come assioma. E per coloro che sono interessati, suggerisco di familiarizzare con l'argomento più da vicino, traendo conoscenza da questi libri:
- Wentzel E.S. Teoria della probabilità
- Knut D.E. L'arte della programmazione volume 2
In conclusione, fornirò un esempio dell'implementazione di un generatore di numeri casuali normalmente distribuito in JavaScript:
Function Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; restituisce this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = new Gauss(); // crea un oggetto a = g.next(); // genera una coppia di valori e ottieni il primo b = g.next(); // ottieni il secondo c = g.next(); // genera di nuovo una coppia di valori e ottieni il primo
I parametri media (aspettativa matematica) e dev (deviazione standard) sono opzionali. Attiro la vostra attenzione sul fatto che il logaritmo è naturale.
