Uniformna slučajna distribucija. Pretvaranje jednoliko raspodijeljene slučajne varijable u normalno raspodijeljenu
Kao primjer kontinuirane slučajne varijable, razmotrite slučajnu varijablu X ravnomjerno raspoređenu u intervalu (a; b). Kaže se da je slučajna varijabla X ravnomjerno raspoređeno na intervalu (a; b), ako njegova gustoća raspodjele nije konstantna na tom intervalu:
Iz uvjeta normalizacije odredimo vrijednost konstante c. Površina ispod krivulje gustoće distribucije trebala bi biti jednaka jedinici, ali u našem slučaju to je površina pravokutnika s bazom (b - α) i visinom c (slika 1). 
Riža. 1 Uniformna gustoća distribucije
Odavde nalazimo vrijednost konstante c: ![]()
Dakle, gustoća jednoliko raspodijeljene slučajne varijable jednaka je 
Nađimo sada funkciju distribucije pomoću formule:
1) za ![]()
2) za
3) za 0+1+0=1.
Tako, 
Funkcija raspodjele je kontinuirana i ne opada (slika 2). 
Riža. 2 Funkcija distribucije jednoliko raspodijeljene slučajne varijable
Naći ćemo matematičko očekivanje jednoliko raspodijeljene slučajne varijable prema formuli:
Disperzija jednolike raspodjele izračunava se formulom i jednaka je
Primjer br. 1. Vrijednost podjeljka mjernog uređaja je 0,2. Očitanja instrumenta zaokružuju se na najbliži cijeli podjeli. Odredite vjerojatnost da će se tijekom brojanja napraviti pogreška: a) manja od 0,04; b) velika 0,02
Riješenje. Pogreška zaokruživanja je slučajna varijabla jednoliko raspoređena u intervalu između susjednih cjelobrojnih podjela. Promotrimo interval (0; 0,2) kao takvu podjelu (slika a). Zaokruživanje se može izvesti i prema lijevoj granici - 0, i prema desnoj - 0,2, što znači da se dva puta može napraviti pogreška manja ili jednaka 0,04, što se mora uzeti u obzir pri izračunavanju vjerojatnosti: 

P = 0,2 + 0,2 = 0,4
Za drugi slučaj, vrijednost pogreške također može premašiti 0,02 na obje granice podjele, odnosno može biti veća od 0,02 ili manja od 0,18. 
Tada je vjerojatnost greške poput ove:
Primjer br. 2. Pretpostavlja se da se stabilnost ekonomske situacije u zemlji (odsutnost ratova, prirodnih katastrofa itd.) u posljednjih 50 godina može procijeniti prema prirodi distribucije stanovništva prema dobi: u mirnoj situaciji trebalo bi biti uniforma. Kao rezultat istraživanja dobiveni su sljedeći podaci za jednu od zemalja.
Ima li razloga vjerovati da je u zemlji došlo do nestabilnosti?Rješenje izvodimo pomoću kalkulatora Provjera hipoteza. Tablica za izračunavanje pokazatelja.
| grupe | Sredina intervala, x i | Količina, f i | x i * f i | Akumulirana frekvencija, S | |x - x av |*f | (x - x prosj.) 2 *f | Frekvencija, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Prosječne težine
Indikatori varijacije.
Apsolutne varijacije.
Raspon varijacije je razlika između maksimalne i minimalne vrijednosti karakteristike primarne serije.
R = X max - X min
R = 70 - 0 = 70
Disperzija- karakterizira mjeru disperzije oko svoje prosječne vrijednosti (mjeru disperzije, tj. odstupanja od prosjeka).
Standardna devijacija.
Svaka vrijednost niza ne razlikuje se od prosječne vrijednosti 43 za najviše 23,92
Testiranje hipoteza o vrsti distribucije.
4. Testiranje hipoteze o jednolika raspodjela opća populacija.
Kako bi se testirala hipoteza o ravnomjernoj distribuciji X, tj. prema zakonu: f(x) = 1/(b-a) u intervalu (a,b)
potrebno:
1. Procijenite parametre a i b - krajeve intervala u kojem su promatrane moguće vrijednosti X, pomoću formula (znak * označava procjene parametara):
2. Odredite gustoću vjerojatnosti očekivane distribucije f(x) = 1/(b * - a *)
3. Pronađite teorijske frekvencije:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Usporedite empirijske i teorijske frekvencije koristeći Pearsonov kriterij, uzimajući broj stupnjeva slobode k = s-3, gdje je s broj početnih intervala uzorkovanja; ako je izvedena kombinacija malih frekvencija, a time i samih intervala, tada je s broj intervala preostalih nakon kombinacije.
Riješenje:
1. Pronađite procjene parametara a * i b * uniformne distribucije pomoću formula:
2. Odredite gustoću pretpostavljene jednolike raspodjele:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Nađimo teorijske frekvencije:
n 1 = n*f(x)(x 1 - a *) = 1 * 0,0121(10-1,58) = 0,1
n 8 = n*f(x)(b * - x 7) = 1 * 0,0121(84,42-70) = 0,17
Preostali n s će biti jednak:
n s = n*f(x)(x i - x i-1)
| ja | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Ukupno | 1 | 0.0532 |
Stoga je kritično područje za ovu statistiku uvijek desno: ako je njegova gustoća vjerojatnosti konstantna na ovom segmentu, a izvan njega jednaka je 0 (tj. slučajna varijabla x koncentriran na segment [ a, b], na kojoj ima konstantnu gustoću). Prema ovoj definiciji, gustoća jednoliko raspoređena na segmentu [ a, b] nasumična varijabla x ima oblik:
Gdje S postoji određeni broj. Međutim, lako ga je pronaći korištenjem svojstva gustoće vjerojatnosti za slučajne varijable koncentrirane na segmentu [ a,
b]:
 . Iz toga slijedi da
. Iz toga slijedi da  , gdje
, gdje  . Stoga je gustoća ravnomjerno raspoređena na segmentu [ a,
b] nasumična varijabla x ima oblik:
. Stoga je gustoća ravnomjerno raspoređena na segmentu [ a,
b] nasumična varijabla x ima oblik:
 .
.
Prosudite ravnomjernost raspodjele n.s.v. x moguće iz sljedećih razmatranja. Kontinuirana slučajna varijabla ima jednoliku raspodjelu na intervalu [ a, b], ako uzima vrijednosti samo iz ovog segmenta, a nijedan broj iz ovog segmenta nema prednost u odnosu na druge brojeve u ovom segmentu u smislu da može biti vrijednost ove slučajne varijable.
Slučajne varijable koje imaju jednoliku distribuciju uključuju vrijednosti kao što su vrijeme čekanja prijevoza na stajalištu (s konstantnim prometnim intervalom, trajanje čekanja je ravnomjerno raspoređeno u tom intervalu), pogreška u zaokruživanju broja na cijeli broj (jednoliko raspodijeljen preko [−0.5 , 0.5 ]) i drugi.
Vrsta distribucijske funkcije F(x)
a,
b] nasumična varijabla x pretraženo poznatom gustoćom vjerojatnosti f(x)
pomoću formule za njihovo povezivanje  . Kao rezultat odgovarajućih izračuna dobivamo sljedeću formulu za funkciju distribucije F(x)
ravnomjerno raspoređen segment [ a,
b] nasumična varijabla x
:
. Kao rezultat odgovarajućih izračuna dobivamo sljedeću formulu za funkciju distribucije F(x)
ravnomjerno raspoređen segment [ a,
b] nasumična varijabla x
:
 .
.
Slike prikazuju grafove gustoće vjerojatnosti f(x) i distribucijske funkcije f(x) ravnomjerno raspoređen segment [ a, b] nasumična varijabla x :


Očekivanje, varijanca, standardna devijacija, način i medijan ravnomjerno raspodijeljenog segmenta [ a, b] nasumična varijabla x izračunato gustoćom vjerojatnosti f(x) na uobičajeni način (i sasvim jednostavno zbog jednostavnog izgleda f(x) ). Rezultat su sljedeće formule:
i moda d(x) je bilo koji broj u intervalu [ a, b].
Nađimo vjerojatnost pogađanja ravnomjerno raspoređenog segmenta [ a,
b] nasumična varijabla x u intervalu  , potpuno leži unutra [ a,
b]. Uzimajući u obzir poznati oblik funkcije distribucije, dobivamo:
, potpuno leži unutra [ a,
b]. Uzimajući u obzir poznati oblik funkcije distribucije, dobivamo:
Dakle, vjerojatnost pogađanja ravnomjerno raspoređenog segmenta [ a,
b] nasumična varijabla x u intervalu  , potpuno leži unutra [ a,
b], ne ovisi o položaju tog intervala, već ovisi samo o njegovoj duljini i upravno je proporcionalan ovoj duljini.
, potpuno leži unutra [ a,
b], ne ovisi o položaju tog intervala, već ovisi samo o njegovoj duljini i upravno je proporcionalan ovoj duljini.
Primjer. Interval autobusa je 10 minuta. Kolika je vjerojatnost da će putnik koji dolazi na autobusnu stanicu čekati autobus manje od 3 minute? Koliko je prosječno vrijeme čekanja na autobus?
Normalna distribucija
Ova se raspodjela najčešće susreće u praksi i ima iznimnu ulogu u teoriji vjerojatnosti i matematičkoj statistici i njihovim primjenama, budući da takvu raspodjelu imaju mnoge slučajne varijable u prirodnim znanostima, ekonomiji, psihologiji, sociologiji, vojnim znanostima itd. Ova raspodjela je ograničavajući zakon, kojemu se (pod određenim prirodnim uvjetima) približavaju mnogi drugi zakoni raspodjele. Korištenjem normalnog zakona raspodjele opisuju se i pojave koje su podložne djelovanju mnogih neovisnih slučajnih čimbenika bilo koje prirode i bilo kojeg zakona njihove raspodjele. Prijeđimo na definicije.
Kontinuirana slučajna varijabla naziva se raspodijeljena normalni zakon (ili Gaussov zakon), ako njegova gustoća vjerojatnosti ima oblik:
 ,
,
gdje su brojke A I σ (σ>0 ) su parametri ove distribucije.
Kao što je već spomenuto, Gaussov zakon raspodjele slučajnih varijabli ima brojne primjene. Prema tom zakonu raspoređuju se pogreške mjerenja po instrumentima, odstupanje od centra mete pri gađanju, dimenzije izrađenih dijelova, težina i visina ljudi, godišnja količina oborina, broj novorođenčadi i još mnogo toga.
Dana formula za gustoću vjerojatnosti normalno raspodijeljene slučajne varijable sadrži, kao što je rečeno, dva parametra A I σ , te stoga definira obitelj funkcija koje variraju ovisno o vrijednostima ovih parametara. Ako primijenimo uobičajene metode matematičke analize proučavanja funkcija i crtanja grafova na gustoću vjerojatnosti normalne distribucije, možemo izvući sljedeće zaključke.

su njegove točke infleksije.
Na temelju primljenih informacija gradimo graf gustoće vjerojatnosti f(x) normalna raspodjela (naziva se Gaussova krivulja – slika).

Otkrijmo kako promjena parametara utječe A I σ na oblik Gaussove krivulje. Očito je (to se vidi iz formule za normalnu gustoću distribucije) da promjena parametra A ne mijenja oblik krivulje, već samo dovodi do njenog pomaka udesno ili ulijevo duž osi x. Ovisnost σ teže. Iz gornje studije jasno je kako vrijednost maksimuma i koordinate točaka infleksije ovise o parametru σ . Osim toga, moramo uzeti u obzir da za sve parametre A I σ površina ispod Gaussove krivulje ostaje jednaka 1 (ovo je opće svojstvo gustoće vjerojatnosti). Iz navedenog proizlazi da s porastom parametra σ krivulja postaje ravnija i rasteže se duž osi x. Slika prikazuje Gaussove krivulje za različite vrijednosti parametra σ (σ 1 < σ< σ 2 ) i istu vrijednost parametra A.

Otkrijmo probabilističko značenje parametara A I σ
normalna distribucija. Već iz simetričnosti Gaussove krivulje u odnosu na okomitu crtu koja prolazi kroz broj A na osi x jasno je da prosječna vrijednost (tj. matematičko očekivanje M(X)) normalno distribuirane slučajne varijable jednako je A. Iz istih razloga moda i medijan također trebaju biti jednaki broju a. Točni izračuni pomoću odgovarajućih formula to potvrđuju. Ako upotrijebimo gore napisani izraz za f(x)
zamijeniti u formulu za varijancu  , tada nakon (prilično kompliciranog) izračuna integrala dobivamo broj u odgovoru σ
2
. Dakle, za slučajnu varijablu x, raspodijeljene prema normalnom zakonu, dobivene su sljedeće glavne numeričke karakteristike:
, tada nakon (prilično kompliciranog) izračuna integrala dobivamo broj u odgovoru σ
2
. Dakle, za slučajnu varijablu x, raspodijeljene prema normalnom zakonu, dobivene su sljedeće glavne numeričke karakteristike:
Stoga je vjerojatnosno značenje parametara normalne razdiobe A I σ Sljedeći. Ako je r.v. xA I σ A σ.
Nađimo sada funkciju distribucije F(x)
za slučajnu varijablu x, raspodijeljen prema normalnom zakonu, koristeći gornji izraz za gustoću vjerojatnosti f(x)
i formula  . Prilikom zamjene f(x)
rezultat je "nepreuzet" integral. Sve što se može učiniti da se pojednostavi izraz za F(x),
Ovo je prikaz ove funkcije kao:
. Prilikom zamjene f(x)
rezultat je "nepreuzet" integral. Sve što se može učiniti da se pojednostavi izraz za F(x),
Ovo je prikaz ove funkcije kao:
 ,
,
Gdje F(x)− tzv Laplaceova funkcija, koji ima oblik
 .
.
Integral kroz koji je Laplaceova funkcija izražena također se ne uzima (ali za svaki x ovaj se integral može približno izračunati s bilo kojom unaprijed određenom točnošću). Međutim, nema potrebe za izračunavanjem, jer na kraju bilo kojeg udžbenika teorije vjerojatnosti postoji tablica za određivanje vrijednosti funkcije F(x) na zadanu vrijednost x. U nastavku će nam trebati svojstvo neobičnosti Laplaceove funkcije: F(−h)=−F(x) za sve brojeve x.
Nađimo sada vjerojatnost da normalno raspodijeljena r.v. xće uzeti vrijednost iz navedenog numeričkog intervala (α, β) . Iz općih svojstava funkcije raspodjele R(α< x< β)= F(β) − F(α) . Zamjena α I β u gornji izraz za F(x) , dobivamo
 .
.
Kao što je gore navedeno, ako je r.v. x normalno distribuiran s parametrima A I σ , tada je njegova prosječna vrijednost A, a standardna devijacija je jednaka σ. Zato prosjek odstupanje vrijednosti ove r.v. kada se testira iz broja A jednaki σ. Ali ovo je prosječno odstupanje. Stoga su moguća veća odstupanja. Doznajmo koliko su moguća određena odstupanja od prosječne vrijednosti. Nađimo vjerojatnost da je vrijednost slučajne varijable raspodijeljena prema normalnom zakonu x odstupaju od svoje prosječne vrijednosti M(X)=a manje od određenog broja δ, tj. R(| x− a|<δ ): . Tako,
 .
.
Zamjena u ovu jednakost δ=3σ, dobivamo vjerojatnost da vrijednost r.v. x(u jednom testu) će odstupati od prosječne vrijednosti za manje od trostruke vrijednosti σ (s prosječnim odstupanjem, kao što se sjećamo, jednakim σ ): (što znači F(3) preuzeto iz tablice vrijednosti Laplaceove funkcije). Skoro je 1 ! Tada je vjerojatnost suprotnog događaja (da će vrijednost odstupati ne manje od 3σ) jednako je 1 −0.997=0.003 , što je vrlo blizu 0 . Stoga je ovaj događaj “gotovo nemoguć” − događa se izuzetno rijetko (u prosjeku 3 istek vremena 1000 ). Ovo razmišljanje je obrazloženje za dobro poznato "pravilo tri sigme".
Pravilo tri sigme. Normalno distribuirana slučajna varijabla u jednom testu praktički ne odstupa od svog prosjeka dalje od 3σ.
Još jednom naglasimo da je riječ o jednom testu. Ako postoji mnogo testova slučajne varijable, tada je sasvim moguće da će se neke od njezinih vrijednosti kretati dalje od prosjeka od 3σ. To potvrđuje i sljedeće
Primjer. Kolika je vjerojatnost da u 100 pokušaja normalno raspodijeljene slučajne varijable x hoće li barem jedna njegova vrijednost odstupati od prosjeka za više od trostruke standardne devijacije? Što je s 1000 testova?
Riješenje. Neka događaj A znači da pri testiranju slučajne varijable x njegova vrijednost odstupala je od prosjeka za više od 3σ. Kao što je upravo razjašnjeno, vjerojatnost ovog događaja p=P(A)=0,003. Provedeno je 100 takvih testova. Moramo otkriti vjerojatnost da događaj A dogodilo se barem puta, tj. došao iz 1 prije 100 jednom. Ovo je tipičan problem Bernoullijevog kruga s parametrima n=100 (broj nezavisnih ispitivanja), p=0,003(vjerojatnost događaja A u jednom ogledu) q=1− str=0.997 . Treba pronaći R 100 (1≤ k≤100) . U ovom slučaju, naravno, lakše je prvo pronaći vjerojatnost suprotnog događaja R 100 (0) − vjerojatnost da događaj A nije se dogodilo niti jednom (tj. dogodilo se 0 puta). Uzimajući u obzir vezu između vjerojatnosti samog događaja i njegove suprotnosti, dobivamo:
Ne tako malo. Može se i dogoditi (u prosjeku se događa u svakoj četvrtoj takvoj seriji testova). Na 1000 ispitivanja koristeći istu shemu, može se dobiti da je vjerojatnost najmanje jednog odstupanja veća od 3σ, jednako je: . Stoga s velikom pouzdanošću možemo očekivati barem jedno takvo odstupanje.
Primjer. Visina muškaraca određene dobne skupine raspoređena je normalno s matematičkim očekivanjem a, i standardna devijacija σ . Koji udio odijela k rast treba uključiti u ukupnu proizvodnju za danu dobnu skupinu ako k Rast je određen sljedećim granicama:
1 visina : 158 − 164 cm 2 visina : 164 − 170 cm 3 visina : 170 − 176 cm 4 visina : 176 − 182 cm
Riješenje. Riješimo problem sa sljedećim vrijednostima parametara: a=178,σ=6,k=3
. Neka r.v. x
−
visina nasumično odabranog čovjeka (normalno je raspoređena sa zadanim parametrima). Nađimo vjerojatnost koja će biti potrebna nasumično odabranom čovjeku 3
-ta visina. Korištenje neparnosti Laplaceove funkcije F(x) i tablicu njegovih vrijednosti: P(170
Distribucija vjerojatnosti kontinuirane slučajne varijable x, uzimajući sve vrijednosti iz segmenta , Zove se uniforma, ako je njegova gustoća vjerojatnosti konstantna na ovom segmentu i jednaka nuli izvan njega. Dakle, gustoća vjerojatnosti kontinuirane slučajne varijable x, ravnomjerno raspoređen na segmentu , ima oblik:

Idemo definirati očekivana vrijednost, disperzija a za slučajnu varijablu s ravnomjernom raspodjelom.
, ![]() ,
, ![]() .
.
Primjer. Sve vrijednosti jednoliko raspodijeljene slučajne varijable leže na intervalu . Odredite vjerojatnost da slučajna varijabla padne u interval (3;5) .
a=2, b=8,  .
.
Binomna distribucija
Neka se proizvodi n testovi i vjerojatnost događanja događaja A u svakom pokušaju je jednak str i neovisan je o ishodu drugih pokusa (nezavisni pokusi). Budući da je vjerojatnost događanja događaja A u jednom testu je jednako str, tada je vjerojatnost njegovog nepojavljivanja jednaka q=1-p.
Neka događaj A ušao n testovi m jednom. Ovaj složeni događaj može se napisati kao proizvod:
![]() .
.
Tada je vjerojatnost da n ispitni događaj A doći će m puta, izračunato po formuli:
![]() ili
ili ![]() (1)
(1)
Formula (1) se zove Bernoullijeva formula.
Neka x– slučajna varijabla jednaka broju pojavljivanja događaja A V n testovi, koji uzimaju vrijednosti s vjerojatnostima:
Rezultirajući zakon raspodjele slučajne varijable naziva se zakon binomne distribucije.
| x | m | n | ||||
| P |
Očekivana vrijednost, disperzija I standardna devijacija slučajne varijable raspoređene prema binomnom zakonu određene su formulama:
, , .
Primjer. U metu se ispaljuju tri hica, a vjerojatnost pogotka svakog hica je 0,8. Razmotrimo slučajnu varijablu x– broj pogodaka u metu. Nađite njegov zakon distribucije, matematičko očekivanje, disperziju i standardnu devijaciju.
p=0,8, q=0,2, n=3, ![]() , ,
, , ![]() .
.
![]() - vjerojatnost 0 pogodaka;
- vjerojatnost 0 pogodaka;
Mogućnost jednog pogotka;
Šansa za dva pogotka;
![]() - vjerojatnost tri pogotka.
- vjerojatnost tri pogotka.
Dobivamo zakon distribucije:
| x | ||||
| P | 0,008 | 0,096 | 0,384 | 0,512 |
Zadaci
1. Novčić se baca 7 puta. Odredite vjerojatnost da će sletjeti naopako 4 puta.
2. Novčić se baca 8 puta. Nađite vjerojatnost da se grb ne pojavi više od tri puta.
3. Vjerojatnost pogotka mete pucanjem iz puške p=0,6. Nađite matematičko očekivanje ukupnog broja pogodaka ako je ispaljeno 10 hitaca.
4. Nađite matematičko očekivanje broja lutrijskih listića koji će dobiti ako se kupi 20 listića, a vjerojatnost dobitka na jednom listiću je 0,3.
Funkcija distribucije u ovom slučaju, prema (5.7), će imati oblik:
gdje je: m – matematičko očekivanje, s – standardna devijacija.
Normalna distribucija se također naziva Gaussovom po njemačkom matematičaru Gaussu. Činjenica da slučajna varijabla ima normalnu distribuciju s parametrima: m, označava se na sljedeći način: N (m,s), gdje je: m =a =M ;
Često se u formulama matematičko očekivanje označava sa A . Ako je slučajna varijabla raspodijeljena prema zakonu N(0,1), tada se naziva normalizirana ili standardizirana normalna varijabla. Funkcija distribucije za njega ima oblik:
|
|
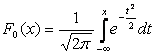 .
.Grafikon gustoće normalne distribucije, koji se naziva normalna krivulja ili Gaussova krivulja, prikazan je na slici 5.4.

Riža. 5.4. Normalna gustoća distribucije
Na primjeru se razmatra određivanje numeričkih karakteristika slučajne varijable njezinom gustoćom.
Primjer 6.
Kontinuirana slučajna varijabla određena je gustoćom distribucije: ![]() .
.
Odrediti tip distribucije, pronaći matematičko očekivanje M(X) i varijancu D(X).
Uspoređujući zadanu gustoću raspodjele s (5.16), možemo zaključiti da je dan normalni zakon raspodjele s m = 4. Dakle, matematičko očekivanje M(X)=4, varijanca D(X)=9.
Standardna devijacija s=3.
Laplaceova funkcija koja ima oblik:
|
|
 ,
,povezana je s normalnom funkcijom distribucije (5.17), relacija:
F 0 (x) = F(x) + 0,5.
Laplaceova funkcija je neparna.
F(-x)=-F(x).
Vrijednosti Laplaceove funkcije F(h) prikazane su u tabeli i preuzete iz tablice prema vrijednosti x (vidi Dodatak 1).
Normalna distribucija kontinuirane slučajne varijable igra važnu ulogu u teoriji vjerojatnosti i u opisivanju stvarnosti; vrlo je raširena u slučajnim prirodnim pojavama. U praksi se vrlo često susrećemo sa slučajnim varijablama koje nastaju upravo kao rezultat zbrajanja mnogih slučajnih članova. Konkretno, analiza pogrešaka mjerenja pokazuje da su one zbroj raznih vrsta pogrešaka. Praksa pokazuje da je distribucija vjerojatnosti pogrešaka mjerenja bliska normalnom zakonu.
Pomoću Laplaceove funkcije možete riješiti problem izračuna vjerojatnosti upadanja u zadani interval i zadano odstupanje normalne slučajne varijable.
Ovo se pitanje odavno detaljno proučava, a najraširenija metoda je metoda polarnih koordinata koju su predložili George Box, Mervyn Muller i George Marsaglia 1958. godine. Ova metoda vam omogućuje da dobijete par neovisnih normalno distribuiranih slučajnih varijabli s matematičkim očekivanjem 0 i varijancom 1 kako slijedi:
Gdje su Z 0 i Z 1 željene vrijednosti, s = u 2 + v 2, a u i v su slučajne varijable jednoliko raspoređene na intervalu (-1, 1), odabrane na takav način da je uvjet 0 zadovoljen< s < 1.
Mnogi ljudi koriste ove formule bez razmišljanja, a mnogi čak i ne sumnjaju u njihovo postojanje, budući da koriste gotove implementacije. Ali postoje ljudi koji imaju pitanja: “Odakle je došla ova formula? A zašto dobivate nekoliko količina odjednom?” Zatim ću pokušati dati jasan odgovor na ova pitanja.
Za početak da vas podsjetim što su gustoća vjerojatnosti, funkcija distribucije slučajne varijable i inverzna funkcija. Pretpostavimo da postoji određena slučajna varijabla čija je distribucija određena funkcijom gustoće f(x) koja ima sljedeći oblik:

To znači da je vjerojatnost da će vrijednost zadane slučajne varijable biti u intervalu (A, B) jednaka površini osjenčanog područja. I kao posljedica toga, područje cijelog osjenčanog područja mora biti jednako jedan, jer će u svakom slučaju vrijednost slučajne varijable pasti u domenu definicije funkcije f.
Funkcija distribucije slučajne varijable je integral funkcije gustoće. I u ovom slučaju, njegov će približni izgled biti ovakav:

Ovdje je značenje da će vrijednost slučajne varijable biti manja od A s vjerojatnošću B. I kao posljedica toga, funkcija se nikada ne smanjuje, a njezine vrijednosti leže u intervalu.
Inverzna funkcija je funkcija koja vraća argument izvornoj funkciji ako je vrijednost izvorne funkcije proslijeđena u nju. Na primjer, za funkciju x 2 inverzna je funkcija izvlačenja korijena, za sin(x) to je arcsin(x), itd.
Budući da većina generatora pseudoslučajnih brojeva proizvodi samo jednoliku distribuciju kao izlaz, često postoji potreba da se ona pretvori u neku drugu. U ovom slučaju, na normalni Gaussov:

Osnova svih metoda za pretvaranje uniformne distribucije u bilo koju drugu je metoda inverzne transformacije. Radi na sljedeći način. Nađe se funkcija koja je inverzna funkciji tražene distribucije, a kao argument joj se proslijedi slučajna varijabla jednoliko raspodijeljena na intervalu (0, 1). Na izlazu dobivamo vrijednost sa traženom distribucijom. Radi jasnoće, dajem sljedeću sliku.

Dakle, uniformni segment je, takoreći, razmazan u skladu s novom distribucijom, projiciran na drugu os kroz inverznu funkciju. Ali problem je u tome što integral gustoće Gaussove distribucije nije lako izračunati, pa su gornji znanstvenici morali varati.
Postoji hi-kvadrat distribucija (Pearsonova distribucija), koja je distribucija zbroja kvadrata k nezavisnih normalnih slučajnih varijabli. A u slučaju kada je k = 2, ova raspodjela je eksponencijalna.

To znači da ako točka u pravokutnom koordinatnom sustavu ima nasumične X i Y koordinate raspoređene normalno, tada nakon pretvorbe tih koordinata u polarni sustav (r, θ), kvadrat polumjera (udaljenost od ishodišta do točke) raspodijelit će se prema eksponencijalnom zakonu, jer je kvadrat polumjera zbroj kvadrata koordinata (prema Pitagorinom zakonu). Gustoća distribucije takvih točaka na ravnini izgledat će ovako:


Budući da je jednak u svim smjerovima, kut θ će imati jednoliku raspodjelu u rasponu od 0 do 2π. Vrijedi i obrnuto: ako definirate točku u polarnom koordinatnom sustavu koristeći dvije neovisne slučajne varijable (kut raspoređen jednoliko i radijus raspoređen eksponencijalno), tada će pravokutne koordinate te točke biti neovisne normalne slučajne varijable. I mnogo je lakše dobiti eksponencijalnu distribuciju iz jednolike distribucije koristeći istu metodu inverzne transformacije. Ovo je bit polarne Box-Mullerove metode.
Izvedimo sada formule.
![]() (1)
(1)
Da bi se dobili r i θ, potrebno je generirati dvije slučajne varijable jednoliko raspoređene na intervalu (0, 1) (nazovimo ih u i v), od kojih se distribucija jedne (recimo v) mora pretvoriti u eksponencijalnu u dobiti radijus. Funkcija eksponencijalne distribucije izgleda ovako:
Njegova inverzna funkcija je:
![]()
Budući da je uniformna distribucija simetrična, transformacija će raditi na sličan način s funkcijom
![]()
Iz formule hi-kvadrat distribucije slijedi da je λ = 0,5. Zamijenite λ, v u ovu funkciju i dobijete kvadrat polumjera, a zatim i sam polumjer:

Kut dobivamo rastezanjem jediničnog segmenta na 2π:
Sada zamijenimo r i θ u formule (1) i dobijemo:
 (2)
(2)
Ove formule su već spremne za upotrebu. X i Y će biti neovisni i normalno raspodijeljeni s varijancom od 1 i matematičkim očekivanjem od 0. Da bi se dobila distribucija s drugim karakteristikama, dovoljno je pomnožiti rezultat funkcije sa standardnom devijacijom i dodati matematičko očekivanje.
Ali moguće je riješiti se trigonometrijskih funkcija navođenjem kuta ne izravno, već neizravno kroz pravokutne koordinate slučajne točke u krugu. Zatim će pomoću tih koordinata biti moguće izračunati duljinu radijus vektora, a zatim pronaći kosinus i sinus dijeljenjem x odnosno y s njima. Kako i zašto radi?
Odaberimo slučajnu točku među onima koje su ravnomjerno raspoređene u krugu jediničnog polumjera i označimo kvadrat duljine radijus vektora te točke slovom s:

Odabir se vrši navođenjem slučajnih pravokutnih koordinata x i y, jednoliko raspoređenih u intervalu (-1, 1), i odbacivanjem točaka koje ne pripadaju kružnici, kao i središnje točke u kojoj je kut radijus vektora nije definiran. Odnosno, uvjet 0 mora biti ispunjen< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Dobivamo formule kao na početku članka. Nedostatak ove metode je što odbacuje točke koje nisu uključene u krug. To jest, koristeći samo 78,5% generiranih slučajnih varijabli. Na starijim računalima nedostatak trigonometrijskih funkcija još uvijek je bio velika prednost. Sada, kada jedna procesorska naredba izračuna i sinus i kosinus u trenu, mislim da se ove metode još uvijek mogu natjecati.
Osobno imam još dva pitanja:
- Zašto je vrijednost s ravnomjerno raspoređena?
- Zašto je zbroj kvadrata dviju normalnih slučajnih varijabli raspodijeljen eksponencijalno?

Ako se slična transformacija napravi za normalnu slučajnu varijablu, tada će se funkcija gustoće njenog kvadrata pokazati sličnom hiperboli. A zbrajanje dvaju kvadrata normalnih slučajnih varijabli mnogo je složeniji proces povezan s dvostrukom integracijom. A činjenicu da će rezultat biti eksponencijalna distribucija, ja osobno moram provjeriti samo praktičnom metodom ili prihvatiti kao aksiom. A za one koji su zainteresirani, predlažem da pobliže pogledaju temu, stječući znanje iz ovih knjiga:
- Ventzel E.S. Teorija vjerojatnosti
- Knut D.E. Umijeće programiranja, svezak 2
U zaključku, ovdje je primjer implementacije normalno distribuiranog generatora slučajnih brojeva u JavaScriptu:
Function Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1,0; s = u * u + v * v; ) while (s > 1,0 || s == 0,0); var r = Math.sqrt(-2,0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = new Gauss(); // kreiraj objekt a = g.next(); // generiraj par vrijednosti i dobij prvu b = g.next(); // dobijemo drugi c = g.next(); // ponovno generirajte par vrijednosti i uzmite prvu
Parametri srednja vrijednost (matematičko očekivanje) i dev (standardna devijacija) nisu obavezni. Skrećem vam pozornost na činjenicu da je logaritam prirodan.
