Düzgün rastgele dağılım. Düzgün dağılmış bir rastgele değişkeni normal dağılmış bir rastgele değişkene dönüştürme
Sürekli rastgele değişkene örnek olarak, (a; b) aralığı boyunca düzgün şekilde dağılmış bir X rastgele değişkenini düşünün. Rastgele değişken X'in olduğu söyleniyor eşit olarak dağıtılmış (a; b) aralığında, eğer dağılım yoğunluğu bu aralıkta sabit değilse:
Normalleştirme koşulundan c sabitinin değerini belirleriz. Dağılım yoğunluk eğrisinin altındaki alan birliğe eşit olmalıdır, ancak bizim durumumuzda tabanı (b - α) ve yüksekliği c olan bir dikdörtgenin alanıdır (Şekil 1). 
Pirinç. 1 Düzgün dağıtım yoğunluğu
Buradan c sabitinin değerini buluruz: ![]()
Dolayısıyla, düzgün dağılmış bir rastgele değişkenin yoğunluğu şuna eşittir: 
Şimdi aşağıdaki formülü kullanarak dağıtım fonksiyonunu bulalım:
1) için ![]()
2) için
3) 0+1+0=1 için.
Böylece, 
Dağıtım fonksiyonu süreklidir ve azalmaz (Şekil 2). 
Pirinç. 2 Düzgün dağıtılmış bir rastgele değişkenin dağılım fonksiyonu
bulacağız düzgün dağılmış bir rastgele değişkenin matematiksel beklentisi formüle göre:
Düzgün dağılımın dağılımı formülle hesaplanır ve eşittir
Örnek No.1. Ölçüm cihazının ölçek bölme değeri 0,2'dir. Cihaz okumaları en yakın tam bölüme yuvarlanır. Sayım sırasında hata yapılma olasılığını bulun: a) 0,04'ten az; b) büyük 0,02
Çözüm. Yuvarlama hatası, bitişik tamsayı bölümleri arasındaki aralığa eşit olarak dağıtılan rastgele bir değişkendir. (0; 0.2) aralığını böyle bir bölme olarak ele alalım (Şekil a). Yuvarlama hem sol kenarlığa doğru - 0, hem de sağa - 0,2 yapılabilir; bu, 0,04'ten küçük veya ona eşit bir hatanın iki kez yapılabileceği anlamına gelir; bu, olasılık hesaplanırken dikkate alınmalıdır: 

P = 0,2 + 0,2 = 0,4
İkinci durumda ise hata değeri her iki bölme sınırında da 0,02'yi aşabilir, yani 0,02'den büyük veya 0,18'den küçük olabilir. 
O zaman şöyle bir hata olasılığı:
Örnek No. 2. Ülkedeki ekonomik durumun son 50 yıldaki istikrarının (savaşların olmaması, doğal afetler vb.), yaşa göre nüfus dağılımının niteliğine göre değerlendirilebileceği varsayılmıştır: sakin bir durumda olması gerekir üniforma. Çalışma sonucunda ülkelerden biri için aşağıdaki veriler elde edildi.
Ülkede istikrarsızlık olduğuna inanmak için herhangi bir neden var mı?Çözümü bir hesap makinesi kullanarak hipotezleri test ediyoruz.. Göstergelerin hesaplanması için tablo.
| Gruplar | Aralığın orta noktası, x i | Miktar, f i | x ben * f ben | Birikmiş frekans, S | |x - x ort |*f | (x - x ort) 2 *f | Frekans, f i / n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Ağırlıklı ortalama
Değişim göstergeleri.
Mutlak varyasyonlar.
Değişim aralığı, birincil seri karakteristiğinin maksimum ve minimum değerleri arasındaki farktır.
R = X maks - X min
R = 70 - 0 = 70
Dağılım- ortalama değeri etrafındaki dağılım ölçüsünü karakterize eder (bir dağılım ölçüsü, yani ortalamadan sapma).
Standart sapma.
Serinin her değeri ortalama 43 değerinden 23,92'den fazla farklılık göstermez.
Dağıtım türüne ilişkin hipotezlerin test edilmesi.
4. Hipotezin test edilmesi düzgün dağılım genel nüfus.
X'in düzgün dağılımı hakkındaki hipotezi test etmek için, yani. kanuna göre: (a,b) aralığında f(x) = 1/(b-a)
gerekli:
1. a ve b parametrelerini tahmin edin - formülleri kullanarak olası X değerlerinin gözlemlendiği aralığın uçları (* işareti parametre tahminlerini gösterir):
2. Beklenen f(x) = 1/(b * - a *) dağılımının olasılık yoğunluğunu bulun.
3. Teorik frekansları bulun:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Serbestlik derecesi sayısını k = s-3 alarak Pearson kriterini kullanarak ampirik ve teorik frekansları karşılaştırın; burada s, başlangıçtaki örnekleme aralıklarının sayısıdır; küçük frekansların ve dolayısıyla aralıkların bir kombinasyonu gerçekleştirilmişse, o zaman s, kombinasyondan sonra kalan aralıkların sayısıdır.
Çözüm:
1. Aşağıdaki formülleri kullanarak tekdüze dağılımın a * ve b * parametrelerinin tahminlerini bulun:
2. Varsayılan tekdüze dağılımın yoğunluğunu bulun:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Teorik frekansları bulalım:
n 1 = n*f(x)(x 1 - a *) = 1 * 0,0121(10-1,58) = 0,1
n 8 = n*f(x)(b * - x 7) = 1 * 0,0121(84,42-70) = 0,17
Geriye kalan n'ler şuna eşit olacaktır:
n s = n*f(x)(x i - x i-1)
| Ben | n ben | hayır | n ben - n * ben | (n ben - n* ben) 2 | (n ben - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Toplam | 1 | 0.0532 |
Bu nedenle, bu istatistiğin kritik bölgesi her zaman sağ taraftadır: olasılık yoğunluğu bu segmentte sabitse ve dışında 0'a eşitse (yani rastgele bir değişken) X segmente yoğunlaştık [ A, B], üzerinde sabit bir yoğunluğa sahiptir). Bu tanıma göre yoğunluk segment üzerinde düzgün bir şekilde dağılmıştır. A, B] rastgele değişken Xşu forma sahiptir:
Nerede İle belli bir sayı var. Bununla birlikte, segment üzerinde yoğunlaşan rastgele değişkenler için olasılık yoğunluğu özelliğini kullanarak bulmak kolaydır. A,
B]:
 . Şunu takip ediyor
. Şunu takip ediyor  , Neresi
, Neresi  . Bu nedenle, yoğunluk segment üzerinde düzgün bir şekilde dağılmıştır [ A,
B] rastgele değişken Xşu forma sahiptir:
. Bu nedenle, yoğunluk segment üzerinde düzgün bir şekilde dağılmıştır [ A,
B] rastgele değişken Xşu forma sahiptir:
 .
.
N.s.v.'nin dağılımının tekdüzeliğini değerlendirin. X aşağıdaki değerlendirmelerden mümkündür. Sürekli bir rastgele değişken, aralıkta düzgün bir dağılıma sahiptir [ A, B], eğer sadece bu segmentten değer alıyorsa ve bu segmentteki herhangi bir sayının, bu rastgele değişkenin bir değeri olabilmesi anlamında bu segmentteki diğer sayılara göre bir avantajı yoktur.
Düzgün bir dağılıma sahip rastgele değişkenler, bir durakta ulaşım için bekleme süresi (sabit bir trafik aralığında, bekleme süresi bu aralığa eşit olarak dağıtılır), bir sayının bir tam sayıya yuvarlanma hatası (üzerine eşit olarak dağıtılır) gibi miktarları içerir. [−0,5 , 0.5 ]) ve diğerleri.
Dağıtım fonksiyonu türü F(X)
A,
B] rastgele değişken X bilinen olasılık yoğunluğuna göre aranır F(X)
bağlantıları için formülü kullanma  . İlgili hesaplamalar sonucunda dağıtım fonksiyonu için aşağıdaki formülü elde ederiz. F(X)
düzgün dağıtılmış bölüm [ A,
B] rastgele değişken X
:
. İlgili hesaplamalar sonucunda dağıtım fonksiyonu için aşağıdaki formülü elde ederiz. F(X)
düzgün dağıtılmış bölüm [ A,
B] rastgele değişken X
:
 .
.
Şekiller olasılık yoğunluk grafiklerini göstermektedir F(X) ve dağıtım fonksiyonları F(X) düzgün dağıtılmış bölüm [ A, B] rastgele değişken X :


Düzgün dağıtılmış bir segmentin beklentisi, varyansı, standart sapması, modu ve medyanı [ A, B] rastgele değişken X olasılık yoğunluğu ile hesaplanır F(X) her zamanki gibi (ve oldukça basit bir görünüm nedeniyle) F(X) ). Sonuç aşağıdaki formüllerdir:
ve moda D(X) aralıktaki herhangi bir sayıdır [ A, B].
Düzgün dağılmış bir parçaya çarpma olasılığını bulalım [ A,
B] rastgele değişken X aralıkta  , tamamen içeride yatıyor [ A,
B] Dağıtım fonksiyonunun bilinen formunu dikkate alarak şunu elde ederiz:
, tamamen içeride yatıyor [ A,
B] Dağıtım fonksiyonunun bilinen formunu dikkate alarak şunu elde ederiz:
Böylece, düzgün dağılmış bir parçaya çarpma olasılığı [ A,
B] rastgele değişken X aralıkta  , tamamen içeride yatıyor [ A,
B], bu aralığın konumuna bağlı değildir, yalnızca uzunluğuna bağlıdır ve bu uzunlukla doğru orantılıdır.
, tamamen içeride yatıyor [ A,
B], bu aralığın konumuna bağlı değildir, yalnızca uzunluğuna bağlıdır ve bu uzunlukla doğru orantılıdır.
Örnek. Otobüs aralığı 10 dakikadır. Otobüs durağına gelen bir yolcunun otobüsü 3 dakikadan az bekleme olasılığı nedir? Otobüs için ortalama bekleme süresi nedir?
Normal dağılım
Bu dağılıma pratikte en sık rastlanır ve doğa bilimleri, ekonomi, psikoloji, sosyoloji, askeri bilimler ve benzeri alanlardaki birçok rastgele değişkenin böyle bir dağılıma sahip olması nedeniyle olasılık teorisinde, matematiksel istatistiklerde ve bunların uygulamalarında istisnai bir rol oynar. Bu dağıtım, diğer birçok dağıtım kanununun (belirli doğal koşullar altında) yaklaştığı sınırlayıcı bir yasadır. Normal dağılım yasasını kullanarak, herhangi bir nitelikteki birçok bağımsız rastgele faktörün ve bunların herhangi bir dağılım yasasının etkisine tabi olan olaylar da açıklanmaktadır. Tanımlara geçelim.
Sürekli bir rastgele değişkene dağıtılmış denir normal yasa (veya Gauss yasası) Olasılık yoğunluğu şu şekilde ise:
 ,
,
sayılar nerede A Ve σ (σ>0 ) bu dağılımın parametreleridir.
Daha önce de belirtildiği gibi, Gauss'un rastgele değişkenlerin dağılım yasasının çok sayıda uygulaması vardır. Bu yasaya göre aletlerle yapılan ölçüm hataları, atış sırasında hedefin merkezinden sapma, üretilen parçaların boyutları, insanların ağırlık ve boyları, yıllık yağış, yenidoğan sayısı ve çok daha fazlası dağıtılır.
Normal dağılmış bir rastgele değişkenin olasılık yoğunluğu için verilen formül, söylendiği gibi, iki parametre içerir. A Ve σ ve dolayısıyla bu parametrelerin değerlerine bağlı olarak değişen bir fonksiyon ailesini tanımlar. Fonksiyonları incelemek ve grafikleri çizmek için olağan matematiksel analiz yöntemlerini normal bir dağılımın olasılık yoğunluğuna uygularsak, aşağıdaki sonuçları çıkarabiliriz.

onun dönüm noktalarıdır.
Alınan bilgilere dayanarak bir olasılık yoğunluk grafiği oluşturuyoruz F(X) normal dağılım (buna Gauss eğrisi denir - şekil).

Parametreleri değiştirmenin nasıl etkilediğini öğrenelim A Ve σ Gauss eğrisinin şekline. Parametrede bir değişikliğin olacağı açıktır (bu normal dağılım yoğunluğu formülünden görülebilir). A eğrinin şeklini değiştirmez, yalnızca eksen boyunca sağa veya sola kaymasına neden olur X. Bağımlılık σ daha zor. Yukarıdaki çalışmadan maksimum değerinin ve bükülme noktalarının koordinatlarının parametreye nasıl bağlı olduğu açıktır. σ . Ek olarak, herhangi bir parametre için şunu dikkate almalıyız: A Ve σ Gauss eğrisinin altındaki alan 1'e eşit kalır (bu, olasılık yoğunluğunun genel bir özelliğidir). Yukarıdakilerden, parametrenin artmasıyla şu sonucu çıkar: σ eğri düzleşir ve eksen boyunca uzar X. Şekil, parametrenin farklı değerleri için Gauss eğrilerini göstermektedir. σ (σ 1 < σ< σ 2 ) ve aynı parametre değeri A.

Parametrelerin olasılıksal anlamını bulalım A Ve σ
normal dağılım. Zaten Gauss eğrisinin sayıdan geçen dikey çizgiye göre simetrisinden A eksende X ortalama değerin (yani matematiksel beklentinin) olduğu açıktır. M(X) Normal dağılım gösteren bir rastgele değişkenin ) değeri şuna eşittir: A. Aynı nedenlerden dolayı mod ve medyanın da a sayısına eşit olması gerekir. Uygun formüllerin kullanıldığı doğru hesaplamalar bunu doğrulamaktadır. Yukarıdaki ifadeyi kullanırsak F(X)
varyans formülünün yerine koyun  , integralin (oldukça karmaşık) bir hesaplamasından sonra cevaptaki sayıyı elde ederiz σ
2
. Yani bir rastgele değişken için X normal yasaya göre dağıtıldığında aşağıdaki ana sayısal özellikler elde edildi:
, integralin (oldukça karmaşık) bir hesaplamasından sonra cevaptaki sayıyı elde ederiz σ
2
. Yani bir rastgele değişken için X normal yasaya göre dağıtıldığında aşağıdaki ana sayısal özellikler elde edildi:
Bu nedenle normal dağılım parametrelerinin olasılıksal anlamı A Ve σ Sonraki. Eğer r.v. XA Ve σ A σ.
Şimdi dağıtım fonksiyonunu bulalım F(X)
rastgele bir değişken için X olasılık yoğunluğu için yukarıdaki ifadeyi kullanarak normal yasaya göre dağıtılır F(X)
ve formül  . Değiştirirken F(X)
sonuç “alınmamış” bir integraldir. İfadeyi basitleştirmek için yapılabilecek her şey F(X),
Bu fonksiyonun temsili şu şekildedir:
. Değiştirirken F(X)
sonuç “alınmamış” bir integraldir. İfadeyi basitleştirmek için yapılabilecek her şey F(X),
Bu fonksiyonun temsili şu şekildedir:
 ,
,
Nerede F(x)- sözde Laplace işlevi formuna sahip olan
 .
.
Laplace fonksiyonunun ifade edildiği integral de alınmaz (ancak her biri için) X bu integral önceden belirlenmiş herhangi bir doğrulukla yaklaşık olarak hesaplanabilir). Bununla birlikte, olasılık teorisi üzerine herhangi bir ders kitabının sonunda fonksiyonun değerlerini belirlemek için bir tablo bulunduğundan, bunu hesaplamaya gerek yoktur. F(x) belirli bir değerde X. Aşağıda Laplace fonksiyonunun tuhaflık özelliğine ihtiyacımız olacak: Ф(−х)=−F(x) tüm sayılar için X.
Şimdi normal dağılmış bir r.v. olasılığını bulalım. X belirtilen sayısal aralıktan bir değer alacaktır (α, β) . Dağıtım fonksiyonunun genel özelliklerinden R(α< X< β)= F(β) − F(α) . Değiştirme α Ve β için yukarıdaki ifadeye F(X) , alıyoruz
 .
.
Yukarıda belirtildiği gibi, eğer r.v. X parametrelerle normal olarak dağıtılır A Ve σ , o zaman ortalama değeri A ve standart sapma eşittir σ. Bu yüzden ortalama bu r.v.'nin değerlerinin sapması. numaradan test edildiğinde A eşittir σ. Ancak bu ortalama sapmadır. Bu nedenle daha büyük sapmalar mümkündür. Ortalama değerden belirli sapmaların ne kadar mümkün olduğunu bulalım. Bir rastgele değişkenin değerinin normal kanuna göre dağılma olasılığını bulalım. X ortalama değerinden sapmak M(X)=a belirli bir δ sayısından daha az, yani R(| X− A|<δ ): . Böylece,
 .
.
Bu eşitliği yerine koyarsak δ=3σ r.v değerinin olasılığını elde ederiz. X(bir testte) ortalama değerden değerin üç katından daha az sapacaktır σ (hatırladığımız gibi ortalama sapma şuna eşittir: σ ): (Anlam F(3) Laplace fonksiyon değerleri tablosundan alınmıştır). neredeyse 1 ! Daha sonra ters olayın olasılığı (değerin en az 3σ) eşittir 1 −0.997=0.003 , ki buna çok yakın 0 . Dolayısıyla bu olay “neredeyse imkansız” − son derece nadiren olur (ortalama olarak 3 zaman aşımı 1000 ). Bu akıl yürütme, iyi bilinen “üç sigma kuralının” mantığıdır.
Üç sigma kuralı. Normal dağılmış rastgele değişken tek bir testte pratikte ortalamasından daha fazla sapmaz 3σ.
Tek bir testten bahsettiğimizi bir kez daha vurgulayalım. Rastgele bir değişkenin çok sayıda testi varsa, bazı değerlerinin ortalamadan daha da ileri gitmesi oldukça olasıdır. 3σ. Bu aşağıdakiler tarafından onaylanmıştır
Örnek. Normal dağılım gösteren bir rastgele değişkenin 100 denemede ortaya çıkma olasılığı nedir? X Değerlerinden en az biri ortalamadan standart sapmanın üç katından fazla sapacak mı? Peki ya 1000 test?
Çözüm. Hadi olay A rastgele bir değişkeni test ederken anlamına gelir X değeri ortalamadan daha fazla saptı 3σ. Az önce açıklandığı gibi, bu olayın olasılığı p=P(A)=0,003. Bu tür 100 test gerçekleştirildi. Olayın gerçekleşme olasılığını bulmamız gerekiyor. A olmuş en azından kez, yani geldi 1 ile 100 bir kere. Bu parametrelerle ilgili tipik bir Bernoulli devresi problemidir N=100 (bağımsız denemelerin sayısı), p=0,003(olayın olasılığı A bir denemede) Q=1− P=0.997 . Bulması gerekiyor R 100 (1≤ k≤100) . Bu durumda elbette öncelikle ters olayın olasılığını bulmak daha kolaydır. R 100 (0) − olayın gerçekleşme olasılığı A bir kez bile olmadı (yani 0 kez oldu). Olayın kendisinin ve tersinin olasılıkları arasındaki bağlantıyı dikkate alarak şunu elde ederiz:
O kadar da az değil. Bu pekâlâ gerçekleşebilir (ortalama olarak bu tür testlerin her dördüncüsünde meydana gelir). Şu tarihte: 1000 aynı şemayı kullanan testlerde, en az bir sapma olasılığının şundan daha fazla olduğu elde edilebilir: 3σ, eşittir: . Dolayısıyla bu türden en az bir sapmayı büyük bir güvenle bekleyebiliriz.
Örnek. Belirli bir yaş grubundaki erkeklerin boyu matematiksel beklentiyle normal olarak dağılmaktadır. A ve standart sapma σ . Takım elbiselerin oranı ne kadar k belirli bir yaş grubu için büyümenin toplam üretime dahil edilmesi gerekir; k Büyüme aşağıdaki sınırlarla belirlenir:
1 yükseklik : 158 − 164cm2 yükseklik : 164 − 170cm3 yükseklik : 170 − 176cm 4 yükseklik : 176 – 182cm
Çözüm. Aşağıdaki parametre değerleriyle sorunu çözelim: a=178,σ=6,k=3
. X
−
R.v.'ye izin ver. 3
Rastgele seçilen bir adamın boyu (verilen parametrelerle normal şekilde dağıtılır). Rastgele seçilen bir adamın ihtiyaç duyacağı olasılığı bulalım. F(x)-inci yükseklik. Laplace fonksiyonunun tuhaflığını kullanma ve değerlerinin bir tablosu:
-inci yükseklik. X Sürekli bir rastgele değişkenin olasılık dağılımı , segmentteki tüm değerleri alarak üniforma, isminde X Olasılık yoğunluğu bu segmentte sabitse ve onun dışında sıfıra eşitse. Böylece sürekli bir rastgele değişkenin olasılık yoğunluğu segment üzerinde eşit olarak dağıtılmış

, şu forma sahiptir: Hadi tanımlayalım, matematiksel beklenti dağılım
, ![]() ,
, ![]() .
.
ve düzgün dağılıma sahip bir rastgele değişken için.Örnek. Düzgün dağıtılmış bir rastgele değişkenin tüm değerleri aralıkta yer alır (3;5) .
. Bir rastgele değişkenin aralığa düşme olasılığını bulun  .
.
a=2, b=8,
Binom dağılımı NÜretilsin Testler ve olayın meydana gelme olasılığı A P her denemede eşittir Testler ve olayın meydana gelme olasılığı ve diğer araştırmaların (bağımsız araştırmaların) sonuçlarından bağımsızdır. Bir olayın gerçekleşme olasılığı olduğundan P bir testte eşittir , o zaman oluşmama olasılığı eşittir.
q=1-p Testler ve olayın meydana gelme olasılığı Hadi olay N içeri girdi testler M
![]() .
.
bir kere. Bu karmaşık olay bir ürün olarak yazılabilir: N O halde olasılık Testler ve olayın meydana gelme olasılığı test olayı testler gelecek
![]() formülle hesaplanan zamanlar:
formülle hesaplanan zamanlar: ![]() (1)
(1)
veya Formül (1) denir.
Bernoulli'nin formülü Xİzin vermek Testler ve olayın meydana gelme olasılığı– olayın meydana gelme sayısına eşit bir rastgele değişken N V
olasılıklarla değer alan testler: Rastgele bir değişkenin ortaya çıkan dağılım yasasına denir.
| X | testler | N | ||||
| binom dağılım kanunu |
P, Beklenti dağılım Ve standart sapma
, , .
ve düzgün dağılıma sahip bir rastgele değişken için. Binom yasasına göre dağıtılan rastgele değişkenler aşağıdaki formüllerle belirlenir: X Hedefe üç atış yapılır ve her atışta isabet olasılığı 0,8'dir. Rastgele bir değişken göz önüne alındığında
– hedefteki isabet sayısı. Dağıtım yasasını, matematiksel beklentiyi, dağılımını ve standart sapmasını bulun., p=0,8, q=0,2, ![]() , ,
, , ![]() .
.
![]() n=3
n=3
- 0 isabet olasılığı;
Tek vuruş şansı;
![]() İki vuruş şansı;
İki vuruş şansı;
- üç vuruş olasılığı.
| X | ||||
| binom dağılım kanunu | 0,008 | 0,096 | 0,384 | 0,512 |
Dağıtım yasasını elde ederiz:
Görevler
1. Bir madeni para 7 kez atılıyor. Arması 4 kez yukarı bakacak şekilde yere inme olasılığını bulun.
3. Silahtan ateş edildiğinde hedefi vurma olasılığı p=0,6. 10 atış yapıldığında toplam isabet sayısının matematiksel beklentisini bulun.
4. 20 bilet alınırsa kazanılacak piyango bileti sayısının matematiksel beklentisini bulun ve bir bilette kazanma olasılığı 0,3'tür.
Bu durumda (5.7)'ye göre dağıtım fonksiyonu şu şekli alacaktır:
burada: m – matematiksel beklenti, s – standart sapma.
Normal dağılıma Alman matematikçi Gauss'tan sonra Gaussian da denir. Bir rastgele değişkenin m parametreleriyle normal dağılıma sahip olması şu şekilde gösterilir: N (m,s), burada: m =a =M ;
Formüllerde sıklıkla matematiksel beklenti şu şekilde gösterilir: A . Bir rastgele değişken N(0,1) yasasına göre dağıtılıyorsa buna normalleştirilmiş veya standartlaştırılmış normal değişken denir. Bunun için dağıtım fonksiyonu şu şekildedir:
|
|
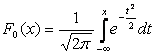 .
.Normal eğri veya Gauss eğrisi olarak adlandırılan normal dağılımın yoğunluk grafiği Şekil 5.4'te gösterilmektedir.

Pirinç. 5.4. Normal dağılım yoğunluğu
Bir rastgele değişkenin sayısal özelliklerinin yoğunluğuna göre belirlenmesi bir örnek kullanılarak ele alınmıştır.
Örnek 6.
Sürekli bir rastgele değişken dağıtım yoğunluğuyla belirlenir: ![]() .
.
Dağıtımın türünü belirleyin, M(X) matematiksel beklentisini ve D(X) varyansını bulun.
Verilen dağılım yoğunluğunu (5.16) ile karşılaştırırsak, m = 4 ile normal dağılım yasasının verildiği sonucuna varabiliriz. Dolayısıyla matematiksel beklenti M(X)=4, varyans D(X)=9.
Standart sapma s=3.
Şu forma sahip Laplace işlevi:
|
|
 ,
,normal dağılım fonksiyonu (5.17) ile ilgilidir, ilişki:
F 0 (x) = Ф(x) + 0,5.
Laplace fonksiyonu tuhaftır.
F(-x)=-Ф(x).
Laplace fonksiyonunun değerleri Ф(х) tablo haline getirilmiş ve x değerine göre tablodan alınmıştır (bkz. Ek 1).
Sürekli bir rastgele değişkenin normal dağılımı olasılık teorisinde ve gerçekliğin tanımlanmasında önemli bir rol oynar; rastgele doğal olaylarda çok yaygındır. Uygulamada, pek çok rastgele terimin toplanması sonucu oluşan rastgele değişkenlerle sıklıkla karşılaşırız. Özellikle ölçüm hatalarının analizi, bunların çeşitli hata türlerinin toplamı olduğunu gösterir. Uygulama, ölçüm hatalarının olasılık dağılımının normal yasaya yakın olduğunu göstermektedir.
Laplace fonksiyonunu kullanarak, belirli bir aralığa düşme olasılığını ve normal bir rastgele değişkenin belirli bir sapmasını hesaplama problemini çözebilirsiniz.
Bu konu uzun süredir ayrıntılı olarak çalışılmaktadır ve en yaygın kullanılan yöntem, George Box, Mervyn Muller ve George Marsaglia tarafından 1958'de önerilen kutupsal koordinat yöntemidir. Bu yöntem, matematiksel beklentisi 0 ve varyansı 1 olan bir çift bağımsız normal dağılımlı rastgele değişken elde etmenizi sağlar:
Z 0 ve Z 1 istenen değerler olduğunda, s = u 2 + v 2 ve u ve v, (-1, 1) aralığında düzgün şekilde dağıtılan ve 0 koşulu sağlanacak şekilde seçilen rastgele değişkenlerdir.< s < 1.
Pek çok kişi bu formülleri hiç düşünmeden kullanıyor ve çoğu hazır uygulamaları kullandığı için varlığından bile şüphelenmiyor. Ancak şu soruyu soranlar da var: “Bu formül nereden çıktı? Peki neden aynı anda birkaç miktar alıyorsunuz?” Daha sonra bu sorulara net bir cevap vermeye çalışacağım.
Başlangıç olarak olasılık yoğunluğunun, rastgele değişkenin dağılım fonksiyonunun ve ters fonksiyonun ne olduğunu hatırlatayım. Dağılımı f(x) yoğunluk fonksiyonu ile belirlenen ve aşağıdaki forma sahip olan belirli bir rastgele değişkenin olduğunu varsayalım:

Bu, belirli bir rastgele değişkenin değerinin (A, B) aralığında olma olasılığının taralı alanın alanına eşit olduğu anlamına gelir. Ve sonuç olarak, tüm gölgeli alanın alanı bire eşit olmalıdır, çünkü her durumda rastgele değişkenin değeri f fonksiyonunun tanım alanına girecektir.
Bir rastgele değişkenin dağılım fonksiyonu yoğunluk fonksiyonunun integralidir. Ve bu durumda yaklaşık görünümü şöyle olacaktır:

Buradaki anlam, rasgele değişkenin değerinin B olasılığı ile A'dan küçük olacağıdır. Sonuç olarak fonksiyon asla azalmaz ve değerleri aralıkta yer alır.
Ters fonksiyon, orijinal fonksiyonun değeri kendisine iletildiğinde orijinal fonksiyona bir argüman döndüren bir fonksiyondur. Örneğin, x 2 fonksiyonu için bunun tersi kök çıkarma fonksiyonudur, sin(x) için ise arcsin(x), vb.'dir.
Sahte rasgele sayı üreteçlerinin çoğu çıktı olarak yalnızca tekdüze bir dağılım ürettiğinden, genellikle onu başka bir dağılıma dönüştürme ihtiyacı vardır. Bu durumda normal Gaussian'a göre:

Düzgün bir dağılımı diğerine dönüştürmeye yönelik tüm yöntemlerin temeli, ters dönüşüm yöntemidir. Aşağıdaki gibi çalışır. Gerekli dağılımın fonksiyonuna ters olan bir fonksiyon bulunur ve (0, 1) aralığında düzgün bir şekilde dağıtılan bir rastgele değişken argüman olarak ona iletilir. Çıktıda gerekli dağılıma sahip bir değer elde ederiz. Netlik sağlamak için aşağıdaki resmi sunuyorum.

Böylece, yeni dağılıma göre tekdüze bir parça sanki bulaşmış gibi, ters bir fonksiyonla başka bir eksene yansıtılıyor. Ancak sorun şu ki, Gauss dağılımının yoğunluğunun integralini hesaplamak kolay olmadığından yukarıdaki bilim adamları hile yapmak zorunda kaldı.
K bağımsız normal rastgele değişkenin karelerinin toplamının dağılımı olan bir ki-kare dağılımı (Pearson dağılımı) vardır. Ve k = 2 durumunda bu dağılım üsteldir.

Bu, dikdörtgen koordinat sistemindeki bir noktanın normal olarak dağıtılmış rastgele X ve Y koordinatlarına sahip olması durumunda, bu koordinatları kutup sistemine (r, θ) dönüştürdükten sonra, yarıçapın karesinin (başlangıç noktasından noktaya olan mesafe) olduğu anlamına gelir. Yarıçapın karesi koordinatların karelerinin toplamı olduğundan (Pisagor yasasına göre) üstel yasaya göre dağıtılacaktır. Düzlemdeki bu tür noktaların dağılım yoğunluğu şöyle görünecektir:


Tüm yönlerde eşit olduğundan, θ açısı 0 ila 2π aralığında düzgün bir dağılıma sahip olacaktır. Bunun tersi de doğrudur: Kutupsal koordinat sisteminde iki bağımsız rastgele değişken (bir açı düzgün olarak dağıtılmış ve bir yarıçap üstel olarak dağıtılmış) kullanarak bir nokta tanımlarsanız, o zaman bu noktanın dikdörtgen koordinatları bağımsız normal rastgele değişkenler olacaktır. Ve aynı ters dönüşüm yöntemini kullanarak tekdüze bir dağılımdan üstel bir dağılım elde etmek çok daha kolaydır. Polar Box-Muller yönteminin özü budur.
Şimdi formülleri türetelim.
![]() (1)
(1)
r ve θ'yı elde etmek için, (0, 1) aralığında eşit olarak dağılmış iki rastgele değişken üretmemiz gerekir (bunlara u ve v diyelim), bunlardan birinin dağılımının (diyelim v) üstel değişkene dönüştürülmesi gerekir: yarıçapı elde edin. Üstel dağılım fonksiyonu şuna benzer:
Ters fonksiyonu:
![]()
Düzgün dağılım simetrik olduğundan dönüşüm, fonksiyonla benzer şekilde çalışacaktır.
![]()
Ki-kare dağılım formülünden λ = 0,5 sonucu çıkar. Bu fonksiyonda λ, v'yi yerine koyun ve yarıçapın karesini ve ardından yarıçapın kendisini alın:

Birim parçasını 2π'ye kadar uzatarak açıyı elde ederiz:
Şimdi r ve θ'yı formül (1)'de yerine koyarız ve şunu elde ederiz:
 (2)
(2)
Bu formüller zaten kullanıma hazır. X ve Y bağımsız olacak ve varyansı 1 ve matematiksel beklentisi 0 olacak şekilde normal dağılacaktır. Diğer özelliklere sahip bir dağılım elde etmek için fonksiyonun sonucunu standart sapma ile çarpmak ve matematiksel beklentiyi eklemek yeterlidir.
Ancak açıyı doğrudan değil, daire içindeki rastgele bir noktanın dikdörtgen koordinatları üzerinden dolaylı olarak belirleyerek trigonometrik fonksiyonlardan kurtulmak mümkündür. Daha sonra bu koordinatlar aracılığıyla yarıçap vektörünün uzunluğunu hesaplamak ve ardından sırasıyla x ve y'yi buna bölerek kosinüs ve sinüsü bulmak mümkün olacaktır. Nasıl ve neden çalışıyor?
Birim yarıçaplı bir çemberde düzgün dağılmış noktalardan rastgele bir nokta seçelim ve bu noktanın yarıçap vektörünün uzunluğunun karesini s harfiyle gösterelim:

Seçim, (-1, 1) aralığında eşit olarak dağıtılmış rastgele dikdörtgen x ve y koordinatları belirtilerek ve daireye ait olmayan noktaların yanı sıra yarıçap vektörünün açısının bulunduğu merkezi nokta atılarak yapılır. tanımlanmamıştır. Yani koşul 0'ın karşılanması gerekir< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Formülleri yazının başındaki gibi alıyoruz. Bu yöntemin dezavantajı daireye dahil olmayan noktaların atılmasıdır. Yani, oluşturulan rastgele değişkenlerin yalnızca %78,5'i kullanılıyor. Eski bilgisayarlarda trigonometri fonksiyonlarının olmaması hâlâ büyük bir avantajdı. Şimdi, bir işlemci komutu hem sinüs hem de kosinüsü anında hesapladığında, bu yöntemlerin hâlâ rekabet edebileceğini düşünüyorum.
Kişisel olarak hala iki sorum var:
- S'nin değeri neden eşit olarak dağıtılıyor?
- İki normal rastgele değişkenin karelerinin toplamı neden üstel olarak dağıtılıyor?

Normal bir rastgele değişken için benzer bir dönüşüm yapılırsa, karesinin yoğunluk fonksiyonu bir hiperbole benzer olacaktır. Ve normal rastgele değişkenlerin iki karesinin eklenmesi, çift entegrasyonla ilişkili çok daha karmaşık bir süreçtir. Ve sonucun üstel bir dağılım olacağı gerçeğini şahsen sadece pratik bir yöntem kullanarak kontrol etmem veya bir aksiyom olarak kabul etmem gerekiyor. İlgilenenler için konuya daha yakından bakmanızı, şu kitaplardan bilgi edinmenizi öneririm:
- Ventzel E.S. Olasılık teorisi
- Knut D.E. Programlama Sanatı, Cilt 2
Sonuç olarak, burada normal olarak dağıtılmış bir rastgele sayı üretecinin JavaScript'te uygulanmasına bir örnek verilmiştir:
Function Gauss() ( var hazır = false; var saniye = 0,0; this.next = function(mean, dev) ( ortalama = ortalama == tanımsız ? 0,0: ortalama; dev = dev == tanımsız ? 1,0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + ortalama; ) else ( var u, v, s; do ( u = 2,0 * Math.random() - 1,0; v = 2,0 * Math. rastgele() - 1.0; s = u * u + v * v; while (s > 1.0 || s == 0.0); this.second = r * u; return r * v * dev + ortalama ) ) g = yeni Gauss(); // bir nesne yarat a = g.next(); // bir değer çifti oluşturup ilkini elde ediyoruz b = g.next(); // ikinciyi al c = g.next(); // tekrar bir değer çifti oluşturup ilkini elde ediyoruz
Ortalama (matematiksel beklenti) ve dev (standart sapma) parametreleri isteğe bağlıdır. Logaritmanın doğal olduğuna dikkatinizi çekerim.
