Jednolity rozkład losowy. Konwersja zmiennej losowej o rozkładzie jednostajnym na zmienną o rozkładzie normalnym
Jako przykład ciągłej zmiennej losowej rozważ zmienną losową X równomiernie rozłożoną w przedziale (a; b). Mówimy, że zmienna losowa X równomiernie na przedziale (a; b), jeśli jego gęstość rozkładu nie jest stała na tym przedziale:
Z warunku normalizacji wyznaczamy wartość stałej c . Pole pod krzywą gęstości rozkładu powinno być równe jeden, ale w naszym przypadku jest to pole prostokąta o podstawie (b - α) i wysokości c (rys. 1). 
Ryż. 1 Jednolita gęstość dystrybucji
Stąd znajdujemy wartość stałej c: ![]()
Czyli gęstość zmiennej losowej o rozkładzie jednostajnym jest równa 
Znajdźmy teraz funkcję rozkładu według wzoru:
1) dla ![]()
2) dla
3) dla 0+1+0=1.
W ten sposób, 
Funkcja rozkładu jest ciągła i nie maleje (rys. 2). 
Ryż. 2 Rozkład funkcji zmiennej losowej o rozkładzie jednostajnym
Znajdźmy matematyczne oczekiwanie zmiennej losowej o rozkładzie jednostajnym według wzoru:
Jednolita wariancja dystrybucji jest obliczany według wzoru i jest równy
Przykład 1. Wartość podziałki skali przyrządu pomiarowego wynosi 0,2 . Odczyty przyrządów są zaokrąglane do najbliższej pełnej działki. Znajdź prawdopodobieństwo popełnienia błędu podczas odczytu: a) mniejsze niż 0,04; b) duży 0,02
Rozwiązanie. Błąd zaokrąglenia jest zmienną losową równomiernie rozłożoną w przedziale między sąsiednimi działami całkowitymi. Rozważ przedział (0; 0,2) jako taki podział (ryc. a). Zaokrąglanie można przeprowadzić zarówno w kierunku lewej granicy – 0, jak i w prawo – 0,2, co oznacza, że błąd mniejszy lub równy 0,04 można popełnić dwukrotnie, co należy uwzględnić przy obliczaniu prawdopodobieństwa: 

P = 0,2 + 0,2 = 0,4
W drugim przypadku wartość błędu może również przekroczyć 0,02 na obu granicach podziału, to znaczy może być większa niż 0,02 lub mniejsza niż 0,18. 
Wtedy prawdopodobieństwo takiego błędu:
Przykład #2. Założono, że stabilność sytuacji gospodarczej w kraju (brak wojen, klęsk żywiołowych itp.) na przestrzeni ostatnich 50 lat można oceniać na podstawie charakteru rozmieszczenia ludności według wieku: w sytuacji spokojnej, powinno być mundur. W wyniku badania uzyskano następujące dane dla jednego z krajów.
Czy jest jakikolwiek powód, by sądzić, że w kraju panowała niestabilna sytuacja?Decyzję przeprowadzamy za pomocą kalkulatora Testowanie hipotez. Tabela do obliczania wskaźników.
| Grupy | Środek przedziału, x i | Ilość, fi | x ja * f ja | Częstotliwość skumulowana, S | |x - x cf |*f | (x - x sr) 2 *f | Częstotliwość, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Średnia ważona
Wskaźniki zmienności.
Bezwzględne stopy zmienności.
Zakres zmienności to różnica między maksymalną a minimalną wartością atrybutu serii podstawowej.
R = X max - X min
R=70 - 0=70
Dyspersja- charakteryzuje miarę rozrzutu wokół jej wartości średniej (miara rozrzutu, czyli odchylenia od średniej).
Odchylenie standardowe.
Każda wartość serii różni się od średniej wartości 43 o nie więcej niż 23,92
Testowanie hipotez dotyczących rodzaju dystrybucji.
4. Testowanie hipotezy o równomierny rozkład ogólna populacja.
W celu sprawdzenia hipotezy o równomiernym rozkładzie X, tj. zgodnie z prawem: f(x) = 1/(b-a) w przedziale (a,b)
niezbędny:
1. Oszacuj parametry a i b - końce przedziału, w którym zaobserwowano możliwe wartości X, zgodnie ze wzorami (znak * oznacza oszacowania parametrów):
2. Znajdź gęstość prawdopodobieństwa oszacowanego rozkładu f(x) = 1/(b * - a *)
3. Znajdź teoretyczne częstotliwości:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Porównać częstości empiryczne i teoretyczne testem Pearsona, przyjmując liczbę stopni swobody k = s-3, gdzie s jest liczbą początkowych interwałów próbkowania; jeśli jednak dokonano kombinacji małych częstotliwości, a więc i samych interwałów, to s jest liczbą interwałów pozostałych po kombinacji.
Rozwiązanie:
1. Znajdź oszacowania parametrów a * i b * rozkładu równomiernego, korzystając ze wzorów:
2. Znajdź gęstość założonego rozkładu jednostajnego:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Znajdź teoretyczne częstotliwości:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Pozostałe n będą równe:
n s = n*f(x)(x i - x i-1)
| i | n ja | n*i | n ja - n * ja | (n ja - n* ja) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Całkowity | 1 | 0.0532 |
Dlatego obszar krytyczny dla tej statystyki jest zawsze prawostronny: jeśli jego gęstość prawdopodobieństwa jest stała w tym segmencie, a poza nim wynosi 0 (tj. zmienna losowa X skoncentrowany na segmencie [ a, b], na którym ma stałą gęstość). Zgodnie z tą definicją gęstość równomiernie rozłożona na segmencie [ a, b] zmienna losowa X wygląda jak:
gdzie Z jest jakaś liczba. Jednak łatwo go znaleźć, korzystając z właściwości gęstości prawdopodobieństwa dla r.v. skoncentrowanego na odcinku [ a,
b]:
 . Stąd wynika, że
. Stąd wynika, że  , gdzie
, gdzie  . Dlatego gęstość równomiernie rozłożona na odcinku [ a,
b] zmienna losowa X wygląda jak:
. Dlatego gęstość równomiernie rozłożona na odcinku [ a,
b] zmienna losowa X wygląda jak:
 .
.
Aby ocenić jednolitość dystrybucji n.s.v. X możliwe z następujących rozważań. Ciągła zmienna losowa ma rozkład równomierny na przedziale [ a, b] jeśli przyjmuje wartości tylko z tego segmentu, a dowolna liczba z tego segmentu nie ma przewagi nad innymi liczbami z tego segmentu w sensie bycia wartością tej zmiennej losowej.
Do zmiennych losowych o rozkładzie równomiernym należą takie zmienne jak czas oczekiwania transportu na postoju (przy stałym interwale ruchu, czas oczekiwania jest równomiernie rozłożony na tym interwale), błąd zaokrąglenia liczby do liczby całkowitej (rozłożony równomiernie na [−0,5 , 0.5 ]) i inni.
Rodzaj funkcji dystrybucji F(x)
a,
b] zmienna losowa X jest wyszukiwany według znanej gęstości prawdopodobieństwa f(x)
używając formuły ich połączenia  . W wyniku odpowiednich obliczeń otrzymujemy następujący wzór na dystrybuantę F(x)
segment równomiernie rozłożony [ a,
b] zmienna losowa X
:
. W wyniku odpowiednich obliczeń otrzymujemy następujący wzór na dystrybuantę F(x)
segment równomiernie rozłożony [ a,
b] zmienna losowa X
:
 .
.
Na rysunkach przedstawiono wykresy gęstości prawdopodobieństwa f(x) i dystrybucja funkcji f(x) segment równomiernie rozłożony [ a, b] zmienna losowa X :


Oczekiwanie matematyczne, wariancja, odchylenie standardowe, moda i mediana segmentu o rozkładzie jednostajnym [ a, b] zmienna losowa X obliczona z gęstości prawdopodobieństwa f(x) w zwykły sposób (i po prostu ze względu na prosty wygląd) f(x) ). Rezultatem są następujące formuły:
ale moda d(X) to dowolna liczba przedziału [ a, b].
Znajdźmy prawdopodobieństwo trafienia w segment równomiernie rozłożony [ a,
b] zmienna losowa X w przedziale  , całkowicie leżące w środku [ a,
b]. Biorąc pod uwagę znaną postać funkcji rozkładu, otrzymujemy:
, całkowicie leżące w środku [ a,
b]. Biorąc pod uwagę znaną postać funkcji rozkładu, otrzymujemy:
Zatem prawdopodobieństwo trafienia w segment równomiernie rozłożony [ a,
b] zmienna losowa X w przedziale  , całkowicie leżące w środku [ a,
b], nie zależy od położenia tego przedziału, ale zależy tylko od jego długości i jest wprost proporcjonalna do tej długości.
, całkowicie leżące w środku [ a,
b], nie zależy od położenia tego przedziału, ale zależy tylko od jego długości i jest wprost proporcjonalna do tej długości.
Przykład. Odstęp autobusu wynosi 10 minut. Jakie jest prawdopodobieństwo, że pasażer przyjeżdżający na przystanek będzie czekał na autobus mniej niż 3 minuty? Jaki jest średni czas oczekiwania na autobus?
Normalna dystrybucja
Rozkład ten jest najczęściej spotykany w praktyce i odgrywa wyjątkową rolę w teorii prawdopodobieństwa i statystyce matematycznej oraz ich zastosowaniach, ponieważ tak wiele zmiennych losowych w naukach przyrodniczych, ekonomii, psychologii, socjologii, naukach wojskowych itd. ma taki rozkład. Ta dystrybucja jest prawem granicznym, do którego (w pewnych warunkach naturalnych) podchodzi wiele innych praw dystrybucji. Za pomocą prawa rozkładu normalnego opisywane są również zjawiska podlegające działaniu wielu niezależnych czynników losowych dowolnej natury oraz dowolne prawo ich rozkładu. Przejdźmy do definicji.
Ciągła zmienna losowa nazywana jest rozłożonym normalne prawo (lub prawo Gaussa), jeśli jego gęstość prawdopodobieństwa ma postać:
 ,
,
gdzie są liczby? a oraz σ (σ>0 ) to parametry tego rozkładu.
Jak już wspomniano, prawo Gaussa rozkładu zmiennych losowych ma wiele zastosowań. Zgodnie z tym prawem rozłożone są błędy pomiarowe przyrządów, odchylenie od środka celu podczas strzelania, wymiary produkowanych części, waga i wzrost ludzi, roczne opady, liczba noworodków i wiele innych.
Powyższy wzór na gęstość prawdopodobieństwa zmiennej losowej o rozkładzie normalnym zawiera, jak już powiedziano, dwa parametry a oraz σ , a zatem definiuje rodzinę funkcji, które różnią się w zależności od wartości tych parametrów. Jeśli zastosujemy zwykłe metody analizy matematycznej badania funkcji i wykreślenia gęstości prawdopodobieństwa rozkładu normalnego, możemy wyciągnąć następujące wnioski.

są jego punktami przegięcia.
Na podstawie otrzymanych informacji budujemy wykres gęstości prawdopodobieństwa f(x) rozkład normalny (nazywa się to krzywą Gaussa - rysunek).

Dowiedzmy się, jak wpływa zmiana parametrów a oraz σ na kształcie krzywej Gaussa. Jest oczywiste (widać to ze wzoru na gęstość rozkładu normalnego), że zmiana parametru a nie zmienia kształtu krzywej, a jedynie prowadzi do jej przesunięcia w prawo lub w lewo wzdłuż osi X. Zależność σ trudniejsze. Z powyższego badania widać, jak wartość maksimum i współrzędne punktów przegięcia zależą od parametru σ . Ponadto należy wziąć pod uwagę, że dla dowolnych parametrów a oraz σ pole pod krzywą Gaussa pozostaje równe 1 (jest to ogólna właściwość gęstości prawdopodobieństwa). Z tego co zostało powiedziane wynika, że wraz ze wzrostem parametru σ krzywa staje się bardziej płaska i rozciąga się wzdłuż osi X. Rysunek przedstawia krzywe Gaussa dla różnych wartości parametru σ (σ 1 < σ< σ 2 ) i taką samą wartość parametru a.

Poznaj probabilistyczne znaczenie parametrów a oraz σ
normalna dystrybucja. Już od symetrii krzywej Gaussa w odniesieniu do linii pionowej przechodzącej przez liczbę a na osi X jasne jest, że wartość średnia (tj. oczekiwanie matematyczne) M(X)) zmiennej losowej o rozkładzie normalnym jest równe a. Z tych samych powodów moda i mediana również muszą być równe liczbie a. Potwierdzają to dokładne obliczenia według odpowiednich wzorów. Jeśli wypiszemy powyższe wyrażenie dla f(x)
podstawnik we wzorze na wariancję  , to po (dość trudnym) obliczeniu całki otrzymujemy w odpowiedzi liczbę σ
2
. Zatem dla zmiennej losowej X rozłożone zgodnie z prawem normalnym, otrzymano następujące główne charakterystyki liczbowe:
, to po (dość trudnym) obliczeniu całki otrzymujemy w odpowiedzi liczbę σ
2
. Zatem dla zmiennej losowej X rozłożone zgodnie z prawem normalnym, otrzymano następujące główne charakterystyki liczbowe:
Zatem probabilistyczne znaczenie parametrów rozkładu normalnego a oraz σ następny. Jeśli r.v. Xa oraz σ a σ.
Znajdźmy teraz funkcję dystrybucji F(x)
dla zmiennej losowej X, rozłożony zgodnie z prawem normalnym, używając powyższego wyrażenia dla gęstości prawdopodobieństwa f(x)
i formuła  . Podczas zastępowania f(x)
otrzymujemy całkę „nieuznaną”. Wszystko, co można zrobić, aby uprościć wyrażenie for F(x),
jest to reprezentacja tej funkcji w postaci:
. Podczas zastępowania f(x)
otrzymujemy całkę „nieuznaną”. Wszystko, co można zrobić, aby uprościć wyrażenie for F(x),
jest to reprezentacja tej funkcji w postaci:
 ,
,
gdzie F(x)- tak zwany Funkcja Laplace'a, który wygląda jak
 .
.
Całka, za pomocą której wyrażana jest funkcja Laplace'a, również nie jest brana (ale dla każdego X ta całka może być obliczona w przybliżeniu z dowolną określoną dokładnością). Jednak nie jest to wymagane, ponieważ na końcu każdego podręcznika z teorii prawdopodobieństwa znajduje się tabela do określania wartości funkcji F(x) przy danej wartości X. W dalszej części będziemy potrzebować własności osobliwości funkcji Laplace'a: F(−x)=−F(x) dla wszystkich liczb X.
Znajdźmy teraz prawdopodobieństwo, że r.v. X przyjmie wartość z podanego przedziału liczbowego (α, β) . Z ogólnych własności funkcji dystrybucji Р(α< X< β)= F(β) − F(α) . Zastępowanie α oraz β do powyższego wyrażenia dla F(x) , dostajemy
 .
.
Jak wspomniano powyżej, jeśli r.v. X rozkład normalny z parametrami a oraz σ , to jego wartość średnia jest równa a, a odchylenie standardowe jest równe σ. Dlatego przeciętny odchylenie wartości tego r.v. podczas testowania z numeru a równa się σ. Ale to jest średnie odchylenie. Dlatego możliwe są również większe odchylenia. Dowiadujemy się, jak możliwe są te lub inne odchylenia od wartości średniej. Znajdźmy prawdopodobieństwo, że wartość zmiennej losowej rozłożonej zgodnie z prawem normalnym X odbiegać od jego średniej M(X)=a mniej niż jakaś liczba δ, tj. R(| X− a|<δ ) : . W ten sposób,
 .
.
Podstawiając do tej równości δ=3σ otrzymujemy prawdopodobieństwo, że wartość r.v. X(w jednym badaniu) odbiega od średniej mniej niż trzykrotnie σ (ze średnim odchyleniem, jak pamiętamy, równym σ ): (oznaczający F(3) zaczerpnięte z tabeli wartości funkcji Laplace’a). Jest prawie 1 ! Wtedy prawdopodobieństwo odwrotnego zdarzenia (że wartość odbiega co najmniej o 3σ) jest równe 1 −0.997=0.003 , który jest bardzo blisko 0 . Dlatego to wydarzenie jest „prawie niemożliwe” − zdarza się bardzo rzadko (średnio 3 czas się skończył 1000 ). To rozumowanie jest uzasadnieniem dla dobrze znanej „reguły trzech sigma”.
Reguła trzech sigma. Zmienna losowa o rozkładzie normalnym w jednym teście praktycznie nie odbiega od średniej dalej niż 3σ.
Jeszcze raz podkreślamy, że mówimy o jednym teście. Jeśli jest wiele prób zmiennej losowej, to całkiem możliwe, że niektóre jej wartości odsuną się dalej od średniej niż 3σ. Potwierdza to następujące
Przykład. Jakie jest prawdopodobieństwo, że po 100 próbach zmiennej losowej o rozkładzie normalnym X co najmniej jedna z jego wartości będzie odbiegać od średniej o ponad trzykrotność odchylenia standardowego? A co z 1000 prób?
Rozwiązanie. Niech wydarzenie ALE oznacza, że podczas testowania zmiennej losowej X jego wartość odbiegała od średniej o więcej niż 3σ. Jak się właśnie dowiedziałem, prawdopodobieństwo tego zdarzenia p=P(A)=0,003. Przeprowadzono 100 takich testów. Musimy znaleźć prawdopodobieństwo, że zdarzenie ALE stało się przynajmniej razy, tj. pochodzi z 1 zanim 100 raz. Jest to typowy problem schematu Bernoulliego z parametrami n=100 (liczba niezależnych prób), p=0,003(prawdopodobieństwo zdarzenia) ALE w jednym teście) q=1− p=0.997 . Chciałem znaleźć R 100 (1≤ k≤100) . W tym przypadku oczywiście łatwiej jest najpierw znaleźć prawdopodobieństwo odwrotnego zdarzenia R 100 (0) − prawdopodobieństwo, że zdarzenie ALE nigdy się nie zdarzyło (tj. zdarzyło się 0 razy). Biorąc pod uwagę związek między prawdopodobieństwami samego zdarzenia a jego przeciwieństwem, otrzymujemy:
Nie tak mało. Może się tak zdarzyć (występuje średnio w co czwartej takiej serii testów). Na 1000 testów według tego samego schematu można stwierdzić, że prawdopodobieństwo wystąpienia co najmniej jednego odchylenia jest większe niż 3σ, równa się: . Można więc bezpiecznie poczekać na przynajmniej jedno takie odchylenie.
Przykład. Wzrost mężczyzn w określonej grupie wiekowej ma rozkład normalny z oczekiwaniem matematycznym a i odchylenie standardowe σ . Jaka część kostiumów k-ty przyrost należy uwzględnić w produkcji całkowitej dla danej grupy wiekowej, jeżeli: k-ty wzrost określają następujące limity:
1 wzrost : 158 − 164cm 2 wzrost : 164 - 170cm 3 wzrost : 170 - 176cm 4 wzrost : 176 - 182 cm
Rozwiązanie. Rozwiążmy problem z następującymi wartościami parametrów: a=178,σ=6,k=3
. Niech r.v. X
−
wzrost losowo wybranego mężczyzny (rozkłada się według stanu normalnie przy podanych parametrach). Znajdź prawdopodobieństwo, że losowo wybrany mężczyzna będzie potrzebować 3
wzrost. Korzystanie z osobliwości funkcji Laplace'a F(x) oraz tabelę jego wartości: P(170
Rozkład prawdopodobieństwa ciągłej zmiennej losowej X, który pobiera wszystkie wartości z przedziału , jest nazywany mundur, jeśli jego gęstość prawdopodobieństwa na tym odcinku jest stała, a poza nią równa się zeru. Zatem gęstość prawdopodobieństwa ciągłej zmiennej losowej X, rozłożone równomiernie na segmencie , wygląda jak:

Zdefiniujmy wartość oczekiwana, dyspersja oraz dla zmiennej losowej o rozkładzie jednostajnym.
, ![]() ,
, ![]() .
.
Przykład. Wszystkie wartości zmiennej losowej o rozkładzie jednostajnym leżą na segmencie . Znajdź prawdopodobieństwo wpadnięcia zmiennej losowej do przedziału (3;5) .
a=2, b=8,  .
.
Rozkład dwumianowy
Niech się wyprodukuje n testy i prawdopodobieństwo wystąpienia zdarzenia A w każdym teście jest p i nie zależy od wyników innych badań (badań niezależnych). Ponieważ prawdopodobieństwo wystąpienia zdarzenia A w jednym teście jest p, to prawdopodobieństwo jego niewystąpienia jest równe q=1-p.
Niech wydarzenie A przyszedł n próby m raz. To złożone wydarzenie można zapisać jako produkt:
![]() .
.
Wtedy prawdopodobieństwo, że n zdarzenie testowe A nadejdzie m razy , oblicza się według wzoru:
![]() lub
lub ![]() (1)
(1)
Formuła (1) nazywa się Formuła Bernoulliego.
Wynajmować X jest zmienną losową równą liczbie wystąpień zdarzenia A w n testy, które przyjmują wartości z prawdopodobieństwami:
Otrzymane prawo rozkładu zmiennej losowej nosi nazwę prawo rozkładu dwumianowego.
| X | m | n | ||||
| P |
Wartość oczekiwana, dyspersja oraz odchylenie standardowe zmienne losowe o rozkładzie zgodnie z prawem dwumianowym określają wzory:
, , .
Przykład. Do tarczy oddano trzy strzały, a prawdopodobieństwo trafienia każdego strzału wynosi 0,8. Rozważamy zmienną losową X- liczba trafień w cel. Znajdź jego prawo rozkładu, oczekiwanie matematyczne, wariancję i odchylenie standardowe.
p=0,8, q=0,2, n=3, ![]() , ,
, , ![]() .
.
![]() - prawdopodobieństwo 0 trafień;
- prawdopodobieństwo 0 trafień;
Prawdopodobieństwo jednego trafienia;
Prawdopodobieństwo dwóch trafień;
![]() to prawdopodobieństwo trzech trafień.
to prawdopodobieństwo trzech trafień.
Otrzymujemy prawo dystrybucji:
| X | ||||
| P | 0,008 | 0,096 | 0,384 | 0,512 |
Zadania
1. Moneta jest rzucana 7 razy. Znajdź prawdopodobieństwo, że spadnie do góry nogami 4 razy.
2. Moneta jest rzucana 8 razy. Znajdź prawdopodobieństwo, że herb pojawi się nie więcej niż trzy razy.
3. Prawdopodobieństwo trafienia w cel podczas strzelania z działa p=0,6. Znajdź matematyczne oczekiwanie całkowitej liczby trafień po oddaniu 10 strzałów.
4. Znajdź matematyczne oczekiwanie liczby losów na loterię, które wygrają, jeśli kupionych zostanie 20 losów, a prawdopodobieństwo wygranej za jeden los wynosi 0,3.
Funkcja rozkładu w tym przypadku, zgodnie z (5.7), przyjmie postać:
gdzie: m to oczekiwanie matematyczne, s to odchylenie standardowe.
Rozkład normalny jest również nazywany Gaussem na cześć niemieckiego matematyka Gaussa. Fakt, że zmienna losowa ma rozkład normalny o parametrach: m,, oznaczamy następująco: N (m, s), gdzie: m =a =M ;
Dość często we wzorach oczekiwanie matematyczne oznaczane jest przez a . Jeżeli zmienna losowa ma rozkład zgodnie z prawem N(0,1), to nazywa się ją wartością normalną znormalizowaną lub standaryzowaną. Funkcja rozkładu ma dla niego postać:
|
|
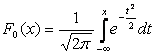 .
.Wykres gęstości rozkładu normalnego, który nazywa się krzywą normalną lub krzywą Gaussa, pokazano na ryc. 5.4.

Ryż. 5.4. Gęstość rozkładu normalnego
Na przykładzie rozpatrzono wyznaczenie liczbowej charakterystyki zmiennej losowej na podstawie jej gęstości.
Przykład 6.
Ciągłą zmienną losową określa gęstość rozkładu: ![]() .
.
Określ rodzaj rozkładu, znajdź oczekiwanie matematyczne M(X) i wariancję D(X).
Porównując podaną gęstość rozkładu z (5.16), możemy stwierdzić, że dane jest prawo rozkładu normalnego z m =4. Zatem oczekiwanie matematyczne M(X)=4, wariancja D(X)=9.
Odchylenie standardowe s=3.
Funkcja Laplace'a, która ma postać:
|
|
 ,
,jest powiązany z rozkładem normalnym (5.17), zależnością:
F 0 (x) \u003d F (x) + 0,5.
Funkcja Laplace'a jest nieparzysta.
Ф(-x)=-Ф(x).
Wartości funkcji Laplace'a Ф(х) są zestawiane i pobierane z tabeli zgodnie z wartością x (patrz Załącznik 1).
Rozkład normalny ciągłej zmiennej losowej odgrywa ważną rolę w teorii prawdopodobieństwa iw opisie rzeczywistości, jest bardzo rozpowszechniony w przypadkowych zjawiskach naturalnych. W praktyce bardzo często zdarzają się zmienne losowe, które powstają właśnie w wyniku sumowania wielu losowych terminów. W szczególności analiza błędów pomiarowych pokazuje, że są one sumą różnego rodzaju błędów. Praktyka pokazuje, że rozkład prawdopodobieństwa błędów pomiarowych jest zbliżony do normalnego prawa.
Za pomocą funkcji Laplace'a można rozwiązać zadania obliczania prawdopodobieństwa wpadnięcia w zadany przedział i zadanego odchylenia normalnej zmiennej losowej.
Zagadnienie to było od dawna szczegółowo badane, a najszerzej wykorzystywana była metoda współrzędnych biegunowych zaproponowana przez George'a Boxa, Mervyna Mullera i George'a Marsaglia w 1958 roku. Ta metoda pozwala uzyskać parę niezależnych zmiennych losowych o normalnym rozkładzie ze średnią 0 i wariancją 1 w następujący sposób:
Gdzie Z 0 i Z 1 są wartościami pożądanymi, s \u003d u 2 + v 2, a u i v są zmiennymi losowymi równomiernie rozłożonymi na odcinku (-1, 1), dobranymi w taki sposób, aby spełniony był warunek 0< s < 1.
Wielu używa tych formuł bez zastanowienia, a wielu nawet nie podejrzewa ich istnienia, ponieważ korzysta z gotowych implementacji. Ale są ludzie, którzy mają pytania: „Skąd wzięła się ta formuła? A dlaczego od razu otrzymujesz parę wartości? Poniżej postaram się dać jasną odpowiedź na te pytania.
Na początek przypomnę, czym jest gęstość prawdopodobieństwa, dystrybuant zmiennej losowej i funkcja odwrotna. Załóżmy, że istnieje jakaś zmienna losowa, której rozkład jest określony przez funkcję gęstości f(x), która ma postać:

Oznacza to, że prawdopodobieństwo, że wartość tej zmiennej losowej będzie w przedziale (A, B) jest równe powierzchni zacieniowanego obszaru. W konsekwencji pole całego zacieniowanego obszaru powinno być równe jedności, ponieważ w każdym przypadku wartość zmiennej losowej będzie należała do dziedziny funkcji f.
Funkcja dystrybucji zmiennej losowej jest całką funkcji gęstości. A w tym przypadku jego przybliżona forma będzie wyglądać następująco:

Tutaj znaczenie jest takie, że wartość zmiennej losowej będzie mniejsza niż A z prawdopodobieństwem B. W efekcie funkcja nigdy się nie zmniejsza, a jej wartości leżą w przedziale .
Funkcja odwrotna to funkcja, która zwraca argument oryginalnej funkcji, jeśli przekażesz do niej wartość oryginalnej funkcji. Na przykład dla funkcji x 2 odwrotnością będzie funkcja ekstrakcji pierwiastków, dla sin (x) jest to arcsin (x) itd.
Ponieważ większość generatorów liczb pseudolosowych daje na wyjściu tylko rozkład równomierny, często konieczne jest przekonwertowanie go na inny. W tym przypadku do normalnego Gaussa:

Podstawą wszystkich metod przekształcania rozkładu równomiernego w dowolny inny rozkład jest metoda transformacji odwrotnej. Działa w następujący sposób. Znaleziono funkcję, która jest odwrotna do funkcji o wymaganym rozkładzie, a zmienna losowa równomiernie rozłożona na segmencie (0, 1) jest do niej przekazywana jako argument. Na wyjściu otrzymujemy wartość o wymaganym rozkładzie. Dla jasności oto poniższy obrazek.

W ten sposób jednolity segment jest niejako rozmazany zgodnie z nowym rozkładem, rzutowany na inną oś poprzez funkcję odwrotną. Problem polega jednak na tym, że całka z gęstości rozkładu Gaussa nie jest łatwa do obliczenia, więc powyżsi naukowcy musieli oszukiwać.
Istnieje rozkład chi-kwadrat (rozkład Pearsona), który jest rozkładem sumy kwadratów k niezależnych normalnych zmiennych losowych. A w przypadku, gdy k = 2, rozkład ten jest wykładniczy.

Oznacza to, że jeśli punkt w prostokątnym układzie współrzędnych ma losowe współrzędne X i Y rozłożone normalnie, to po przeliczeniu tych współrzędnych na układ biegunowy (r, θ) kwadrat promienia (odległość od początku do punktu) będzie rozkładany wykładniczo, ponieważ kwadrat promienia jest sumą kwadratów współrzędnych (zgodnie z prawem Pitagorasa). Gęstość rozkładu takich punktów na płaszczyźnie będzie wyglądać tak:


Ponieważ jest równy we wszystkich kierunkach, kąt θ będzie miał rozkład równomierny w zakresie od 0 do 2π. Prawdą jest również odwrotność: jeśli określisz punkt w układzie współrzędnych biegunowych za pomocą dwóch niezależnych zmiennych losowych (kąt rozłożony równomiernie i promień rozłożony wykładniczo), to współrzędne prostokątne tego punktu będą niezależnymi normalnymi zmiennymi losowymi. A rozkład wykładniczy z rozkładu równomiernego jest już znacznie łatwiejszy do uzyskania przy użyciu tej samej metody odwrotnej transformacji. To jest istota metody biegunowej Boxa-Mullera.
Teraz weźmy formuły.
![]() (1)
(1)
Aby otrzymać r i θ, konieczne jest wygenerowanie dwóch zmiennych losowych równomiernie rozłożonych na odcinku (0, 1) (nazwijmy je u i v), z których rozkład jednej (powiedzmy v) musi zostać przekonwertowany na wykładniczy na uzyskać promień. Funkcja rozkładu wykładniczego wygląda tak:
Jego odwrotna funkcja:
![]()
Ponieważ rozkład jednostajny jest symetryczny, transformacja będzie działała podobnie z funkcją
![]()
Ze wzoru na rozkład chi-kwadrat wynika, że λ = 0,5. Podstawiamy λ, v do tej funkcji i otrzymujemy kwadrat promienia, a następnie sam promień:

Kąt uzyskujemy przez rozciągnięcie segmentu jednostkowego do 2π:
Teraz podstawiamy r i θ do wzorów (1) i otrzymujemy:
 (2)
(2)
Te formuły są gotowe do użycia. X i Y będą niezależne i mają rozkład normalny z wariancją 1 i średnią 0. Aby otrzymać rozkład o innych cechach, wystarczy pomnożyć wynik funkcji przez odchylenie standardowe i dodać średnią.
Ale można pozbyć się funkcji trygonometrycznych, podając kąt nie bezpośrednio, ale pośrednio poprzez prostokątne współrzędne losowego punktu na okręgu. Następnie poprzez te współrzędne będzie można obliczyć długość wektora promienia, a następnie znaleźć cosinus i sinus dzieląc przez nie odpowiednio x i y. Jak i dlaczego to działa?
Wybieramy dowolny punkt z równomiernie rozłożonego w okręgu o promieniu jednostkowym i oznaczamy kwadrat długości wektora promienia tego punktu literą s:

Wyboru dokonuje się poprzez przypisanie losowych współrzędnych prostokątnych x i y równomiernie rozłożonych w przedziale (-1, 1) oraz odrzucenie punktów nienależących do okręgu, a także punktu środkowego, w którym znajduje się kąt wektora promienia Nie określono. Czyli warunek 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Otrzymujemy wzory, jak na początku artykułu. Wadą tej metody jest odrzucanie punktów, które nie wchodzą w skład koła. Czyli wykorzystując tylko 78,5% wygenerowanych zmiennych losowych. Na starszych komputerach brak funkcji trygonometrycznych nadal był dużą zaletą. Teraz, gdy jedna instrukcja procesora jednocześnie oblicza sinus i cosinus w jednej chwili, myślę, że te metody mogą nadal konkurować.
Osobiście mam jeszcze dwa pytania:
- Dlaczego wartość s jest równomiernie rozłożona?
- Dlaczego suma kwadratów dwóch normalnych zmiennych losowych ma rozkład wykładniczy?

Jeśli podobne przekształcenie zostanie wykonane dla normalnej zmiennej losowej, to funkcja gęstości jej kwadratu okaże się podobna do hiperboli. A dodanie dwóch kwadratów normalnych zmiennych losowych jest już znacznie bardziej złożonym procesem związanym z podwójną integracją. A fakt, że wynik będzie rozkładem wykładniczym, osobiście, pozostaje mi sprawdzić to praktyczną metodą lub przyjąć jako aksjomat. A zainteresowanym proponuję bliższe zapoznanie się z tematem, czerpiąc wiedzę z tych książek:
- Wentzel E.S. Teoria prawdopodobieństwa
- Knut D.E. Sztuka programowania Tom 2
Na zakończenie podam przykład implementacji generatora liczb losowych o rozkładzie normalnym w JavaScript:
Funkcja Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( średnia = średnia == niezdefiniowana ? 0.0: średnia; dev = dev == niezdefiniowana ? 1.0: dev; if ( this.ready) ( this.ready = false; zwróć this.second * dev + średnia; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + średnia; ) ); ) g = new Gauss(); // utwórz obiekt a = g.next(); // wygeneruj parę wartości i uzyskaj pierwszą b = g.next(); // pobierz drugie c = g.next(); // ponownie wygeneruj parę wartości i uzyskaj pierwszą
Parametry średnia (oczekiwanie matematyczne) i dev (odchylenie standardowe) są opcjonalne. Zwracam uwagę na fakt, że logarytm jest naturalny.
