توزیع تصادفی یکنواخت تبدیل یک متغیر تصادفی با توزیع یکنواخت به یک متغیر با توزیع معمولی
به عنوان مثالی از یک متغیر تصادفی پیوسته، یک متغیر تصادفی X را در نظر بگیرید که به طور یکنواخت در بازه (a; b) توزیع شده است. متغیر تصادفی X گفته می شود به طور منظم توزیع شده در بازه (a; b)، اگر چگالی توزیع آن در این بازه ثابت نباشد:
از شرط نرمال سازی مقدار ثابت c را تعیین می کنیم. مساحت زیر منحنی چگالی توزیع باید برابر با واحد باشد، اما در مورد ما مساحت یک مستطیل با پایه (b - α) و ارتفاع c (شکل 1) است. 
برنج. 1 چگالی توزیع یکنواخت
از اینجا مقدار ثابت c را پیدا می کنیم: ![]()
بنابراین، چگالی یک متغیر تصادفی با توزیع یکنواخت برابر است 
اجازه دهید اکنون تابع توزیع را با استفاده از فرمول پیدا کنیم:
1) برای ![]()
2) برای
3) برای 0+1+0=1.
بدین ترتیب، 
تابع توزیع پیوسته است و کاهش نمی یابد (شکل 2). 
برنج. 2 تابع توزیع یک متغیر تصادفی توزیع شده یکنواخت
پیدا خواهیم کرد انتظارات ریاضی از یک متغیر تصادفی توزیع شده یکنواختطبق فرمول:
پراکندگی توزیع یکنواختبا فرمول محاسبه می شود و برابر است با
مثال شماره 1. مقدار تقسیم مقیاس دستگاه اندازه گیری 0.2 است. قرائت های ابزار به نزدیکترین تقسیم کل گرد می شوند. احتمال خطا در هنگام شمارش را بیابید: الف) کمتر از 0.04. ب) بزرگ 0.02
راه حل. خطای گرد کردن یک متغیر تصادفی است که به طور یکنواخت در فاصله بین تقسیمات اعداد صحیح مجاور توزیع می شود. اجازه دهید بازه (0؛ 0.2) را به عنوان چنین تقسیمی در نظر بگیریم (شکل a). گرد کردن را می توان هم به سمت مرز چپ - 0 و هم به سمت راست - 0.2 انجام داد، به این معنی که خطای کمتر یا مساوی 0.04 را می توان دو بار انجام داد، که باید هنگام محاسبه احتمال در نظر گرفته شود: 

P = 0.2 + 0.2 = 0.4
برای مورد دوم، مقدار خطا در هر دو مرز تقسیم میتواند از 0.02 تجاوز کند، یعنی میتواند بیشتر از 0.02 یا کمتر از 0.18 باشد. 
سپس احتمال خطای زیر وجود دارد:
مثال شماره 2. فرض بر این بود که ثبات وضعیت اقتصادی در کشور (عدم جنگ، بلایای طبیعی و غیره) در 50 سال گذشته را می توان بر اساس ماهیت توزیع جمعیت بر اساس سن قضاوت کرد: در یک وضعیت آرام باید چنین باشد. لباس فرم. در نتیجه مطالعه، داده های زیر برای یکی از کشورها به دست آمد.
آیا دلیلی وجود دارد که باور کنیم بی ثباتی در کشور وجود داشته است؟حل را با استفاده از ماشین حساب انجام می دهیم.آزمایش فرضیه ها. جدول برای محاسبه شاخص ها.
| گروه ها | نقطه میانی بازه، x i | مقدار، f i | x i * f i | فرکانس انباشته، S | |x - x av |*f | (x - x میانگین) 2 *f | فرکانس، f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
میانگین وزنی
شاخص های تنوع.
تغییرات مطلق.
دامنه تغییرات تفاوت بین حداکثر و حداقل مقادیر مشخصه سری اولیه است.
R = X max - X min
R = 70 - 0 = 70
پراکندگی- اندازه گیری پراکندگی را در اطراف مقدار متوسط آن مشخص می کند (معیار پراکندگی، یعنی انحراف از میانگین).
انحراف معیار.
هر مقدار از سری با مقدار متوسط 43 بیش از 23.92 تفاوت دارد
آزمون فرضیه ها در مورد نوع توزیع.
4. آزمون فرضیه در مورد توزیع یکنواختجمعیت عمومی.
به منظور آزمون فرضیه توزیع یکنواخت X، i.e. طبق قانون: f(x) = 1/(b-a) در بازه (a,b)
لازم:
1. پارامترهای a و b را تخمین بزنید - انتهای بازه ای که در آن مقادیر احتمالی X مشاهده شد با استفاده از فرمول ها (علامت * نشان دهنده برآورد پارامتر است):
2. چگالی احتمال توزیع مورد انتظار f(x) = 1/(b * - a *) را بیابید.
3. فرکانس های نظری را بیابید:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. بسامدهای تجربی و نظری را با استفاده از معیار پیرسون با در نظر گرفتن تعداد درجات آزادی k = s-3 مقایسه کنید، جایی که s تعداد فواصل نمونه گیری اولیه است. اگر ترکیبی از فرکانسهای کوچک، و در نتیجه خود فواصل، انجام شود، s تعداد بازههای باقی مانده پس از ترکیب است.
راه حل:
1. برآورد پارامترهای a * و b * توزیع یکنواخت را با استفاده از فرمولها بیابید:
2. چگالی توزیع یکنواخت فرضی را بیابید:
f(x) = 1/(b * - a *) = 1/(84.42 - 1.58) = 0.0121
3. بیایید فرکانس های نظری را پیدا کنیم:
n 1 = n*f(x)(x 1 - a *) = 1 * 0.0121(10-1.58) = 0.1
n 8 = n*f(x)(b * - x 7) = 1 * 0.0121(84.42-70) = 0.17
n s باقیمانده برابر خواهد بود با:
n s = n*f(x)(x i - x i-1)
| من | n من | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| جمع | 1 | 0.0532 |
بنابراین، منطقه بحرانی برای این آمار همیشه راست دست است: اگر چگالی احتمال آن در این بخش ثابت باشد و در خارج از آن برابر با 0 باشد (یعنی یک متغیر تصادفی). ایکسمتمرکز بر بخش [ آ, ب] که روی آن چگالی ثابت دارد). طبق این تعریف، چگالی به طور یکنواخت بر روی قطعه [ آ, ب] متغیر تصادفی ایکسدارای فرم:
جایی که باعدد مشخصی وجود دارد با این حال، یافتن با استفاده از خاصیت چگالی احتمال برای متغیرهای تصادفی متمرکز بر بخش [ آ,
ب]:
 . نتیجه می شود که
. نتیجه می شود که  ، جایی که
، جایی که  . بنابراین، چگالی به طور یکنواخت بر روی قطعه [ آ,
ب] متغیر تصادفی ایکسدارای فرم:
. بنابراین، چگالی به طور یکنواخت بر روی قطعه [ آ,
ب] متغیر تصادفی ایکسدارای فرم:
 .
.
یکنواختی توزیع n.s.v را قضاوت کنید. ایکسبا توجه به ملاحظات زیر امکان پذیر است. یک متغیر تصادفی پیوسته دارای توزیع یکنواخت در بازه [ آ, ب]، در صورتی که فقط از این بخش مقادیر بگیرد و هر عددی از این بخش نسبت به سایر اعداد این بخش مزیتی نداشته باشد به این معنا که بتواند مقداری از این متغیر تصادفی باشد.
متغیرهای تصادفی که دارای توزیع یکنواخت هستند شامل مقادیری مانند زمان انتظار برای حمل و نقل در یک توقف (با فاصله ترافیک ثابت، مدت زمان انتظار به طور یکنواخت در این بازه توزیع می شود)، خطا در گرد کردن یک عدد به یک عدد صحیح (به طور یکنواخت) توزیع شده روی [-0.5 , 0.5 ]) و دیگران.
نوع تابع توزیع اف(ایکس)
آ,
ب] متغیر تصادفی ایکسجستجو با چگالی احتمال شناخته شده f(ایکس)
با استفاده از فرمول اتصال آنها  . در نتیجه محاسبات مربوطه، فرمول زیر را برای تابع توزیع به دست می آوریم اف(ایکس)
بخش توزیع یکنواخت [ آ,
ب] متغیر تصادفی ایکس
:
. در نتیجه محاسبات مربوطه، فرمول زیر را برای تابع توزیع به دست می آوریم اف(ایکس)
بخش توزیع یکنواخت [ آ,
ب] متغیر تصادفی ایکس
:
 .
.
شکل ها نمودارهای چگالی احتمال را نشان می دهند f(ایکس) و توابع توزیع f(ایکس) بخش توزیع یکنواخت [ آ, ب] متغیر تصادفی ایکس :


انتظار، واریانس، انحراف معیار، حالت و میانه یک بخش توزیع شده یکنواخت [ آ, ب] متغیر تصادفی ایکسبا چگالی احتمال محاسبه می شود f(ایکس) به روش معمول (و کاملاً به دلیل ظاهر ساده f(ایکس) ). نتیجه فرمول های زیر است:
و مد د(ایکس) هر عددی در بازه [ آ, ب].
اجازه دهید احتمال برخورد با یک بخش توزیع شده یکنواخت را پیدا کنیم [ آ,
ب] متغیر تصادفی ایکسدر فاصله زمانی  ، کاملاً درون خوابیده [ آ,
ب]. با در نظر گرفتن شکل شناخته شده تابع توزیع، به دست می آوریم:
، کاملاً درون خوابیده [ آ,
ب]. با در نظر گرفتن شکل شناخته شده تابع توزیع، به دست می آوریم:
بنابراین، احتمال برخورد به بخش توزیع یکنواخت [ آ,
ب] متغیر تصادفی ایکسدر فاصله زمانی  ، کاملاً درون خوابیده [ آ,
ب]، به موقعیت این بازه بستگی ندارد، بلکه فقط به طول آن بستگی دارد و با این طول متناسب است.
، کاملاً درون خوابیده [ آ,
ب]، به موقعیت این بازه بستگی ندارد، بلکه فقط به طول آن بستگی دارد و با این طول متناسب است.
مثال. فاصله اتوبوس 10 دقیقه است. احتمال اینکه مسافری که به ایستگاه اتوبوس می رسد کمتر از 3 دقیقه منتظر اتوبوس بماند چقدر است؟ میانگین زمان انتظار برای اتوبوس چقدر است؟
توزیع نرمال
این توزیع بیشتر در عمل مشاهده می شود و نقش استثنایی در نظریه احتمالات و آمار ریاضی و کاربردهای آنها دارد، زیرا بسیاری از متغیرهای تصادفی در علوم طبیعی، اقتصاد، روانشناسی، جامعه شناسی، علوم نظامی و غیره دارای چنین توزیعی هستند. این توزیع یک قانون محدود کننده است که بسیاری از قوانین توزیع دیگر (در شرایط طبیعی معین) به آن نزدیک می شوند. با استفاده از قانون توزیع نرمال، پدیده هایی که در معرض عمل بسیاری از عوامل تصادفی مستقل از هر ماهیت و هر قانون توزیع آنها هستند نیز توصیف می شوند. بیایید به سراغ تعاریف برویم.
یک متغیر تصادفی پیوسته توزیع شده روی نامیده می شود قانون عادی (یا قانون گاوس)، اگر چگالی احتمال آن به شکل زیر باشد:
 ,
,
اعداد کجا هستند آو σ (σ>0 ) پارامترهای این توزیع هستند.
همانطور که قبلا ذکر شد، قانون توزیع متغیرهای تصادفی گاوس کاربردهای متعددی دارد. بر اساس این قانون، خطاهای اندازه گیری توسط ابزار، انحراف از مرکز هدف در هنگام تیراندازی، ابعاد قطعات ساخته شده، وزن و قد افراد، بارندگی سالانه، تعداد نوزادان و بسیاری موارد دیگر توزیع می شود.
فرمول داده شده برای چگالی احتمال یک متغیر تصادفی با توزیع نرمال، همانطور که گفته شد، شامل دو پارامتر است. آو σ و بنابراین خانواده ای از توابع را تعریف می کند که بسته به مقادیر این پارامترها متفاوت است. اگر روشهای معمول تحلیل ریاضی مطالعه توابع و رسم نمودارها را برای چگالی احتمال یک توزیع نرمال به کار ببریم، میتوانیم به نتایج زیر دست یابیم.

نقاط عطف آن هستند.
بر اساس اطلاعات دریافتی، یک نمودار چگالی احتمال می سازیم f(ایکس) توزیع نرمال (به آن منحنی گاوسی می گویند - شکل).

بیایید دریابیم که تغییر پارامترها چگونه تأثیر می گذارد آو σ به شکل منحنی گاوسی. بدیهی است (این را می توان از فرمول چگالی توزیع نرمال مشاهده کرد) که تغییر در پارامتر آشکل منحنی را تغییر نمی دهد، بلکه تنها منجر به تغییر آن به راست یا چپ در امتداد محور می شود. ایکس. وابستگی σ سخت تر. از مطالعه بالا مشخص می شود که چگونه مقدار حداکثر و مختصات نقاط عطف به پارامتر بستگی دارد. σ . علاوه بر این، ما باید این را در نظر بگیریم که برای هر پارامتر آو σ مساحت زیر منحنی گاوس برابر با 1 باقی می ماند (این یک ویژگی کلی چگالی احتمال است). از موارد فوق چنین استنباط می شود که با افزایش پارامتر σ منحنی صاف تر می شود و در امتداد محور کشیده می شود ایکس. شکل منحنی های گاوسی را برای مقادیر مختلف پارامتر نشان می دهد σ (σ 1 < σ< σ 2 ) و همان مقدار پارامتر آ.

بیایید معنای احتمالی پارامترها را دریابیم آو σ
توزیع نرمال. قبلاً از تقارن منحنی گاوسی نسبت به خط عمودی عبور از عدد آروی محور ایکسواضح است که مقدار متوسط (یعنی انتظارات ریاضی M(X)) یک متغیر تصادفی با توزیع نرمال برابر است با آ. به همین دلایل، مد و میانه نیز باید برابر با عدد a باشد. محاسبات دقیق با استفاده از فرمول های مناسب این موضوع را تایید می کند. اگر از عبارت نوشته شده در بالا برای استفاده کنیم f(ایکس)
در فرمول واریانس جایگزین کنید  ، سپس پس از یک محاسبه (نسبتاً پیچیده) انتگرال، عدد موجود در پاسخ را دریافت می کنیم. σ
2
. بنابراین، برای یک متغیر تصادفی ایکسبا توزیع بر اساس قانون عادی، مشخصه های عددی اصلی زیر به دست آمد:
، سپس پس از یک محاسبه (نسبتاً پیچیده) انتگرال، عدد موجود در پاسخ را دریافت می کنیم. σ
2
. بنابراین، برای یک متغیر تصادفی ایکسبا توزیع بر اساس قانون عادی، مشخصه های عددی اصلی زیر به دست آمد:
بنابراین، معنای احتمالی پارامترهای توزیع نرمال است آو σ بعد. اگر r.v. ایکسآو σ آ σ.
اجازه دهید اکنون تابع توزیع را پیدا کنیم اف(ایکس)
برای یک متغیر تصادفی ایکس، با استفاده از عبارت فوق برای چگالی احتمال، بر اساس قانون عادی توزیع می شود f(ایکس)
و فرمول  . هنگام تعویض f(ایکس)
نتیجه یک انتگرال "غیرقابل برداشت" است. هر کاری که می توان برای ساده کردن عبارت انجام داد اف(ایکس),
این نمایش این تابع به صورت زیر است:
. هنگام تعویض f(ایکس)
نتیجه یک انتگرال "غیرقابل برداشت" است. هر کاری که می توان برای ساده کردن عبارت انجام داد اف(ایکس),
این نمایش این تابع به صورت زیر است:
 ,
,
جایی که F(x)- به اصطلاح تابع لاپلاس، که دارای فرم است
 .
.
انتگرالی که تابع لاپلاس از طریق آن بیان می شود نیز گرفته نشده است (اما برای هر یک ایکساین انتگرال را می توان تقریباً با هر دقت از پیش تعیین شده محاسبه کرد). با این حال، نیازی به محاسبه آن نیست، زیرا در پایان هر کتاب درسی نظریه احتمال، جدولی برای تعیین مقادیر تابع وجود دارد. F(x)در یک مقدار معین ایکس. در ادامه به ویژگی عجیب و غریب تابع لاپلاس نیاز داریم: Ф(−х)=−F(x)برای همه اعداد ایکس.
اجازه دهید اکنون این احتمال را پیدا کنیم که یک r.v به طور معمول توزیع شده است. ایکسمقداری از بازه عددی مشخص شده می گیرد (α, β) . از خصوصیات کلی تابع توزیع Р(α< ایکس< β)= اف(β) − اف(α) . جایگزین کردن α و β به عبارت بالا برای اف(ایکس) ، ما گرفتیم
 .
.
همانطور که در بالا گفته شد، اگر r.v. ایکسبه طور معمول با پارامترها توزیع می شود آو σ ، سپس مقدار متوسط آن است آ، و انحراف معیار برابر است با σ. از همین رو میانگینانحراف مقادیر این r.v. وقتی از شماره تست شد آبرابر است σ. اما این انحراف متوسط است. بنابراین، انحرافات بزرگتر ممکن است. بیایید دریابیم که انحرافات خاص از مقدار متوسط چقدر ممکن است. اجازه دهید این احتمال را پیدا کنیم که مقدار یک متغیر تصادفی بر اساس قانون عادی توزیع شده است ایکساز مقدار متوسط آن منحرف شود M(X)=aکمتر از عدد معین δ، یعنی. آر(| ایکس− آ|<δ ): . بدین ترتیب،
 .
.
جایگزینی به این برابری δ=3σ، این احتمال را به دست می آوریم که مقدار r.v. ایکس(در یک آزمون) از مقدار متوسط کمتر از سه برابر مقدار انحراف خواهد داشت σ (با میانگین انحراف، همانطور که به یاد داریم، برابر است σ ): (به معنی F(3)برگرفته از جدول مقادیر تابع لاپلاس). تقریبا 1 ! سپس احتمال رویداد مخالف (که مقدار کمتر از آن انحراف داشته باشد 3σ) برابر است با 1 −0.997=0.003 ، که بسیار نزدیک است 0 . بنابراین، این رویداد "تقریبا غیر ممکن است" − بسیار به ندرت اتفاق می افتد (به طور متوسط 3 زمان تمام شد 1000 ). این استدلال دلیل منطقی برای معروف "قاعده سه سیگما" است.
قانون سه سیگما. متغیر تصادفی معمولی توزیع شده در یک آزمونعملا از میانگین خود بیشتر از آن انحراف ندارد 3σ.
اجازه دهید یک بار دیگر تاکید کنیم که ما در مورد یک آزمون صحبت می کنیم. اگر تست های زیادی از یک متغیر تصادفی وجود داشته باشد، این امکان وجود دارد که برخی از مقادیر آن بیشتر از میانگین حرکت کنند. 3σ. این امر با موارد زیر تأیید می شود
مثال. احتمال اینکه در 100 آزمایش یک متغیر تصادفی معمولی توزیع شده باشد چقدر است ایکسآیا حداقل یکی از مقادیر آن بیش از سه برابر انحراف استاندارد از میانگین منحرف خواهد شد؟ 1000 تست چطور؟
راه حل. اجازه دهید رویداد آبه این معنی است که هنگام آزمایش یک متغیر تصادفی ایکسمقدار آن از میانگین بیش از 3σ.همانطور که اخیراً روشن شد، احتمال این رویداد وجود دارد p=P(A)=0.003. 100 آزمایش از این دست انجام شد. ما باید احتمال وقوع این رویداد را دریابیم آاتفاق افتاد حداقلبارها، یعنی آمده از 1 قبل از 100 یک بار. این یک مسئله معمولی مدار برنولی با پارامترها است n=100 (تعداد آزمایشات مستقل)، p=0.003(احتمال رخداد آدر یک آزمایش) q=1− پ=0.997 . نیاز به پیدا کردن آر 100 (1≤ ک≤100) . در این صورت، البته، در ابتدا به راحتی می توان احتمال رویداد مخالف را پیدا کرد آر 100 (0) - احتمال وقوع رویداد آحتی یک بار هم اتفاق نیفتاد (یعنی 0 بار اتفاق افتاد). با در نظر گرفتن ارتباط بین احتمالات خود رویداد و مخالف آن، به دست می آوریم:
نه چندان کم. ممکن است این اتفاق بیفتد (به طور متوسط در هر چهارمین سری از این آزمایشات اتفاق می افتد). در 1000 با استفاده از آزمون های مشابه، می توان به دست آورد که احتمال حداقل یک انحراف بیشتر از 3σ، برابر است با: . بنابراین ما می توانیم با اطمینان زیاد حداقل یک چنین انحرافی را انتظار داشته باشیم.
مثال. قد مردان در یک گروه سنی خاص به طور معمول با انتظارات ریاضی توزیع می شود آ، و انحراف معیار σ . چه نسبت کت و شلوار کرشد باید در کل تولید برای یک گروه سنی معین لحاظ شود اگر کرشد هفتم با محدودیت های زیر تعیین می شود:
1 ارتفاع : 158 − 164 سانتی متر 2ارتفاع : 164 − 170 سانتی متر 3ارتفاع : 170 − 176 سانتی متر 4ارتفاع : 176 − 182 سانتی متر
راه حل. بیایید با مقادیر پارامتر زیر مشکل را حل کنیم: a=178،σ=6ک=3
. اجازه دهید r.v. ایکس
−
قد یک مرد به طور تصادفی انتخاب شده (به طور معمول با پارامترهای داده شده توزیع می شود). بیایید این احتمال را پیدا کنیم که یک مرد تصادفی انتخاب شده به آن نیاز دارد 3
-قدم با استفاده از عجیب بودن تابع لاپلاس F(x)و جدول مقادیر آن: P(170
توزیع احتمال یک متغیر تصادفی پیوسته ایکس، گرفتن تمام مقادیر از بخش ، تماس گرفت لباس فرم، اگر چگالی احتمال آن در این قطعه ثابت و در خارج از آن برابر با صفر باشد. بنابراین، چگالی احتمال یک متغیر تصادفی پیوسته ایکس، به طور یکنواخت در بخش توزیع شده است ، دارای شکل:

تعریف کنیم ارزش مورد انتظار, پراکندگیو برای یک متغیر تصادفی با توزیع یکنواخت.
, ![]() ,
, ![]() .
.
مثال.تمام مقادیر یک متغیر تصادفی توزیع شده یکنواخت در بازه قرار دارند . احتمال افتادن یک متغیر تصادفی در بازه را بیابید (3;5) .
a=2، b=8،  .
.
توزیع دو جمله ای
بذار تولید بشه nتست ها و احتمال وقوع رویداد آدر هر آزمایشی برابر است پو مستقل از نتیجه کارآزمایی های دیگر (کارآزمایی های مستقل) است. از آنجایی که احتمال وقوع یک رویداد وجود دارد آدر یک آزمون برابر است با پ، پس احتمال عدم وقوع آن برابر است با q=1-p.
اجازه دهید رویداد آوارد شد nتست ها متریک بار. این رویداد پیچیده را می توان به عنوان یک محصول نوشت:
![]() .
.
سپس این احتمال وجود دارد که nرویداد تست آخواهد آمد متربار، با فرمول محاسبه می شود:
![]() یا
یا ![]() (1)
(1)
فرمول (1) نامیده می شود فرمول برنولی.
اجازه دهید ایکس- یک متغیر تصادفی برابر با تعداد وقوع رویداد آ V nتست هایی که مقادیر با احتمالات را می گیرد:
قانون توزیع حاصل از یک متغیر تصادفی نامیده می شود قانون توزیع دوجمله ای.
| ایکس | متر | n | ||||
| پ |
ارزش مورد انتظار, پراکندگیو انحراف معیارمتغیرهای تصادفی توزیع شده بر اساس قانون دو جمله ای با فرمول های زیر تعیین می شوند:
, , .
مثال.سه تیر به سمت هدف شلیک می شود و احتمال اصابت هر شلیک 0.8 است. یک متغیر تصادفی را در نظر بگیرید ایکس- تعداد ضربه به هدف قانون توزیع، انتظارات ریاضی، پراکندگی و انحراف معیار آن را بیابید.
p=0.8, q=0.2, n=3, ![]() , ,
, , ![]() .
.
![]() - احتمال 0 بازدید؛
- احتمال 0 بازدید؛
احتمال یک ضربه؛
احتمال دو ضربه؛
![]() - احتمال سه ضربه
- احتمال سه ضربه
قانون توزیع را بدست می آوریم:
| ایکس | ||||
| پ | 0,008 | 0,096 | 0,384 | 0,512 |
وظایف
1. یک سکه 7 بار پرتاب می شود. احتمال فرود وارونه 4 بار را پیدا کنید.
2. یک سکه 8 بار پرتاب می شود. احتمال ظاهر شدن نشان را بیش از سه بار پیدا کنید.
3. احتمال اصابت به هدف هنگام شلیک از تفنگ p=0.6. در صورت شلیک 10 شلیک، انتظار ریاضی تعداد کل ضربه ها را بیابید.
4. انتظار ریاضی تعداد بلیط های بخت آزمایی را که در صورت خرید 20 بلیط برنده می شوند را بیابید و احتمال برنده شدن در یک بلیط 0.3 است.
تابع توزیع در این مورد، مطابق (5.7)، به شکل زیر خواهد بود:
جایی که: m - انتظار ریاضی، s - انحراف معیار.
توزیع نرمال به نام گاوس ریاضیدان آلمانی نیز گاوسی نامیده می شود. این واقعیت که یک متغیر تصادفی دارای توزیع نرمال با پارامترهای: m است، به صورت زیر نشان داده می شود: N (m,s)، که در آن: m =a =M ;
اغلب در فرمول ها، انتظارات ریاضی با نشان داده می شود آ . اگر یک متغیر تصادفی بر اساس قانون N(0,1) توزیع شود، آن را متغیر نرمال شده یا استاندارد شده می نامند. تابع توزیع برای آن به شکل زیر است:
|
|
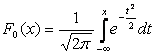 .
.نمودار چگالی یک توزیع نرمال که منحنی نرمال یا منحنی گاوسی نامیده می شود، در شکل 5.4 نشان داده شده است.

برنج. 5.4. چگالی توزیع نرمال
تعیین ویژگی های عددی یک متغیر تصادفی با چگالی آن با استفاده از یک مثال در نظر گرفته می شود.
مثال 6.
یک متغیر تصادفی پیوسته با چگالی توزیع مشخص می شود: ![]() .
.
نوع توزیع را تعیین کنید، انتظار ریاضی M(X) و واریانس D(X) را پیدا کنید.
با مقایسه چگالی توزیع داده شده با (5.16)، می توان نتیجه گرفت که قانون توزیع نرمال با m = 4 داده شده است. بنابراین انتظار ریاضی M(X)=4، واریانس D(X)=9.
انحراف معیار s=3.
تابع لاپلاس که به شکل زیر است:
|
|
 ,
,مربوط به تابع توزیع نرمال (5.17) است، رابطه:
F 0 (x) = Ф(x) + 0.5.
تابع لاپلاس فرد است.
Ф(-x)=-Ф(x).
مقادیر تابع لاپلاس Ф(х) جدول بندی شده و با توجه به مقدار x از جدول گرفته شده است (پیوست 1 را ببینید).
توزیع نرمال یک متغیر تصادفی پیوسته نقش مهمی در نظریه احتمالات و در توصیف واقعیت ایفا می کند؛ این توزیع در پدیده های تصادفی طبیعی بسیار گسترده است. در عمل، اغلب با متغیرهای تصادفی مواجه می شویم که دقیقاً در نتیجه جمع آوری بسیاری از عبارت های تصادفی شکل می گیرند. به طور خاص، تجزیه و تحلیل خطاهای اندازه گیری نشان می دهد که آنها مجموع انواع مختلف خطاها هستند. تمرین نشان می دهد که توزیع احتمال خطاهای اندازه گیری نزدیک به قانون عادی است.
با استفاده از تابع لاپلاس می توانید مشکل محاسبه احتمال سقوط به بازه معین و انحراف معین یک متغیر تصادفی نرمال را حل کنید.
این موضوع از دیرباز به تفصیل مورد بررسی قرار گرفته است و پرکاربردترین روش، روش مختصات قطبی است که توسط جرج باکس، مروین مولر و جورج مارسالیا در سال 1958 ارائه شد. این روش به شما امکان می دهد یک جفت متغیر تصادفی با توزیع نرمال مستقل را با انتظارات ریاضی 0 و واریانس 1 به صورت زیر بدست آورید:
در جایی که Z 0 و Z 1 مقادیر مورد نظر هستند، s = u 2 + v 2، و u و v متغیرهای تصادفی هستند که به طور یکنواخت در بازه (-1، 1) توزیع شده اند، به گونه ای انتخاب شده اند که شرط 0 برآورده شود.< s < 1.
بسیاری از افراد بدون حتی فکر کردن از این فرمول ها استفاده می کنند و بسیاری از آنها حتی به وجود آنها مشکوک نیستند، زیرا از پیاده سازی های آماده استفاده می کنند. اما افرادی هستند که سؤالاتی دارند: «این فرمول از کجا آمده است؟ و چرا چند مقدار را در یک زمان دریافت می کنید؟ در ادامه سعی خواهم کرد به این سوالات پاسخ روشنی بدهم.
برای شروع، اجازه دهید به شما یادآوری کنم که چگالی احتمال، تابع توزیع یک متغیر تصادفی و تابع معکوس چیست. فرض کنید یک متغیر تصادفی خاص وجود دارد که توزیع آن با تابع چگالی f(x) مشخص شده است که به شکل زیر است:

این به این معنی است که احتمال اینکه مقدار یک متغیر تصادفی معین در بازه (A, B) باشد برابر با مساحت ناحیه سایهدار است. و در نتیجه، مساحت کل منطقه سایه دار باید برابر با یک باشد، زیرا در هر صورت مقدار متغیر تصادفی در دامنه تعریف تابع f قرار می گیرد.
تابع توزیع یک متغیر تصادفی انتگرال تابع چگالی است. و در این صورت ظاهر تقریبی آن به این صورت خواهد بود:

منظور در اینجا این است که مقدار متغیر تصادفی با احتمال B کمتر از A خواهد بود و در نتیجه تابع هرگز کاهش نمی یابد و مقادیر آن در بازه قرار می گیرد.
تابع معکوس تابعی است که اگر مقدار تابع اصلی به آن داده شود، آرگومان را به تابع اصلی برمی گرداند. به عنوان مثال، برای تابع x 2 معکوس تابع استخراج ریشه است، برای sin(x) arcsin(x) و غیره است.
از آنجایی که اکثر مولدهای اعداد شبه تصادفی تنها یک توزیع یکنواخت را به عنوان خروجی تولید می کنند، اغلب نیاز به تبدیل آن به توزیع دیگری وجود دارد. در این مورد، به گاوسی معمولی:

اساس همه روش ها برای تبدیل یک توزیع یکنواخت به هر توزیع دیگر، روش تبدیل معکوس است. به صورت زیر عمل می کند. تابعی پیدا می شود که معکوس تابع توزیع مورد نیاز است و یک متغیر تصادفی که به طور یکنواخت در بازه (0، 1) توزیع شده است به عنوان آرگومان به آن ارسال می شود. در خروجی مقداری با توزیع مورد نیاز بدست می آوریم. برای وضوح تصویر زیر را ارائه می کنم.

بنابراین، یک قطعه یکنواخت، همانطور که بود، مطابق با توزیع جدید آغشته می شود، و از طریق یک تابع معکوس بر روی محور دیگری پیش بینی می شود. اما مشکل این است که محاسبه انتگرال چگالی یک توزیع گاوسی آسان نیست، بنابراین دانشمندان فوق مجبور به تقلب شدند.
یک توزیع کای دو (توزیع پیرسون) وجود دارد که توزیع مجموع مجذورهای k متغیر تصادفی نرمال مستقل است. و در حالتی که k = 2 باشد، این توزیع نمایی است.

این بدان معنی است که اگر نقطه ای در یک سیستم مختصات مستطیلی دارای مختصات تصادفی X و Y باشد که به طور نرمال توزیع شده اند، پس از تبدیل این مختصات به سیستم قطبی (r, θ)، مربع شعاع (فاصله از مبدأ تا نقطه) بر اساس قانون نمایی توزیع خواهد شد، زیرا مربع شعاع مجموع مجذورات مختصات است (طبق قانون فیثاغورث). چگالی توزیع چنین نقاطی در هواپیما به شکل زیر خواهد بود:


از آنجایی که در همه جهات برابر است، زاویه θ توزیع یکنواختی در محدوده 0 تا 2π خواهد داشت. برعکس نیز صادق است: اگر شما یک نقطه در سیستم مختصات قطبی را با استفاده از دو متغیر تصادفی مستقل (یک زاویه توزیع یکنواخت و یک شعاع به صورت نمایی) تعریف کنید، آنگاه مختصات مستطیلی این نقطه، متغیرهای تصادفی عادی مستقل خواهند بود. و بدست آوردن یک توزیع نمایی از یک توزیع یکنواخت با استفاده از همان روش تبدیل معکوس بسیار ساده تر است. این ماهیت روش قطبی باکس-مولر است.
حالا بیایید فرمول ها را استخراج کنیم.
![]() (1)
(1)
برای به دست آوردن r و θ، لازم است دو متغیر تصادفی ایجاد شود که به طور یکنواخت در بازه (0، 1) توزیع شده اند (آنها را u و v بنامیم)، توزیع یکی از آنها (مثلا v) باید به نمایی تبدیل شود. شعاع را بدست آورید تابع توزیع نمایی به شکل زیر است:
تابع معکوس آن عبارت است از:
![]()
از آنجایی که توزیع یکنواخت متقارن است، تبدیل به طور مشابه با تابع کار خواهد کرد
![]()
از فرمول توزیع کای دو نتیجه می شود که λ = 0.5. λ، v را جایگزین این تابع کنید و مربع شعاع و سپس خود شعاع را بدست آورید:

ما زاویه را با کشش قطعه واحد به 2π بدست می آوریم:
حالا r و θ را جایگزین فرمول (1) می کنیم و به دست می آوریم:
 (2)
(2)
این فرمول ها از قبل آماده استفاده هستند. X و Y مستقل خواهند بود و معمولاً با واریانس 1 و انتظار ریاضی 0 توزیع می شوند. برای به دست آوردن توزیعی با ویژگی های دیگر کافی است نتیجه تابع را در انحراف معیار ضرب کرده و انتظار ریاضی را جمع کنیم.
اما می توان با تعیین زاویه نه مستقیم، بلکه به طور غیرمستقیم از طریق مختصات مستطیلی یک نقطه تصادفی در دایره، از شر توابع مثلثاتی خلاص شد. سپس از طریق این مختصات می توان طول بردار شعاع را محاسبه کرد و سپس با تقسیم x و y بر آن به ترتیب کسینوس و سینوس را یافت. چگونه و چرا کار می کند؟
اجازه دهید یک نقطه تصادفی از نقاطی که به طور یکنواخت در یک دایره با شعاع واحد توزیع شده اند انتخاب کنیم و مربع طول بردار شعاع این نقطه را با حرف s نشان دهیم:

انتخاب با تعیین مختصات مستطیلی تصادفی x و y که به طور یکنواخت در بازه (1-1 و 1) توزیع شده اند و دور انداختن نقاطی که به دایره تعلق ندارند و همچنین نقطه مرکزی که در آن زاویه بردار شعاع قرار دارد، انجام می شود. تعریف نشده است. یعنی شرط 0 باید رعایت شود< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
ما فرمول ها را مانند ابتدای مقاله دریافت می کنیم. عیب این روش این است که نقاطی را که در دایره قرار نمی گیرند دور می اندازد. یعنی تنها با استفاده از 78.5 درصد از متغیرهای تصادفی تولید شده. در کامپیوترهای قدیمی، فقدان توابع مثلثات هنوز یک مزیت بزرگ بود. حالا، وقتی یک دستور پردازنده هر دو سینوس و کسینوس را در یک لحظه محاسبه می کند، فکر می کنم این روش ها هنوز هم می توانند رقابت کنند.
من شخصاً هنوز دو سوال دارم:
- چرا مقدار s به طور مساوی توزیع می شود؟
- چرا مجموع مجذورات دو متغیر تصادفی عادی به صورت نمایی توزیع شده است؟

اگر یک تبدیل مشابه برای یک متغیر تصادفی معمولی انجام شود، تابع چگالی مربع آن شبیه هذلولی خواهد شد. و افزودن دو مربع از متغیرهای تصادفی معمولی فرآیند بسیار پیچیدهتری است که با ادغام مضاعف مرتبط است. و اینکه نتیجه یک توزیع نمایی خواهد بود، من شخصا فقط باید با استفاده از یک روش عملی بررسی کنم یا به عنوان بدیهیات بپذیرم. و برای علاقه مندان پیشنهاد می کنم با کسب اطلاعات از این کتاب ها به موضوع نگاه دقیق تری داشته باشند:
- ونتزل E.S. نظریه احتمال
- Knut D.E. هنر برنامه نویسی، جلد 2
در پایان، در اینجا مثالی از پیاده سازی یک تولید کننده اعداد تصادفی توزیع شده معمولی در جاوا اسکریپت آورده شده است:
تابع Gauss() (var ready = false; var second = 0.0; this.next = function(mean, dev) (mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. تصادفی() - 1.0؛ s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u؛ this.ready = true؛ return r * v * dev + mean; ) )؛ g = new Gauss(); // ایجاد یک شی a = g.next(); // یک جفت مقدار ایجاد کنید و اولین مورد را بدست آورید b = g.next(); // دریافت c دوم = g.next(); // دوباره یک جفت مقدار ایجاد کنید و اولین مورد را دریافت کنید
پارامترهای میانگین (انتظار ریاضی) و dev (انحراف استاندارد) اختیاری هستند. توجه شما را به طبیعی بودن لگاریتم جلب می کنم.
