Корелационен тест на Пиърсън. Статистическа значимост на регресионните и корелационни параметри
Въведение. 2
1. Оценка на значимостта на коефициентите на регресия и корелация с помощта на f-критерия на Стюдънт. 3
2. Изчисляване на значимостта на коефициентите на регресия и корелация с помощта на f-критерия на Стюдънт. 6
Заключение. 15
След построяването на регресионното уравнение е необходимо да се провери неговата значимост: с помощта на специални критерии определете дали получената зависимост, изразена от регресионното уравнение, е случайна, т.е. може ли да се използва за прогнозни цели и за факторен анализ. В статистиката са разработени методи за стриктно тестване на значимостта на регресионните коефициенти, като се използва анализ на дисперсията и изчисляване на специални критерии (например F-тест). Може да се извърши свободен тест чрез изчисляване на средното относително линейно отклонение (e), наречено средна грешка на приближението:
Нека сега преминем към оценка на значимостта на регресионните коефициенти bj и конструиране на доверителен интервал за параметрите на регресионния модел Ru (J=l,2,..., p).
Блок 5 - оценка на значимостта на регресионните коефициенти въз основа на стойността на ^-теста на Стюдънт. Изчислените стойности на ta се сравняват с допустимата стойност
Блок 5 - оценка на значимостта на регресионните коефициенти въз основа на стойността на ^-критерия. Изчислените стойности на t0n се сравняват с допустимата стойност 4,/, която се определя от таблиците на t-разпределението за дадена вероятност за грешка (a) и броя на степените на свобода (/).
В допълнение към проверката на значимостта на целия модел е необходимо да се тества значимостта на коефициентите на регресия с помощта на Student /-тест. Минималната стойност на регресионния коефициент br трябва да съответства на условието bifob- ^t, където bi е стойността на коефициента на регресионното уравнение в естествена скала за i-та факторна характеристика; ах - средна квадратична грешка на всеки коефициент. несравнимост на коефициентите D по тяхната значимост;
Допълнителният статистически анализ се отнася до тестването на значимостта на регресионните коефициенти. За да направим това, намираме стойността на ^-критерия за регресионните коефициенти. В резултат на тяхното сравнение се определя най-малкият ^-критерий. Факторът, чийто коефициент отговаря на най-малкия ^-критерий, се изключва от по-нататъшния анализ.
За оценка на статистическата значимост на коефициентите на регресия и корелация се изчисляват t-теста на Стюдънт и доверителните интервали за всеки показател. Излага се хипотеза за случайния характер на показателите, т.е. за тяхната незначителна разлика от нула. Оценяването на значимостта на коефициентите на регресия и корелация с помощта на f-тест на Student се извършва чрез сравняване на техните стойности с големината на случайната грешка:
Оценяването на значимостта на чистите регресионни коефициенти с помощта на /-теста на Стюдънт се свежда до изчисляване на стойността
Качеството на труда е характеристика на конкретния труд, отразяваща степента на неговата сложност, интензивност (интензивност), условия и значение за икономическото развитие. К.т. се измерва чрез тарифна система, която позволява диференциране на заплатите в зависимост от нивото на квалификация (сложността на работата), условията, тежестта на труда и неговата интензивност, както и значението на отделните отрасли и производства, региони, територии за развитието на икономиката на страната. К.т. намира израз в работната заплата на работниците, която се развива на пазара на труда под влияние на търсенето и предлагането на труд (специфични видове труд). К.т. - сложни по структура
Получените оценки на относителната важност на отделните икономически, социални и екологични последици от проекта допълнително осигуряват основа за сравняване на алтернативни проекти и техните опции, използвайки „комплексния точков безразмерен критерий за социална и екологично-икономическа ефективност“ на проекта Ek, изчислен (в средни оценки на значимост), използвайки формулата
Вътрешноотрасловото регулиране осигурява различия в заплащането на работниците в даден отрасъл в зависимост от значението на отделните видове производство в даден отрасъл, от сложността и условията на труд, както и от използваните форми на възнаграждение.
Получената рейтингова оценка на анализираното предприятие по отношение на стандартното предприятие, без да се отчита значимостта на отделните показатели, е сравнителна. При сравняване на рейтингите на няколко предприятия най-висок рейтинг се дава на предприятието с минимална стойност на получената сравнителна оценка.
Разбирането на качеството на даден продукт като мярка за неговата полезност повдига практически важен въпрос за неговото измерване. Неговото решаване се постига чрез изследване на значението на отделните свойства за задоволяване на конкретна потребност. Значимостта дори на едно и също свойство може да бъде различна в зависимост от условията на потребление на продукта. Следователно полезността на даден продукт при различни обстоятелства на употребата му е различна.
Вторият етап на работа е изучаване на статистически данни и идентифициране на връзката и взаимодействието на показателите, определяне на значимостта на отделните фактори и причините за промените в общите показатели.
Всички разглеждани показатели са обединени в едно по такъв начин, че резултатът е цялостна оценка на всички анализирани аспекти от дейността на предприятието, като се вземат предвид условията на неговата дейност, като се вземе предвид степента на значимост на отделните показатели за различните видове инвеститори:
Коефициентите на регресия показват интензивността на влиянието на факторите върху показателя за ефективност. Ако се извърши предварителна стандартизация на факторните показатели, тогава b0 е равно на средната стойност на ефективния показател в агрегата. Коефициентите b, b2 ..... bl показват с колко единици нивото на ефективния индикатор се отклонява от средната му стойност, ако стойностите на факторния индикатор се отклоняват от средната стойност на нула с едно стандартно отклонение. По този начин регресионните коефициенти характеризират степента на значимост на отделните фактори за повишаване на нивото на показателя за ефективност. Конкретните стойности на регресионните коефициенти се определят от емпирични данни по метода на най-малките квадрати (в резултат на решаване на системи от нормални уравнения).
2. Изчисляване на значимостта на коефициентите на регресия и корелация с помощта на f-теста на Стюдънт
Нека разгледаме линейната форма на многофакторните връзки не само като най-простата, но и като формата, предоставена от приложните софтуерни пакети за компютри. Ако връзката между отделен фактор и резултантния атрибут не е линейна, тогава уравнението се линеаризира чрез заместване или трансформиране на стойността на факторния атрибут.
Общата форма на многовариантното регресионно уравнение е:
където k е броят на факторните характеристики.
За да се опрости системата от уравнения на най-малките квадрати, необходими за изчисляване на параметрите на уравнение (8.32), обикновено се въвеждат отклоненията на отделните стойности на всички характеристики от средните стойности на тези характеристики.
Получаваме система от k уравнения на най-малките квадрати:

Решавайки тази система, получаваме стойностите на условно чистите коефициенти на регресия b. Свободният член на уравнението се изчислява по формулата
Терминът "условно чист коефициент на регресия" означава, че всяка от стойностите bj измерва общото средно отклонение на получената характеристика от нейната средна стойност, когато даден фактор xj се отклонява от средната си стойност с единица от нейното измерване и при условие, че всички други фактори, включени в регресионното уравнение, фиксирани на средни стойности, не се променят, не варират.
По този начин, за разлика от сдвоения коефициент на регресия, условният чист коефициент на регресия измерва влиянието на даден фактор, абстрахирайки се от връзката на вариацията на този фактор с вариацията на други фактори. Ако беше възможно да се включат в уравнението на регресията всички фактори, влияещи върху вариацията на получената характеристика, тогава стойностите на bj. могат да се считат за мерки за чистото влияние на факторите. Но тъй като наистина е невъзможно да се включат всички фактори в уравнението, тогава коефициентите bj. не е свободен от примеса на влиянието на фактори, които не са включени в уравнението.
Невъзможно е да се включат всички фактори в регресионното уравнение поради една от трите причини или всички наведнъж, тъй като:
1) някои фактори може да са неизвестни на съвременната наука, познаването на всеки процес винаги е непълно;
2) няма информация за някои от известните теоретични фактори или е ненадеждна;
3) размерът на изследваната популация (извадка) е ограничен, което позволява включването на ограничен брой фактори в регресионното уравнение.
Коефициенти на условна чиста регресия bj. са именувани числа, изразени в различни мерни единици и поради това са несравними помежду си. За преобразуването им в съпоставими относителни показатели се използва същата трансформация, както за получаване на коефициента на двойна корелация. Получената стойност се нарича стандартизиран регресионен коефициент или?-коефициент.
Коефициентът на фактора xj определя мярката на влиянието на изменението на фактора xj върху изменението на резултантната характеристика y, като се абстрахира от съпътстващото изменение на други фактори, включени в регресионното уравнение.
Полезно е да се изразят коефициентите на условно чиста регресия под формата на относителни сравними показатели за връзка, коефициенти на еластичност:
Коефициентът на еластичност на фактора xj казва, че когато стойността на даден фактор се отклонява от средната си стойност с 1% и абстрахирайки се от съпътстващото отклонение на други фактори, включени в уравнението, получената характеристика ще се отклонява от средната си стойност с ej процента от г. По-често коефициентите на еластичност се тълкуват и прилагат от гледна точка на динамиката: с увеличаване на фактора x с 1% от средната му стойност, получената характеристика ще се увеличи с е. процент от средната му стойност.
Нека разгледаме изчислението и интерпретацията на многофакторното регресионно уравнение, като използваме същите 16 ферми като пример (Таблица 8.1). Ефективният признак е нивото на брутния доход и три фактора, влияещи върху него, са представени в табл. 8.7.
Нека припомним още веднъж, че за да се получат надеждни и достатъчно точни показатели за корелация е необходима по-голяма съвкупност.
Таблица 8.7
Ниво на брутния доход и неговите фактори
| Номера на ферми |
Брутен доход, rub./ra |
Разходи за труд, човекодни/ха x1 |
дял от обработваема земя, |
Добив на мляко на 1 крава, |
Таблица 8.8 Индикатори на регресионното уравнение
| Зависима променлива: y |
|||||
| Коефициент на регресия |
|||||
| Константа-240.112905 |
|||||
| Std. грешка на прибл. = 79.243276 |
|||||
Решението е извършено с помощта на програмата “Microstat” за компютър. Ето и таблиците от разпечатката: табл. 8.7 дава средните стойности и стандартните отклонения на всички характеристики. Таблица 8.8 съдържа регресионни коефициенти и тяхната вероятностна оценка:
първата колона "var" - променливи, т.е. фактори; втората колона „регресионен коефициент” - условно чисти регресионни коефициенти bj; трета колона „std. errr" - средни грешки в оценките на регресионния коефициент; четвърта колона - стойности на t-теста на Student с 12 степени на свобода на вариация; пета колона “prob” - вероятността на нулевата хипотеза спрямо регресионните коефициенти;
шеста колона “частично r2” - частни коефициенти на детерминация. Съдържанието и методологията за изчисляване на индикаторите в колони 3-6 се обсъждат допълнително в глава 8. „Константа“ е свободният член на регресионното уравнение a; „Std. грешка на est." - средна квадратична грешка при оценката на ефективната характеристика с помощта на регресионното уравнение. Получено е уравнението на множествената регресия:
y = 2,26x1 - 4,31x2 + 0,166x3 - 240.
Това означава, че размерът на брутния доход на 1 хектар земеделска земя средно се е увеличил с 2,26 рубли. с увеличение на разходите за труд с 1 час/дка; намалява средно с 4,31 рубли. с увеличение на дела на обработваемата земя в земеделските земи с 1% и увеличение с 0,166 рубли. с увеличение на млечността на крава с 1 кг. Отрицателната стойност на свободния термин е съвсем естествена и, както вече беше отбелязано в параграф 8.2, ефективният знак е, че брутният доход става нула много преди факторите да достигнат нулеви стойности, което е невъзможно в производството.
Отрицателна стойност на коефициента за х^ е сигнал за значителни затруднения в икономиката на изследваните ферми, където растениевъдството е нерентабилно, а само животновъдството е рентабилно. При рационални методи на земеделие и нормални цени (равновесни или близки до тях) за продуктите от всички сектори доходите не трябва да намаляват, а да се увеличават с увеличаване на най-плодородния дял от земеделската земя - обработваемата земя.
Въз основа на данните от предпоследните два реда на табл. 8.7 и таблица. 8.8 изчисляваме p-коефициентите и коефициентите на еластичност по формули (8.34) и (8.35).
Както вариацията в равнището на дохода, така и евентуалната му промяна в динамиката се влияят най-силно от фактора х3 - продуктивността на кравите, и най-слабо от х2 - дела на обработваемата земя. Стойностите P2/ ще бъдат използвани допълнително (Таблица 8.9);
Таблица 8.9 Сравнително влияние на факторите върху нивото на доходите
| Фактори xj |
|||

И така, получихме, че ?-коефициентът на фактора xj е свързан с коефициента на еластичност на този фактор, както коефициентът на вариация на фактора е свързан с коефициента на вариация на получената характеристика. Тъй като, както се вижда от последния ред на таблицата. 8.7, коефициентите на вариация на всички фактори са по-малки от коефициента на вариация на получената характеристика; всички?-коефициенти са по-малки от коефициентите на еластичност.
Нека разгледаме връзката между сдвоения и условно чистия коефициент на регресия, използвайки фактора -с като пример. Сдвоеното линейно уравнение за връзката между y и x има формата:
y = 3,886x1 – 243,2
Условно чистият регресионен коефициент при x1 е само 58% от двойния. Останалите 42% се дължат на факта, че вариация х1 е придружена от вариация на факторите х2 х3, което от своя страна влияе на резултантния признак. Връзките на всички характеристики и техните двойни регресионни коефициенти са представени в графиката на връзките (фиг. 8.2).

Ако сумираме оценките на прякото и косвеното влияние на вариацията x1 върху y, т.е. произведението на сдвоените регресионни коефициенти по всички „пътеки“ (фиг. 8.2), получаваме: 2,26 + 12,55 0,166 + (-0,00128) (- 4,31) + (-0,00128) 17,00 0,166 = 4,344.
Тази стойност е дори по-голяма от коефициента на свързване на двойката x1 с y. Следователно косвеното влияние на вариацията x1 чрез фактори, които не са включени в уравнението, е обратното, което дава общо:
1 Айвазян С.А., Мхитарян В.С. Приложна статистика и основи на иконометрията. Учебник за ВУЗ. - М.: ЕДИНСТВО, 2008, - 311 с.
2 Джонстън Дж. Иконометрични методи. - М.: Статистика, 1980. – 282s.
3 Dougherty K. Въведение в иконометрията. - М.: INFRA-M, 2004, - 354 с.
4 Драйер Н., Смит Г., Приложен регресионен анализ. - М.: Финанси и статистика, 2006, - 191 с.
5 Магнус Ю.Р., Картишев П.К., Пересецки А.А. Иконометрия. Начален курс.-М .: Дело, 2006, – 259 с.
6 Семинар по иконометрия/Изд. И. И. Елисеева - М.: Финанси и статистика, 2004, - 248 с.
7 Иконометрия/Изд. I. I. Елисеева - М.: Финанси и статистика, 2004, - 541 с.
8 Кремер Н., Путко Б. Иконометрия – М.: ЮНИТИ-ДАНА, 200, – 281 с.
Айвазян С.А., Мхитарян В.С. Приложна статистика и основи на иконометрията. Учебник за ВУЗ. - М.: ЕДИНСТВО, 2008, – стр. 23.
Кремер Н., Путко Б. Иконометрия.- М.: UNITY-DANA, 200, – p.64
Драйер Н., Смит Г., Приложен регресионен анализ. - М .: Финанси и статистика, 2006, - стр. 57.
Семинар по иконометрия/Изд. И. И. Елисеева - М.: Финанси и статистика, 2004 г., - стр. 172.
Корелационният тест на Pearson е метод на параметрична статистика, който ви позволява да определите наличието или отсъствието на линейна връзка между два количествени показателя, както и да оцените неговата близост и статистическа значимост. С други думи, корелационният тест на Pearson ви позволява да определите дали има линейна връзка между промените в стойностите на две променливи. В статистическите изчисления и изводи коефициентът на корелация обикновено се означава като r xyили Rxy.
1. История на развитието на корелационния критерий
Корелационният тест на Pearson е разработен от екип британски учени, ръководени от Карл Пиърсън(1857-1936) през 90-те години на 19 век, за да опрости анализа на ковариацията на две случайни променливи. В допълнение към Карл Пиърсън, хората също са работили върху критерия за корелация на Пиърсън Франсис ЕджуъртИ Рафаел Уелдън.
2. За какво се използва корелационният тест на Pearson?
Корелационният тест на Pearson ви позволява да определите близостта (или силата) на корелацията между два показателя, измерени в количествена скала. Като използвате допълнителни изчисления, можете също да определите колко статистически значима е идентифицираната връзка.
Например, използвайки корелационния критерий на Pearson, можете да отговорите на въпроса дали има връзка между телесната температура и съдържанието на левкоцити в кръвта по време на остри респираторни инфекции, между височината и теглото на пациента, между съдържанието на флуор в питейната вода и заболеваемостта от зъбен кариес сред населението.
3. Условия и ограничения за прилагане на хи-квадрат теста на Pearson
- Сравнимите показатели трябва да се измерват в количествен мащаб(например сърдечна честота, телесна температура, брой бели кръвни клетки на 1 ml кръв, систолично кръвно налягане).
- Използвайки корелационния тест на Pearson, можем само да определим наличие и сила на линейна връзкамежду количествата. Други характеристики на връзката, включително посоката (директна или обратна), естеството на промените (праволинейни или криволинейни), както и наличието на зависимост на една променлива от друга, се определят с помощта на регресионен анализ.
- Броят на сравняваните количества трябва да бъде равен на две. В случай на анализ на връзката на три или повече параметъра, трябва да използвате метода факторен анализ.
- Корелационният тест на Pearson е параметричен, и следователно условието за използването му е нормална дистрибуциясравнявани променливи. Ако е необходимо да се извърши корелационен анализ на показатели, чието разпределение се различава от нормалното, включително тези, измерени по ординална скала, трябва да се използва коефициентът на рангова корелация на Spearman.
- Трябва ясно да се разграничат понятията зависимост и корелация. Зависимостта на величините определя наличието на корелация между тях, но не и обратното.
Например височината на детето зависи от възрастта му, тоест колкото по-голямо е детето, толкова по-високо е то. Ако вземем две деца на различна възраст, тогава с голяма степен на вероятност растежът на по-голямото дете ще бъде по-голям от този на по-малкото. Това явление се нарича пристрастяване, което предполага причинно-следствена връзка между индикаторите. Разбира се, между тях също има корелационна връзка, което означава, че промените в един индикатор са придружени от промени в друг индикатор.
В друга ситуация помислете за връзката между височината на детето и сърдечната честота (HR). Както е известно, и двете стойности пряко зависят от възрастта, така че в повечето случаи децата с по-голяма височина (и следователно по-голяма възраст) ще имат по-ниски стойности на сърдечната честота. Това е, корелационна връзкаще се наблюдава и може да има доста голямо струпване на хора. Ако обаче вземем децата същата възраст, Но различни височини, тогава най-вероятно сърдечната им честота ще се различава незначително и следователно можем да заключим, че независимостПулс от височина.
Горният пример показва колко важно е да се прави разлика между основните понятия в статистиката. комуникацииИ зависимостипоказатели за правене на правилни изводи.
4. Как да изчислим коефициента на корелация на Пиърсън?
Корелационният коефициент на Pearson се изчислява по следната формула:

5. Как да интерпретираме стойността на корелационния коефициент на Pearson?
Стойностите на коефициента на корелация на Pearson се интерпретират въз основа на техните абсолютни стойности. Възможните стойности на коефициента на корелация варират от 0 до ±1. Колкото по-голяма е абсолютната стойност на r xy, толкова по-голяма е близостта на връзката между двете величини. r xy = 0 показва пълна липса на комуникация. r xy = 1 – показва наличието на абсолютна (функционална) връзка. Ако стойността на корелационния критерий на Pearson се окаже по-голяма от 1 или по-малка от -1, в изчисленията е направена грешка.
За да се оцени плътността или силата на корелация, обикновено се използват общоприети критерии, според които абсолютните стойности на r xy< 0.3 свидетельствуют о слабвръзка, r xy стойности от 0,3 до 0,7 - за връзка средно аритметичноплътност, стойности на r xy> 0,7 - o силенкомуникации.
По-точна оценка на силата на корелацията може да се получи, ако използвате Маса Chaddock:
Степен статистическа значимостКоефициентът на корелация r xy се извършва с помощта на t-тест, изчислен по следната формула:
![]()
Получената стойност на t r се сравнява с критичната стойност при определено ниво на значимост и броя на степените на свобода n-2. Ако t r надвишава t crit, тогава се прави заключение за статистическата значимост на идентифицираната корелация.
6. Пример за изчисляване на коефициента на корелация на Pearson
Целта на изследването е да се идентифицира, определи близостта и статистическата значимост на връзката между два количествени показателя: нивото на тестостерон в кръвта (X) и процента на мускулна маса в тялото (Y). Изходните данни за извадка от 5 субекта (n = 5) са обобщени в таблицата.
В научните изследвания често има нужда да се намери връзка между резултата и факторните променливи (добива на реколтата и количеството на валежите, височината и теглото на човек в хомогенни групи по пол и възраст, сърдечна честота и телесна температура и т.н.).
Вторите са признаци, които допринасят за промени в тези, свързани с тях (първият).
Концепцията за корелационен анализ
Има много. Въз основа на горното можем да кажем, че корелационният анализ е метод, използван за тестване на хипотезата за статистическата значимост на две или повече променливи, ако изследователят може да ги измери, но не и да ги промени.
Има и други определения на въпросното понятие. Корелационният анализ е метод на обработка, който включва изследване на коефициентите на корелация между променливите. В този случай коефициентите на корелация между една двойка или много двойки характеристики се сравняват, за да се установят статистически връзки между тях. Корелационният анализ е метод за изследване на статистическата зависимост между случайни величини с незадължително наличие на строг функционален характер, при който динамиката на една случайна величина води до динамиката на математическото очакване на друга.
Концепцията за фалшива корелация
При извършване на корелационен анализ е необходимо да се вземе предвид, че той може да се извърши по отношение на всякакъв набор от характеристики, често абсурдни по отношение един на друг. Понякога те нямат причинно-следствена връзка помежду си.
В този случай те говорят за фалшива корелация.
Проблеми на корелационния анализ
Въз основа на горните определения можем да формулираме следните задачи на описания метод: получаване на информация за една от търсените променливи с помощта на друга; определят близостта на връзката между изследваните променливи.
Корелационният анализ включва определяне на връзката между изследваните характеристики и следователно задачите на корелационния анализ могат да бъдат допълнени със следното:
- идентифициране на факторите, които имат най-голямо влияние върху резултантната характеристика;
- идентифициране на неизследвани досега причини за връзки;
- изграждане на корелационен модел с неговия параметричен анализ;
- изследване на значимостта на комуникационните параметри и тяхната интервална оценка.
Връзка между корелационен анализ и регресия
Методът на корелационния анализ често не се ограничава до намиране на близостта на връзката между изследваните величини. Понякога се допълва от съставянето на регресионни уравнения, които се получават с помощта на едноименния анализ и които представляват описание на корелационната зависимост между получената и факторна (факторна) характеристика (характеристики). Този метод, заедно с разглеждания анализ, представлява метода
Условия за използване на метода
Ефективните фактори зависят от един до няколко фактора. Методът на корелационния анализ може да се използва, ако има голям брой наблюдения за стойността на ефективни и факторни показатели (фактори), докато изследваните фактори трябва да бъдат количествени и отразени в конкретни източници. Първият може да се определи от нормалния закон - в този случай резултатът от корелационния анализ е корелационните коефициенти на Пиърсън или, ако характеристиките не се подчиняват на този закон, се използва коефициентът на рангова корелация на Спирман.

Правила за избор на фактори за корелационен анализ
При прилагането на този метод е необходимо да се определят факторите, които влияят върху показателите за ефективност. Те се избират, като се вземе предвид фактът, че трябва да има причинно-следствени връзки между показателите. В случай на създаване на многофакторен корелационен модел се избират тези, които оказват значително влияние върху резултантния индикатор, като за предпочитане е да не се включват взаимозависими фактори с двоен корелационен коефициент над 0,85 в корелационния модел, както и тези за които връзката с резултантния параметър няма линеен или функционален характер.
Показване на резултатите
Резултатите от корелационния анализ могат да бъдат представени в текстова и графична форма. В първия случай те се представят като коефициент на корелация, във втория - под формата на точкова диаграма.
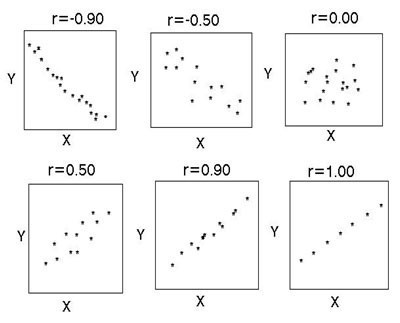
При липса на корелация между параметрите, точките на диаграмата са разположени хаотично, средната степен на връзка се характеризира с по-голяма степен на подреденост и се характеризира с повече или по-малко равномерно разстояние на маркираните знаци от медианата. Силната връзка обикновено е права и при r=1 точковият график е плоска линия. Обратната корелация се различава в посоката на графиката от горния ляв към долния десен, директната корелация - от долния ляв към горния десен ъгъл.
3D представяне на точкова диаграма
В допълнение към традиционния 2D точков график, сега се използва 3D графично представяне на корелационния анализ.

Използва се и матрица на точкова диаграма, която показва всички сдвоени диаграми в една фигура в матричен формат. За n променливи матрицата съдържа n реда и n колони. Диаграмата, разположена в пресечната точка на i-тия ред и j-тата колона, е диаграма на променливите Xi спрямо Xj. По този начин всеки ред и колона е едно измерение, една клетка показва диаграма на разсейване на две измерения.

Оценка на плътността на връзката
Тясността на корелационната връзка се определя от коефициента на корелация (r): силна - r = ±0,7 до ±1, средна - r = ±0,3 до ±0,699, слаба - r = 0 до ±0,299. Тази класификация не е строга. Фигурата показва малко по-различна диаграма.

Пример за използване на метода на корелационния анализ
Във Великобритания е направено интересно проучване. То е посветено на връзката между тютюнопушенето и рака на белия дроб и е извършено чрез корелационен анализ. Това наблюдение е представено по-долу.
Професионална група | смъртност |
|
Фермери, лесовъди и рибари | ||
Миньори и работници в кариерата | ||
Производители на газ, кокс и химикали | ||
Производители на стъкло и керамика | ||
Работници в пещи, ковачници, леярни и валцови цехове | ||
Работници по електротехника и електроника | ||
Инженерни и сродни професии | ||
Дървообработваща промишленост | ||
Кожарски майстори | ||
Текстилни работници | ||
Производители на работно облекло | ||
Работници в хранително-вкусовата, питейната и тютюневата промишленост | ||
Производители на хартия и печат | ||
Производители на други продукти | ||
Строители | ||
Бояджии и декоратори | ||
Машинисти на стационарни двигатели, кранове и др. | ||
Работници, които не са включени другаде | ||
Транспортни и комуникационни работници | ||
Складови работници, склададжии, опаковчици и работници на пълначни машини | ||
Офис работници | ||
Продавачи | ||
Работници в областта на спорта и отдиха | ||
Администратори и управители | ||
Професионалисти, техници и художници |
Започваме корелационен анализ. За по-голяма яснота е по-добре да започнем решението с графичен метод, за който ще изградим диаграма на разсейване.

Демонстрира пряка връзка. Трудно е обаче да се направи недвусмислено заключение само на базата на графичния метод. Затова ще продължим да извършваме корелационен анализ. Пример за изчисляване на коефициента на корелация е представен по-долу.
Използвайки софтуер (MS Excel ще бъде описан по-долу като пример), определяме коефициента на корелация, който е 0,716, което означава силна връзка между изследваните параметри. Нека определим статистическата надеждност на получената стойност, използвайки съответната таблица, за която трябва да извадим 2 от 25 двойки стойности, в резултат получаваме 23 и използвайки този ред в таблицата, намираме r критично за p = 0,01 (тъй като това са медицински данни, по-строга зависимост, в други случаи p=0,05 е достатъчно), което е 0,51 за този корелационен анализ. Примерът показа, че изчисленото r е по-голямо от критичното r и стойността на корелационния коефициент се счита за статистически надеждна.
Използване на софтуер при извършване на корелационен анализ
Описаният тип статистическа обработка на данни може да се извърши с помощта на софтуер, по-специално MS Excel. Корелацията включва изчисляване на следните параметри с помощта на функции:
1. Коефициентът на корелация се определя с помощта на функцията CORREL (масив1; масив2). Array1,2 - клетка от интервала от стойности на резултантните и факторните променливи.
Коефициентът на линейна корелация се нарича още коефициент на корелация на Pearson и следователно, започвайки с Excel 2007, можете да използвате функцията със същите масиви.
Графичното показване на корелационния анализ в Excel се извършва с помощта на панела „Диаграми“ с избора „Диаграма на разсейване“.
След като посочим първоначалните данни, получаваме графика.
2. Оценяване на значимостта на коефициента на двойна корелация с помощта на t-теста на Стюдънт. Изчислената стойност на t-критерия се сравнява с табличната (критична) стойност на този показател от съответната таблица със стойности на разглеждания параметър, като се вземат предвид определеното ниво на значимост и броя на степените на свобода. Тази оценка се извършва с помощта на функцията STUDISCOVER(вероятност; степени_на_свобода).
3. Матрица от двойни корелационни коефициенти. Анализът се извършва с помощта на инструмента Data Analysis, в който е избрана Correlation. Статистическата оценка на коефициентите на двойна корелация се извършва чрез сравняване на абсолютната му стойност с табличната (критична) стойност. Когато изчисленият коефициент на двойна корелация надвиши критичния, можем да кажем, като вземем предвид дадената степен на вероятност, че нулевата хипотеза за значимостта на линейната зависимост не се отхвърля.
Накрая
Използването на метода на корелационния анализ в научните изследвания ни позволява да определим връзката между различни фактори и показатели за ефективност. Необходимо е да се има предвид, че висок коефициент на корелация може да се получи от абсурдна двойка или набор от данни и следователно този тип анализ трябва да се извърши върху достатъчно голям масив от данни.
След получаване на изчислената стойност на r е препоръчително да я сравните с критичното r, за да потвърдите статистическата надеждност на определена стойност. Корелационният анализ може да се извърши ръчно с помощта на формули или с помощта на софтуер, по-специално MS Excel. Тук можете също да изградите диаграма на разсейване с цел визуално представяне на връзката между изследваните фактори на корелационния анализ и получената характеристика.
Както многократно е отбелязвано, за да се направи статистическо заключение за наличието или отсъствието на корелация между изследваните променливи, е необходимо да се провери значимостта на извадковия коефициент на корелация. Поради факта, че надеждността на статистическите характеристики, включително коефициента на корелация, зависи от размера на извадката, може да възникне ситуация, когато стойността на коефициента на корелация се определя изцяло от случайни колебания в извадката, въз основа на които се изчислява . Ако има значителна връзка между променливите, коефициентът на корелация трябва да бъде значително различен от нула. Ако няма корелация между изследваните променливи, тогава коефициентът на съвкупност ρ е равен на нула. В практическите изследвания, като правило, те се основават на извадкови наблюдения. Като всяка статистическа характеристика, коефициентът на корелация на извадката е случайна променлива, т.е. нейните стойности са произволно разпръснати около параметъра на популацията със същото име (истинската стойност на коефициента на корелация). При липса на корелация между променливите y и xкоефициентът на корелация в популацията е нула. Но поради случайния характер на разсейването, принципно са възможни ситуации, когато някои коефициенти на корелация, изчислени от проби от тази популация, ще бъдат различни от нула.
Могат ли наблюдаваните разлики да се припишат на случайни колебания в извадката или отразяват значителна промяна в условията, при които са формирани връзките между променливите? Ако стойностите на коефициента на корелация на извадката попадат в зоната на разсейване поради случайния характер на самия индикатор, това не е доказателство за липсата на връзка. Най-много, което може да се каже е, че данните от наблюденията не отричат липсата на връзка между променливите. Но ако стойността на коефициента на корелация на извадката е извън споменатата зона на разсейване, тогава те заключават, че тя е значително различна от нула и можем да приемем, че между променливите y и xима статистически значима връзка. Критерият, използван за решаване на този проблем, базиран на разпределението на различни статистики, се нарича критерий за значимост.
Процедурата за тестване на значимостта започва с формулирането на нулевата хипотеза з0 . Най-общо казано, няма значителни разлики между параметъра на извадката и параметъра на популацията. Алтернативна хипотеза з1 е, че има значителни разлики между тези параметри. Например, когато се тества за корелация в популация, нулевата хипотеза е, че истинският коефициент на корелация е нула ( H0: ρ = 0). Ако в резултат на теста се окаже, че нулевата хипотеза не е приемлива, тогава коефициентът на корелация на извадката rЕхазначително различна от нула (нулевата хипотеза се отхвърля и алтернативата се приема). H1).С други думи, предположението, че случайните променливи в популацията не са корелирани, трябва да се счита за неоснователно. Обратно, ако въз основа на теста за значимост се приеме нулевата хипотеза, т.е. rЕхалежи в допустимата зона на произволно разсейване, тогава няма причина да се счита допускането за некорелирани променливи в популацията за съмнително.
При тест за значимост изследователят определя ниво на значимост α, което осигурява известна практическа увереност, че грешни заключения ще бъдат направени само в много редки случаи. Нивото на значимост изразява вероятността нулевата хипотеза H0отхвърлено, когато всъщност е вярно. Ясно е, че има смисъл тази вероятност да бъде възможно най-малка.
Нека е известно разпределението на характеристиката на извадката, което е безпристрастна оценка на параметъра на популацията. Избраното ниво на значимост α съответства на защрихованите зони под кривата на това разпределение (виж фиг. 24). Незащрихованата област под кривата на разпределение определя вероятността P = 1 - α . Границите на сегментите по оста x под защрихованите области се наричат критични стойности, а самите сегменти образуват критичната област или областта на отхвърляне на хипотезата.
В процедурата за проверка на хипотезата характеристиката на извадката, изчислена от резултатите от наблюденията, се сравнява със съответната критична стойност. В този случай трябва да се прави разлика между едностранни и двустранни критични зони. Формата на определяне на критичната област зависи от формулирането на проблема в статистическото изследване. Двустранен критичен регион е необходим, когато при сравняване на параметър на извадката и параметър на популацията е необходимо да се оцени абсолютната стойност на несъответствието между тях, т.е. както положителните, така и отрицателните разлики между изследваните стойности са на интерес. Когато е необходимо да се гарантира, че една стойност е средно строго по-голяма или по-малка от друга, се използва едностранна критична област (дясна или лява). Съвсем очевидно е, че за една и съща критична стойност нивото на значимост при използване на едностранен критичен регион е по-малко, отколкото при използване на двустранен. Ако разпределението на характеристиката на извадката е симетрично,
Ориз. 24. Тестване на нулевата хипотеза H0
тогава нивото на значимост на двустранната критична област е равно на α, а на едностранната - (виж фиг. 24). Нека се ограничим до общата постановка на проблема. По-подробна информация за теоретичните основи за проверка на статистически хипотези може да се намери в специализираната литература. По-долу ще посочим само критериите за значимост на различните процедури, без да се спираме на тяхното изграждане.
Чрез проверка на значимостта на коефициента на двойна корелация се установява наличието или липсата на корелация между изследваните явления. При липса на връзка коефициентът на корелация на населението е нула (ρ = 0). Процедурата на тестване започва с формулирането на нулевата и алтернативната хипотеза:
H0: разлика между коефициента на корелация на извадката r и ρ = 0 е незначително,
H1: разлика между rи ρ = 0 е значимо и следователно между променливите приИ хима значителна връзка. Алтернативната хипотеза предполага, че трябва да използваме двустранен критичен регион.
Вече беше споменато в раздел 8.1, че коефициентът на корелация на извадката, при определени предположения, е свързан със случайна променлива T, подчинявайки се на студентското разпределение с f = n- 2 степени на свобода. Статистика, изчислена от резултати от проби
се сравнява с критичната стойност, определена от таблицата за разпределение на Стюдънт при дадено ниво на значимост α Иf = n- 2 степени на свобода. Правилото за прилагане на критерия е следното: ако | T| >tf,А, тогава нулевата хипотеза при ниво на значимост α отхвърлено, т.е. връзката между променливите е значима; ако | T| ≤tf,А, тогава нулевата хипотеза при ниво на значимост α се приема. Отклонение на стойността r от ρ = 0 може да се припише на случайна вариация. Примерните данни характеризират разглежданата хипотеза като много възможна и правдоподобна, т.е. хипотезата за липса на връзка не предизвиква възражения.
Процедурата за тестване на хипотеза е значително опростена, ако вместо статистика Tизползвайте критичните стойности на коефициента на корелация, които могат да бъдат определени чрез квантилите на разпределението на Стюдънт чрез заместване в (8.38) T= tf, а и r= ρ f, A:
![]() (8.39)
(8.39)
Има подробни таблици с критични стойности, извадка от които е дадена в приложението към тази книга (виж Таблица 6). Правилото за проверка на хипотезата в този случай се свежда до следното: ако r> ρ f, и тогава можем да твърдим, че връзката между променливите е значима. Ако r≤rf,А, тогава считаме, че резултатите от наблюдението са в съответствие с хипотезата за липса на връзка.
;  ;
;  .
.
Сега нека изчислим стойностите на примерните стандартни отклонения:
https://pandia.ru/text/78/148/images/image443_0.gif" width="413" height="60 src=">.
Корелацията между нивото https://pandia.ru/text/78/148/images/image434_0.gif" width="25" height="24"> сред десетокласниците, колкото по-високо е средното ниво на представяне по математика, и обратно.
2. Проверка на значимостта на корелационния коефициент
Тъй като коефициентът на извадката се изчислява от извадкови данни, той е случайна променлива . Ако , тогава възниква въпросът: това обяснява ли се с наистина съществуваща линейна връзка между и https://pandia.ru/text/78/148/images/image301_1.gif" width="29" height="25 src=" >.gif" width="27" height="25">: (ако знакът за корелация не е известен); или едностранно https://pandia.ru/text/78/148/images/image448_0.gif" width="43" height="23 src=">.gif" width="43" height="23 src =" > (ако знакът на корелацията може да бъде определен предварително).
Метод 1.За проверка на хипотезата се използва https://pandia.ru/text/78/148/images/image150_1.gif" width="11" height="17 src=">-t-тест на Стюдънт по формулата
https://pandia.ru/text/78/148/images/image406_0.gif" width="13" height="15">.gif" width="36 height=25" height="25">.gif " width="17" height="16"> и броя на степените на свобода за двустранния критерий.
Критичната област е дадена от неравенството ![]() .
.
Ако https://pandia.ru/text/78/148/images/image455_0.gif" width="99" height="29 src=">, тогава нулевата хипотеза се отхвърля. Правим изводи:
§ за двустранна алтернативна хипотеза – коефициентът на корелация е значително различен от нула;
§ за едностранна хипотеза – има статистически значима положителна (или отрицателна) корелация.
Метод 2.Можете също да използвате таблица с критични стойности на коефициента на корелация, от което намираме стойността на критичната стойност на коефициента на корелация по броя на степените на свобода https://pandia.ru/text/78/148/images/image367_1.gif" width="17 height=16" височина="16">.
Ако https://pandia.ru/text/78/148/images/image459_0.gif" width="101" height="29 src=">, тогава се заключава, че коефициентът на корелация е значително различен от 0 и има статистически значима корелация.
По този начин някои явления могат да се появят или променят едновременно, но независимо едно от друго (съвместни събития) ( невярнорегресия). Други - да са в причинно-следствена връзка не помежду си, а според по-сложна причинно-следствена връзка ( непрякрегресия). По този начин, със значителен коефициент на корелация, окончателното заключение за наличието на причинно-следствена връзка може да се направи само като се вземат предвид спецификите на изследвания проблем.
Пример 2.Определете значимостта на извадковия корелационен коефициент, изчислен в пример 1.
Решение.
Нека изложим една хипотеза: че няма корелация в общата съвкупност. Тъй като знакът на корелацията в резултат на решаването на пример 1 е определен - корелацията е положителна, алтернативната хипотеза е едностранна от формата https://pandia.ru/text/78/148/images/image448_0.gif " width="43" height="23 src =>>.
Нека намерим емпиричната стойност на критерия:
https://pandia.ru/text/78/148/images/image461_0.gif" width="167 height=20" height="20"> изберете нивото на значимост, равно на . Според таблицата „Критични стойности на теста на Стюдънт за различни нива на значимост” намираме критичната стойност.
Тъй като https://pandia.ru/text/78/148/images/image434_0.gif" width="25 height=24" height="24"> и средното ниво на представяне по математика, има статистически значима корелация .
Тестови задачи
1. Моля, отбележете поне два верни отговора. Тестването на значимостта на примерния коефициент на корелация се основава на статистически тест на хипотезата, че...
1) няма корелация в общата съвкупност
2) разликата от нула на коефициента на корелация на извадката се обяснява само със случайността на извадката
3) коефициентът на корелация е значително различен от 0
4) разликата от нула на извадковия коефициент на корелация не е случайна
2. Ако примерният коефициент на линейна корелация е , тогава по-голяма стойност на една характеристика съответства на... по-голяма стойност на друга характеристика.
1) средно
3) в повечето наблюдения
4) от време на време
3. Коефициент на корелация на извадката https://pandia.ru/text/78/148/images/image465_0.gif" width="64" height="23 src="> (за размер на извадката и ниво на значимост 0,05). Възможно ли е да кажем, че има статистически значима положителна корелация между психологическите черти?
5. Нека примерният коефициент на корелация се намира в задачата за идентифициране на силата на линейна връзка между психологически характеристики https://pandia.ru/text/78/148/images/image466_0.gif" width="52 height=20 " height="20"> и ниво на значимост 0,05). Можем ли да кажем, че разликата от нула на корелационния коефициент на извадката се обяснява само със случайността на извадката?
Тема 3. коефициенти на рангова корелация и асоциации
1. Ранг коефициент на корелация https://pandia.ru/text/78/148/images/image130_3.gif" width="21 height=19" height="19"> и. Броят на стойностите на характеристиките (показатели, предмети, качества , черти) могат да бъдат всякакви, но техният брой трябва да бъде еднакъв.
Предмети | ||||
Класове по черти | ||||
Класове по черти |
Нека обозначим разликата между ранговете за две променливи за всеки предмет с помощта на https://pandia.ru/text/78/148/images/image470_0.gif" width="319" height="66">,
където е броят на стойностите на класираните характеристики и индикатори.
Коефициентът на рангова корелация приема стойности от –1 до +1и се разглежда като средство за бързо оценяване на коефициента на корелация на Пиърсън.
За тестване на значимостта на коефициента на рангова корелация на Spearman (ако броят на стойностите https://pandia.ru/text/78/148/images/image472_0.gif" width="55" height="29"> зависи от броя и нивото на значимост. Ако емпиричната стойност е по-голяма, тогава при нивото на значимост може да се твърди, че знаците са свързани чрез корелация.
Пример 1.Психологът открива как са свързани резултатите от представянето на учениците по математика и физика, резултатите от които са представени под формата на класирана серия по фамилия.
Студент | Сума |
||||||||||
Академично представяне математика | |||||||||||
Академично представяне по физика | |||||||||||
Разлика на квадрат между ранговете |
Нека изчислим сумата, тогава коефициентът на рангова корелация на Спирман е равен на:
Да проверим значимостта на намерения коефициент на рангова корелация. Нека намерим критичните стойности на коефициента на корелация на ранга на Spearman, като използваме таблицата (вижте Приложенията) за:
https://pandia.ru/text/78/148/images/image480_0.gif" width="72" height="25"> е по-голямо от стойността = 0,64 и стойността 0,79. Това показва, че стойността попада в зоната на значимост на коефициента на корелация, Следователно може да се твърди, че коефициентът на корелация на ранга на Спирман е значително различен от 0; това означава, че резултатите от представянето на учениците по математика и физика са свързани с положителна корелация . Съществува значителна положителна корелация между представянето по математика и представянето по физика: колкото по-добри са постиженията по математика, толкова по-добри са средните резултати по физика и обратно.
Сравнявайки коефициентите на корелация на Пиърсън и Спирман, отбелязваме, че коефициентът на корелация на Пиърсън корелира стойностите количества, а коефициентът на корелация на Спирман е стойностите редицитези количества, следователно стойностите на коефициентите на Pearson и Spearman често не съвпадат.
За по-пълно разбиране на експерименталния материал, получен в психологическите изследвания, е препоръчително да се изчислят коефициенти както по Pearson, така и по Spearman.
Коментирайте. В присъствието на равни чиновев серията от рангове и в числителя на формулата за изчисляване на коефициента на рангова корелация се добавят термини - „корекции за ранговете“:  ;
;  ,
,
където https://pandia.ru/text/78/148/images/image130_3.gif" width="21" height="19">;
https://pandia.ru/text/78/148/images/image165_1.gif" width="16" height="19">.
В този случай формулата за изчисляване на коефициента на рангова корелация приема формата https://pandia.ru/text/78/148/images/image485_0.gif" width="16" height="19">.
Условия за прилагане на коефициента на асоцииране.
1. Характеристиките, които се сравняват, се измерват в дихотомна скала.
2..gif" width="21" height="19">, обозначени със символите 0 и 1, са показани в таблицата.
Номер на наблюдение |
