Равномерно произволно разпределение. Преобразуване на равномерно разпределена случайна променлива в нормално разпределена
Като пример за непрекъсната случайна променлива, разгледайте случайна променлива X, равномерно разпределена в интервала (a; b). Казваме, че случайната променлива X равномерно разпределен на интервала (a; b), ако неговата плътност на разпределение не е постоянна на този интервал:
От условието за нормализиране определяме стойността на константата c . Площта под кривата на плътността на разпределението трябва да е равна на единица, но в нашия случай това е площта на правоъгълник с основа (b - α) и височина c (фиг. 1). 
Ориз. 1 Равномерна плътност на разпределение
От тук намираме стойността на константата c: ![]()
И така, плътността на една равномерно разпределена случайна променлива е равна на 
Нека сега намерим функцията на разпределение по формулата:
1) за ![]()
2) за
3) за 0+1+0=1.
По този начин, 
Функцията на разпределение е непрекъсната и не намалява (фиг. 2). 
Ориз. 2 Функция на разпределение на равномерно разпределена случайна променлива
Да намерим математическо очакване на равномерно разпределена случайна променливапо формулата:
Дисперсия на равномерното разпределениесе изчислява по формулата и е равно на
Пример #1. Делението на скалата на измервателния уред е 0,2. Показанията на инструмента се закръглят до най-близкото цяло деление. Намерете вероятността при отчитането да бъде допусната грешка: а) по-малка от 0,04; б) голям 0,02
Решение. Грешката при закръгляване е случайна променлива, равномерно разпределена в интервала между съседни целочислени деления. Разгледайте интервала (0; 0,2) като такова разделение (фиг. а). Закръгляването може да се извърши както към лявата граница - 0, така и към дясната - 0,2, което означава, че може да се направи грешка по-малка или равна на 0,04 два пъти, което трябва да се вземе предвид при изчисляване на вероятността: 

Р = 0,2 + 0,2 = 0,4
За втория случай стойността на грешката може също да надвишава 0,02 на двете граници на разделяне, тоест може да бъде по-голяма от 0,02 или по-малка от 0,18. 
Тогава вероятността от грешка като тази:
Пример #2. Предполага се, че стабилността на икономическата ситуация в страната (липса на войни, природни бедствия и т.н.) през последните 50 години може да се съди по естеството на разпределението на населението по възраст: в спокойна ситуация, трябва да бъде униформа. В резултат на изследването са получени следните данни за една от страните.
Има ли причина да се смята, че в страната е имало нестабилна ситуация?Ние вземаме решение с помощта на калкулатора Тестване на хипотези. Таблица за изчисляване на показатели.
| Групи | Среден интервал, x i | Количество, фи | x i * f i | Кумулативна честота, S | |x - x cf |*f | (x - x sr) 2 *f | Честота, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
среднопретеглена стойност
Вариационни индикатори.
Абсолютни нива на вариация.
Диапазонът на вариация е разликата между максималните и минималните стойности на атрибута на първичната серия.
R = X max - X min
R=70 - 0=70
дисперсия- характеризира мярката за разпространение около нейната средна стойност (мярка за дисперсия, т.е. отклонение от средната стойност).
Стандартно отклонение.
Всяка стойност от серията се различава от средната стойност от 43 с не повече от 23,92
Тестване на хипотези за вида на разпределението.
4. Проверка на хипотезата за равномерно разпределениеобщото население.
За да се провери хипотезата за равномерното разпределение на X, т.е. според закона: f(x) = 1/(b-a) в интервала (a,b)
необходимо:
1. Оценете параметрите a и b - краищата на интервала, в който са наблюдавани възможните стойности на X, съгласно формулите (знакът * означава оценките на параметрите):
2. Намерете плътността на вероятността на изчисленото разпределение f(x) = 1/(b * - a *)
3. Намерете теоретичните честоти:
n 1 \u003d nP 1 \u003d n \u003d n * 1 / (b * - a *) * (x 1 - a *)
n 2 \u003d n 3 \u003d ... \u003d n s-1 \u003d n * 1 / (b * - a *) * (x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Сравнете емпиричните и теоретичните честоти, като използвате теста на Pearson, като приемете броя на степените на свобода k = s-3, където s е броят на началните интервали на вземане на проби; ако обаче е направена комбинация от малки честоти и следователно самите интервали, тогава s е броят на интервалите, оставащи след комбинацията.
Решение:
1. Намерете оценките на параметрите a * и b * на равномерното разпределение, като използвате формулите:
2. Намерете плътността на предполагаемото равномерно разпределение:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Намерете теоретичните честоти:
n 1 \u003d n * f (x) (x 1 - a *) \u003d 1 * 0,0121 (10-1,58) \u003d 0,1
n 8 \u003d n * f (x) (b * - x 7) \u003d 1 * 0,0121 (84,42-70) \u003d 0,17
Останалите n s ще бъдат равни:
n s = n*f(x)(x i - x i-1)
| аз | n i | n*i | n i - n * i | (n i - n* i) 2 | (n i - n * i) 2 /n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Обща сума | 1 | 0.0532 |
Следователно критичната област за тази статистика е винаги дясна: ако нейната плътност на вероятността е постоянна в този сегмент, а извън нея е 0 (т.е. случайна променлива хфокусиран върху сегмента [ а, b], върху която има постоянна плътност). Съгласно тази дефиниция, плътността на равномерно разпределена върху сегмента [ а, b] случайна величина хизглежда като:
Където сима някакъв номер. Въпреки това е лесно да го намерите, като използвате свойството за плътност на вероятността за r.v., концентрирано върху сегмента [ а,
b]:
 . Оттук следва, че
. Оттук следва, че  , където
, където  . Следователно плътността, равномерно разпределена върху сегмента [ а,
b] случайна величина хизглежда като:
. Следователно плътността, равномерно разпределена върху сегмента [ а,
b] случайна величина хизглежда като:
 .
.
За да се съди за равномерността на разпределението на н.с.в. хвъзможно от следното съображение. Непрекъсната случайна променлива има равномерно разпределение на интервала [ а, b] ако приема стойности само от този сегмент и нито едно число от този сегмент няма предимство пред другите числа от този сегмент в смисъл, че може да бъде стойността на тази случайна променлива.
Случайните променливи с равномерно разпределение включват такива променливи като времето за изчакване на транспорта при спиране (при постоянен интервал на движение времето за изчакване е равномерно разпределено в този интервал), грешката на закръгляване на числото до цяло число (равномерно разпределено на [−0,5 , 0.5 ]) и други.
Тип функция на разпределение Е(х)
а,
b] случайна величина хсе търси чрез известната плътност на вероятността f(х)
използвайки формулата на тяхната връзка  . В резултат на съответните изчисления получаваме следната формула за функцията на разпределение Е(х)
равномерно разпределен сегмент [ а,
b] случайна величина х
:
. В резултат на съответните изчисления получаваме следната формула за функцията на разпределение Е(х)
равномерно разпределен сегмент [ а,
b] случайна величина х
:
 .
.
Фигурите показват графики на плътността на вероятността f(х) и разпределителни функции f(х) равномерно разпределен сегмент [ а, b] случайна величина х :


Математическо очакване, дисперсия, стандартно отклонение, мода и медиана на равномерно разпределен сегмент [ а, b] случайна величина хизчислено от плътността на вероятността f(х) по обичайния начин (и съвсем просто поради простия външен вид f(х) ). Резултатът е следните формули:
но мода д(х) е произволно число от интервала [ а, b].
Нека намерим вероятността да уцелим равномерно разпределения сегмент [ а,
b] случайна величина хв интервала  , напълно легнал вътре [ а,
b]. Като вземем предвид известната форма на функцията на разпределение, получаваме:
, напълно легнал вътре [ а,
b]. Като вземем предвид известната форма на функцията на разпределение, получаваме:
По този начин вероятността за попадение в равномерно разпределения сегмент [ а,
b] случайна величина хв интервала  , напълно легнал вътре [ а,
b], не зависи от позицията на този интервал, а зависи само от неговата дължина и е право пропорционална на тази дължина.
, напълно легнал вътре [ а,
b], не зависи от позицията на този интервал, а зависи само от неговата дължина и е право пропорционална на тази дължина.
Пример. Интервалът на автобусите е 10 минути. Каква е вероятността пътник, пристигащ на автобусна спирка, да чака автобуса по-малко от 3 минути? Какво е средното време за чакане на автобус?
Нормална дистрибуция
Това разпределение най-често се среща в практиката и играе изключителна роля в теорията на вероятностите и математическата статистика и техните приложения, тъй като толкова много случайни променливи в природните науки, икономиката, психологията, социологията, военните науки и т.н. имат такова разпределение. Това разпределение е ограничаващият закон, към който се доближават (при определени природни условия) много други закони на разпределение. С помощта на нормалния закон за разпределение се описват и явления, които са подчинени на действието на множество независими случайни фактори от всякакво естество и всеки закон на тяхното разпределение. Нека да преминем към определенията.
Непрекъсната случайна променлива се нарича разпределена нормален закон (или закон на Гаус), ако нейната плътност на вероятността има формата:
 ,
,
къде са числата АИ σ (σ>0 ) са параметрите на това разпределение.
Както вече беше споменато, законът на Гаус за разпределение на случайни променливи има множество приложения. Според този закон се разпределят грешките на измерване с инструменти, отклонението от центъра на целта по време на стрелба, размерите на произведените части, теглото и височината на хората, годишните валежи, броят на новородените и много други.
Горната формула за плътността на вероятността на нормално разпределена случайна променлива съдържа, както беше казано, два параметъра АИ σ , и следователно дефинира семейство от функции, които варират в зависимост от стойностите на тези параметри. Ако приложим обичайните методи за математически анализ на изследването на функциите и чертането на вероятностната плътност на нормално разпределение, можем да направим следните заключения.

са неговите инфлексни точки.
Въз основа на получената информация изграждаме графика на плътността на вероятността f(х) нормално разпределение (нарича се крива на Гаус - фигура).

Нека да разберем как се отразява промяната на параметрите АИ σ върху формата на кривата на Гаус. Очевидно е (това се вижда от формулата за плътност на нормалното разпределение), че изменението на параметъра Ане променя формата на кривата, а води само до изместването й надясно или наляво по оста х. Зависимост σ по-трудно. От горното изследване може да се види как стойността на максимума и координатите на точките на инфлексия зависят от параметъра σ . Освен това трябва да се има предвид, че за всякакви параметри АИ σ площта под кривата на Гаус остава равна на 1 (това е общо свойство на плътността на вероятностите). От казаното следва, че с увеличаване на параметъра σ кривата става по-плоска и се разтяга по оста х. Фигурата показва кривите на Гаус за различни стойности на параметъра σ (σ 1 < σ< σ 2 ) и същата стойност на параметъра А.

Разберете вероятностното значение на параметрите АИ σ
нормална дистрибуция. Още от симетрията на кривата на Гаус по отношение на вертикалната линия, минаваща през числото Ана ос хясно е, че средната стойност (т.е. математическото очакване M(X)) на нормално разпределена случайна променлива е равно на А. По същите причини модата и медианата също трябва да са равни на числото a. Точните изчисления по съответните формули потвърждават това. Ако напишем горния израз за f(х)
заместител във формулата за дисперсията  , тогава след (доста трудното) изчисляване на интеграла, получаваме в отговора числото σ
2
. По този начин, за случайна променлива хразпределени по нормалния закон, се получават следните основни числени характеристики:
, тогава след (доста трудното) изчисляване на интеграла, получаваме в отговора числото σ
2
. По този начин, за случайна променлива хразпределени по нормалния закон, се получават следните основни числени характеристики:
Следователно вероятностното значение на параметрите на нормалното разпределение АИ σ следващия. Ако р.в. хАИ σ А σ.
Нека сега намерим функцията на разпределение Е(х)
за случайна променлива х, разпределени според нормалния закон, използвайки горния израз за плътността на вероятността f(х)
и формула  . При заместване f(х)
получаваме "невзет" интеграл. Всичко, което може да се направи, за да се опрости изразът за Е(х),
това е представянето на тази функция във формата:
. При заместване f(х)
получаваме "невзет" интеграл. Всичко, което може да се направи, за да се опрости изразът за Е(х),
това е представянето на тази функция във формата:
 ,
,
Където F(x)- така нареченият Функция на Лаплас, което изглежда като
 .
.
Интегралът, чрез който се изразява функцията на Лаплас, също не е взет (но за всеки хтози интеграл може да се изчисли приблизително с произволна предварително определена точност). Не е необходимо обаче да го изчислявате, тъй като в края на всеки учебник по теория на вероятностите има таблица за определяне на стойностите на функцията F(x)при дадена стойност х. В това, което следва, ще ни трябва свойството странност на функцията на Лаплас: F(−x)=−F(x)за всички номера х.
Нека сега намерим вероятността нормално разпределен r.v. хще вземе стойност от дадения числов интервал (α, β) . От общите свойства на функцията на разпределение Р(α< х< β)= Е(β) − Е(α) . Заместване α И β в горния израз за Е(х) , получаваме
 .
.
Както бе споменато по-горе, ако r.v. хразпределени нормално с параметри АИ σ , тогава средната му стойност е равна на А, а стандартното отклонение е равно на σ. Ето защо средно аритметичноотклонение на стойностите на това r.v. при тестване от броя Аравно на σ. Но това е средното отклонение. Следователно са възможни и по-големи отклонения. Откриваме колко са възможни тези или онези отклонения от средната стойност. Нека намерим вероятността стойността на случайна променлива да се разпредели според нормалния закон хсе отклоняват от средната си стойност M(X)=aпо-малко от някакво число δ, т.е. Р(| х− а|<δ ) : . По този начин,
 .
.
Замествайки в това равенство δ=3σ, получаваме вероятността стойността на r.v. х(в едно изпитване) ще се отклони от средната стойност с по-малко от три пъти σ (със средно отклонение, както си спомняме, равно на σ ): (което означава F(3)взети от таблицата със стойности на функцията на Лаплас). Почти е 1 ! Тогава вероятността от обратното събитие (че стойността се отклонява най-малко с 3σ) е равно на 1 −0.997=0.003 , което е много близо до 0 . Следователно това събитие е "почти невъзможно" − се случва много рядко (средно 3 изтече 1000 ). Това разсъждение е обосновката на добре известното „правило на трите сигми“.
Правилото на трите сигми. Нормално разпределена случайна променлива в един тестна практика не се отклонява от средното си повече от 3σ.
Още веднъж подчертаваме, че говорим за един тест. Ако има много изпитания на случайна променлива, тогава е напълно възможно някои от нейните стойности да се преместят по-далеч от средната от 3σ. Това потвърждава следното
Пример. Каква е вероятността след 100 опита на нормално разпределена случайна променлива хпоне една от неговите стойности ще се отклонява от средната с повече от три пъти стандартното отклонение? Какво ще кажете за 1000 опита?
Решение. Нека събитието Аозначава, че при тестване на случайна променлива хстойността му се отклонява от средната с повече от 3σ.Както току-що стана ясно, вероятността от това събитие p=P(A)=0.003.Извършени са 100 такива теста. Трябва да намерим вероятността събитието Асе случи понепъти, т.е. дойде от 1 преди 100 веднъж. Това е типична задача на схемата на Бернули с параметри н=100 (брой независими опити), р=0,003(вероятност за събитие Ав един тест) р=1− стр=0.997 . Исках да намеря Р 100 (1≤ к≤100) . В този случай, разбира се, е по-лесно първо да се намери вероятността за обратното събитие Р 100 (0) − вероятността събитието Аникога не се е случвало (т.е. случило се е 0 пъти). Отчитайки връзката между вероятностите на самото събитие и неговата противоположност, получаваме:
Не толкова малко. Може и да се случи (среща се средно във всяка четвърта такава серия от тестове). При 1000 тестове по същата схема, може да се получи, че вероятността за поне едно отклонение е по-голяма от 3σ, равно на: . Така че е безопасно да изчакате поне едно такова отклонение.
Пример. Височината на мъжете от определена възрастова група обикновено се разпределя с математическо очакване аи стандартно отклонение σ . Каква пропорция на костюмите к-тият прираст трябва да бъде включен в общото производство за дадена възрастова група, ако к-тият растеж се определя от следните граници:
1 височина : 158 − 164 см 2височина : 164 - 170 см 3височина : 170 - 176 см 4височина : 176 - 182 см
Решение. Нека решим проблема със следните стойности на параметрите: а=178,σ=6,к=3
. Нека r.v. х
−
височината на произволно избран човек (разпределя се според състоянието нормално с дадените параметри). Намерете вероятността, от която ще се нуждае случайно избран човек 3
ти растеж. Използване на странността на функцията на Лаплас F(x)и таблица с неговите стойности: P(170
Вероятностно разпределение на непрекъсната случайна променлива х, който взема всички стойности от сегмента , е наречен униформа, ако нейната плътност на вероятността на този сегмент е постоянна, а извън нея е равна на нула. По този начин, плътността на вероятността на непрекъсната случайна променлива х, разпределени равномерно върху сегмента , изглежда като:

Да дефинираме очаквана стойност, дисперсияи за случайна величина с равномерно разпределение.
, ![]() ,
, ![]() .
.
Пример.Всички стойности на една равномерно разпределена случайна променлива лежат на интервала . Намерете вероятността случайна променлива да попадне в интервала (3;5) .
a=2, b=8,  .
.
Биномиално разпределение
Нека се произвежда нтестове и вероятността за възникване на събитие Авъв всеки тест е стри не зависи от резултата от други изпитания (независими изпитания). Тъй като вероятността за настъпване на събитие Ав един тест е стр, тогава вероятността да не се случи е равна на q=1-p.
Нека събитието Авлезе низпитания мведнъж. Това сложно събитие може да бъде написано като продукт:
![]() .
.
Тогава вероятността, че нтестово събитие Аще дойде мпъти се изчислява по формулата:
![]() или
или ![]() (1)
(1)
Формула (1) се нарича Формула на Бернули.
Позволявам хе случайна променлива, равна на броя повторения на събитието А V нтестове, които приемат стойности с вероятности:
Полученият закон за разпределение на случайна променлива се нарича биномен закон на разпределение.
| х | м | н | ||||
| П |
Очаквана стойност, дисперсияИ стандартно отклонениеслучайни променливи, разпределени според биномиалния закон, се определят по формулите:
, , .
Пример.Изстрелват се три изстрела по целта, като вероятността за попадение на всеки изстрел е 0,8. Разглеждаме случайна променлива х- броят на попаденията в целта. Намерете неговия закон на разпределение, математическо очакване, дисперсия и стандартно отклонение.
р=0,8, q=0,2, n=3, ![]() , ,
, , ![]() .
.
![]() - вероятност от 0 попадения;
- вероятност от 0 попадения;
Вероятност за едно попадение;
Вероятност за две попадения;
![]() е вероятността от три попадения.
е вероятността от три попадения.
Получаваме закона за разпределение:
| х | ||||
| П | 0,008 | 0,096 | 0,384 | 0,512 |
Задачи
1. Монета се хвърля 7 пъти. Намерете вероятността то да падне с главата надолу 4 пъти.
2. Монета се хвърля 8 пъти. Намерете вероятността гербът да се появи не повече от три пъти.
3. Вероятността за попадение в целта при стрелба от пистолет p=0,6. Намерете математическото очакване на общия брой попадения, ако са произведени 10 изстрела.
4. Намерете математическото очакване на броя на лотарийните билети, които ще спечелят, ако бъдат закупени 20 билета, а вероятността за печалба от един билет е 0,3.
Функцията на разпределение в този случай, съгласно (5.7), ще приеме формата:
където: m е математическото очакване, s е стандартното отклонение.
Нормалното разпределение се нарича още гаусово на името на немския математик Гаус. Фактът, че една случайна променлива има нормално разпределение с параметри: m,, се означава по следния начин: N (m, s), където: m =a =M ;
Доста често във формулите математическото очакване се означава с А . Ако една случайна променлива е разпределена по закона N(0,1), тогава тя се нарича нормализирана или стандартизирана нормална стойност. Функцията на разпределение за него има формата:
|
|
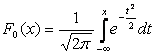 .
.Графиката на плътността на нормалното разпределение, която се нарича нормална крива или крива на Гаус, е показана на фиг. 5.4.

Ориз. 5.4. Нормална плътност на разпределение
На пример се разглежда определянето на числените характеристики на случайна променлива по нейната плътност.
Пример 6.
Непрекъсната случайна променлива се дава от плътността на разпределение: ![]() .
.
Определете вида на разпределението, намерете математическото очакване M(X) и дисперсията D(X).
Сравнявайки дадената плътност на разпределение с (5.16), можем да заключим, че е даден нормалният закон на разпределение с m =4. Следователно, математическо очакване M(X)=4, дисперсия D(X)=9.
Стандартно отклонение s=3.
Функцията на Лаплас, която има формата:
|
|
 ,
,е свързано с функцията на нормалното разпределение (5.17) чрез връзката:
F 0 (x) \u003d F (x) + 0,5.
Функцията на Лаплас е странна.
Ф(-x)=-Ф(x).
Стойностите на функцията на Лаплас Ф(х) са таблични и взети от таблицата според стойността на x (вижте Приложение 1).
Нормалното разпределение на непрекъсната случайна променлива играе важна роля в теорията на вероятностите и в описанието на реалността, то е широко разпространено в случайните природни явления. На практика много често има случайни величини, които се формират именно в резултат на сумирането на много случайни членове. По-специално, анализът на грешките при измерване показва, че те са сбор от различни видове грешки. Практиката показва, че вероятностното разпределение на грешките при измерване е близко до нормалния закон.
С помощта на функцията на Лаплас могат да се решават задачи за изчисляване на вероятността за попадане в даден интервал и дадено отклонение на нормална случайна променлива.
Този въпрос отдавна е проучен в детайли и най-широко използван е методът на полярните координати, предложен от Джордж Бокс, Мервин Мюлер и Джордж Марсалия през 1958 г. Този метод ви позволява да получите двойка независими нормално разпределени случайни променливи със средна стойност 0 и дисперсия 1, както следва:
Където Z 0 и Z 1 са желаните стойности, s \u003d u 2 + v 2 и u и v са случайни променливи, равномерно разпределени в сегмента (-1, 1), избрани по такъв начин, че условието 0 да е изпълнено< s < 1.
Мнозина използват тези формули, без дори да мислят, а много дори не подозират за тяхното съществуване, тъй като използват готови реализации. Но има хора, които имат въпроси: „Откъде идва тази формула? И защо получавате двойка стойности наведнъж? По-нататък ще се опитам да дам ясен отговор на тези въпроси.
Като начало нека ви напомня какво представляват плътността на вероятността, функцията на разпределение на случайна променлива и обратната функция. Да предположим, че има някаква случайна променлива, чието разпределение е дадено от функцията на плътност f(x), която има следната форма:

Това означава, че вероятността стойността на тази случайна променлива да бъде в интервала (A, B) е равна на площта на защрихованата област. И като следствие, площта на цялата защрихована област трябва да бъде равна на единица, тъй като във всеки случай стойността на случайната променлива ще попадне в областта на функцията f.
Функцията на разпределение на случайна променлива е интеграл от функцията на плътността. И в този случай приблизителната му форма ще бъде следната:

Тук значението е, че стойността на случайната променлива ще бъде по-малка от A с вероятност B. И в резултат на това функцията никога не намалява и нейните стойности лежат в интервала.
Обратната функция е функция, която връща аргумента на оригиналната функция, ако подадете стойността на оригиналната функция в нея. Например за функцията x 2 обратната ще бъде функцията за извличане на корен, за sin (x) тя е arcsin (x) и т.н.
Тъй като повечето генератори на псевдослучайни числа дават само равномерно разпределение на изхода, често се налага да го преобразувате в някакъв друг. В този случай, към нормален Гаус:

В основата на всички методи за трансформиране на равномерно разпределение във всяко друго разпределение е методът на обратната трансформация. Работи по следния начин. Намира се функция, която е обратна на функцията на търсеното разпределение, и към нея като аргумент се предава случайна променлива, равномерно разпределена в сегмента (0, 1). На изхода получаваме стойност с необходимото разпределение. За по-голяма яснота ето следната снимка.

По този начин еднакъв сегмент се размазва в съответствие с новото разпределение, като се проектира върху друга ос чрез обратна функция. Но проблемът е, че интегралът на плътността на разпределението на Гаус не е лесен за изчисляване, така че горните учени трябваше да мамят.
Има разпределение хи-квадрат (разпределение на Пиърсън), което е разпределението на сумата от квадратите на k независими нормални случайни променливи. А в случая, когато k = 2, това разпределение е експоненциално.

Това означава, че ако точка в правоъгълна координатна система има произволни X и Y координати, разпределени нормално, тогава след преобразуването на тези координати в полярната система (r, θ), квадратът на радиуса (разстоянието от началото до точката) ще се разпределят експоненциално, тъй като квадратът на радиуса е сумата от квадратите на координатите (според закона на Питагор). Плътността на разпределение на такива точки в равнината ще изглежда така:


Тъй като е еднакъв във всички посоки, ъгълът θ ще има равномерно разпределение в диапазона от 0 до 2π. Обратното също е вярно: ако посочите точка в полярната координатна система, като използвате две независими случайни променливи (ъгълът, разпределен равномерно и радиусът, разпределен експоненциално), тогава правоъгълните координати на тази точка ще бъдат независими нормални случайни променливи. И вече е много по-лесно да се получи експоненциално разпределение от равномерно, като се използва същият метод на обратна трансформация. Това е същността на полярния метод на Бокс-Мюлер.
Сега да вземем формулите.
![]() (1)
(1)
За да се получат r и θ, е необходимо да се генерират две случайни променливи, равномерно разпределени в сегмента (0, 1) (да ги наречем u и v), разпределението на една от които (да кажем v) трябва да се преобразува в експоненциално до получи радиуса. Функцията на експоненциалното разпределение изглежда така:
Неговата обратна функция:
![]()
Тъй като равномерното разпределение е симетрично, трансформацията ще работи по подобен начин с функцията
![]()
От формулата за разпределение хи-квадрат следва, че λ = 0,5. Заместваме λ, v в тази функция и получаваме квадрата на радиуса, а след това и самия радиус:

Получаваме ъгъла, като разтегнем единичния сегмент до 2π:
Сега заместваме r и θ във формули (1) и получаваме:
 (2)
(2)
Тези формули са готови за употреба. X и Y ще бъдат независими и нормално разпределени с дисперсия 1 и средна стойност 0. За да получите разпределение с други характеристики, е достатъчно да умножите резултата от функцията по стандартното отклонение и да добавите средната стойност.
Но е възможно да се отървем от тригонометричните функции, като посочим ъгъла не директно, а индиректно чрез правоъгълните координати на произволна точка в кръг. След това чрез тези координати ще бъде възможно да се изчисли дължината на радиус вектора и след това да се намерят косинусът и синусът, като се разделят съответно x и y на него. Как и защо работи?
Избираме произволна точка от равномерно разпределени в кръга с единичен радиус и обозначаваме квадрата на дължината на радиус вектора на тази точка с буквата s:

Изборът се прави чрез присвояване на произволни x и y правоъгълни координати, равномерно разпределени в интервала (-1, 1), и изхвърляне на точки, които не принадлежат на окръжността, както и централната точка, в която е ъгълът на радиус вектора не е дефиниран. Тоест условието 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Получаваме формулите, както в началото на статията. Недостатъкът на този метод е отхвърлянето на точки, които не са включени в кръга. Тоест, използвайки само 78,5% от генерираните случайни променливи. При по-старите компютри липсата на тригонометрични функции все още беше голямо предимство. Сега, когато една инструкция на процесора едновременно изчислява синус и косинус за миг, мисля, че тези методи все още могат да се конкурират.
Лично аз имам още два въпроса:
- Защо стойността на s е равномерно разпределена?
- Защо сумата от квадратите на две нормални случайни променливи е експоненциално разпределена?

Ако подобна трансформация се направи за нормална случайна променлива, тогава функцията на плътността на нейния квадрат ще се окаже подобна на хипербола. А събирането на два квадрата от нормални случайни променливи вече е много по-сложен процес, свързан с двойното интегриране. А това, че резултатът ще е експоненциално разпределение, лично на мен ми остава да го проверя с практически метод или да го приема като аксиома. А за тези, които се интересуват, предлагам да се запознаете с темата по-отблизо, като черпите знания от тези книги:
- Wentzel E.S. Теория на вероятностите
- Кнут Д.Е. Изкуството на програмирането, том 2
В заключение ще дам пример за внедряване на нормално разпределен генератор на случайни числа в JavaScript:
Функция Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0); var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev + mean; ) ); ) g = new Gauss(); // създаване на обект a = g.next(); // генерирайте двойка стойности и вземете първата b = g.next(); // получаваме второто c = g.next(); // генерирайте двойка стойности отново и вземете първата
Параметрите средно (математическо очакване) и dev (стандартно отклонение) не са задължителни. Обръщам внимание на факта, че логаритъма е естествен.
