Контрольная работа: Распределение "хи-квадрат" и его применение. Распределение хи квадрат
В том случае, если полученное значение критерия χ 2 больше критического, делаем вывод о наличии статистической взаимосвязи между изучаемым фактором риска и исходом при соответствующем уровне значимости.
Пример расчета критерия хи-квадрат Пирсона
Определим статистическую значимость влияния фактора курения на частоту случаев артериальной гипертонии по рассмотренной выше таблице:
1. Рассчитываем ожидаемые значения для каждой ячейки:
2. Находим значение критерия хи-квадрат Пирсона:
χ 2 = (40-33.6) 2 /33.6 + (30-36.4) 2 /36.4 + (32-38.4) 2 /38.4 + (48-41.6) 2 /41.6 = 4.396.
3. Число степеней свободы f = (2-1)*(2-1) = 1. Находим по таблице критическое значение критерия хи-квадрат Пирсона, которое при уровне значимости p=0.05 и числе степеней свободы 1 составляет 3.841.
4. Сравниваем полученное значение критерия хи-квадрат с критическим: 4.396 > 3.841, следовательно зависимость частоты случаев артериальной гипертонии от наличия курения - статистически значима. Уровень значимости данной взаимосвязи соответствует p<0.05.
Также критерий хи-квадрат Пирсона вычисляется по формуле
Но для таблицы 2х2 более точные результаты дает критерий с поправкой Йетса

Если  то Н(0)
принимается,
то Н(0)
принимается,
В случае ![]() принимается Н(1)
принимается Н(1)
Когда число наблюдений невелико и в клетках таблицы встречается частота меньше 5, критерий хи-квадрат неприменим и для проверки гипотез используется точный критерий Фишера . Процедура вычисления этого критерия достаточно трудоемка и в этом случае лучше воспользоваться компьютерными программами статанализа.
По таблице сопряженности можно вычислить меру связи между двумя качественными признаками – ею является коэффициент ассоциации Юла Q (аналог коэффициента корреляции)

Q лежит в пределах от 0 до 1. Близкий к единице коэффициент свидетельствует о сильной связи между признаками. При равенстве его нулю – связь отсутствует.
Аналогично используется коэффициент фи-квадрат (φ 2)
ЗАДАЧА-ЭТАЛОН
В таблице описывается связь между частотой мутации у групп дрозофил с подкормкой и без подкормки
Анализ таблицы сопряженности
Для анализа таблицы сопряженности выдвигается Н 0 - гипотеза.т.е.отсуствие влияния изучаемого признака на результат исследования.Для этого рассчитывается ожидаемая частота,и строится таблица ожидания.
Таблица ожидания
| группы | Чило культур | Всего | ||||
| Давшие мутации | Не давшие мутации | |||||
| Фактическая частота | Ожидаемая частота | Фактическая частота | Ожидаемая частота | |||
| С подкормкой | ||||||
| Без подкормкой | ||||||
| всего | ||||||
Метод №1
Определяем частоту ожидания:
2756 – Х ![]() ;
;
2. 3561 – 3124
Если число наблюдении в группах мало, при применении Х 2, в случае сопоставления фактических и ожидаемых частот при дискретных распределениях сопряжено с некоторой неточностью.Для уменьшения неточности применяют поправку Йейтса.
). Конкретная формулировка проверяемой гипотезы от случая к случаю будет варьировать.
В этом сообщении я опишу принцип работы критерия \(\chi^2\) на (гипотетическом) примере из иммунологии . Представим, что мы выполнили эксперимент по установлению эффективности подавления развития микробного заболевания при введении в организм соответствующих антител . Всего в эксперименте было задействовано 111 мышей, которых мы разделили на две группы, включающие 57 и 54 животных соответственно. Первой группе мышей сделали инъекции патогенных бактерий с последующим введением сыворотки крови, содержащей антитела против этих бактерий. Животные из второй группы служили контролем – им сделали только бактериальные инъекции. После некоторого времени инкубации оказалось, что 38 мышей погибли, а 73 выжили. Из погибших 13 принадлежали первой группе, а 25 – ко второй (контрольной). Проверяемую в этом эксперименте нулевую гипотезу можно сформулировать так: введение сыворотки с антителами не оказывает никакого влияния на выживаемость мышей. Иными словами, мы утверждаем, что наблюдаемые различия в выживаемости мышей (77.2% в первой группе против 53.7% во второй группе) совершенно случайны и не связаны с действием антител.
Полученные в эксперименте данные можно представить в виде таблицы:
Всего |
|||
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Таблицы, подобные приведенной, называют таблицами сопряженности . В рассматриваемом примере таблица имеет размерность 2х2: есть два класса объектов («Бактерии + сыворотка» и «Только бактерии»), которые исследуются по двум признакам ("Погибло" и "Выжило"). Это простейший случай таблицы сопряженности: безусловно, и количество исследуемых классов, и количество признаков может быть бóльшим.
Для проверки сформулированной выше нулевой гипотезы нам необходимо знать, какова была бы ситуация, если бы антитела действительно не оказывали никакого действия на выживаемость мышей. Другими словами, нужно рассчитать ожидаемые частоты для соответствующих ячеек таблицы сопряженности. Как это сделать? В эксперименте всего погибло 38 мышей, что составляет 34.2% от общего числа задействованных животных. Если введение антител не влияет на выживаемость мышей, в обеих экспериментальных группах должен наблюдаться одинаковый процент смертности, а именно 34.2%. Рассчитав, сколько составляет 34.2% от 57 и 54, получим 19.5 и 18.5. Это и есть ожидаемые величины смертности в наших экспериментальных группах. Аналогичным образом рассчитываются и ожидаемые величины выживаемости: поскольку всего выжили 73 мыши, или 65.8% от общего их числа, то ожидаемые частоты выживаемости составят 37.5 и 35.5. Составим новую таблицу сопряженности, теперь уже с ожидаемыми частотами:
Погибшие |
Выжившие |
Всего |
|
Бактерии + сыворотка |
|||
Только бактерии |
|||
Всего |
Как видим, ожидаемые частоты довольно сильно отличаются от наблюдаемых, т.е. введение антител, похоже, все-таки оказывает влияние на выживаемость мышей, зараженных патогенным микроорганизмом. Это впечатление мы можем выразить количественно при помощи критерия согласия Пирсона \(\chi^2\):
\[\chi^2 = \sum_{}\frac{(f_o - f_e)^2}{f_e},\]
где \(f_o\) и \(f_e\) - наблюдаемые и ожидаемые частоты соответственно. Суммирование производится по всем ячейкам таблицы. Так, для рассматриваемого примера имеем
\[\chi^2 = (13 – 19.5)^2/19.5 + (44 – 37.5)^2/37.5 + (25 – 18.5)^2/18.5 + (29 – 35.5)^2/35.5 = \]
Достаточно ли велико полученное значение \(\chi^2\), чтобы отклонить нулевую гипотезу? Для ответа на этот вопрос необходимо найти соответствующее критическое значение критерия. Число степеней свободы для \(\chi^2\) рассчитывается как \(df = (R - 1)(C - 1)\), где \(R\) и \(C\) - количество строк и столбцов в таблице сопряженности. В нашем случае \(df = (2 -1)(2 - 1) = 1\). Зная число степеней свободы, мы теперь легко можем узнать критическое значение \(\chi^2\) при помощи стандартной R-функции qchisq() :
Таким образом, при одной степени свободы только в 5% случаев величина критерия \(\chi^2\) превышает 3.841. Полученное нами значение 6.79 значительно превышает это критического значение, что дает нам право отвергнуть нулевую гипотезу об отсутствии связи между введением антител и выживаемостью зараженных мышей. Отвергая эту гипотезу, мы рискуем ошибиться с вероятностью менее 5%.
Следует отметить, что приведенная выше формула для критерия \(\chi^2\) дает несколько завышенные значения при работе с таблицами сопряженности размером 2х2. Причина заключается в том, что распределение самого критерия \(\chi^2\) является непрерывным, тогда как частоты бинарных признаков ("погибло" / "выжило") по определению дискретны. В связи с этим при расчете критерия принято вводить т.н. поправку на непрерывность , или поправку Йетса :
\[\chi^2_Y = \sum_{}\frac{(|f_o - f_e| - 0.5)^2}{f_e}.\]
"s Chi-squared test with Yates" continuity correction data : mice X-squared = 5.7923 , df = 1 , p-value = 0.0161
Как видим, R автоматически применяет поправку Йетса на непрерывность (Pearson"s Chi-squared test with Yates" continuity correction ). Рассчитанное программой значение \(\chi^2\) составило 5.79213. Мы можем отклонить нулевую гипотезу об отсутствии эффекта антител, рискуя ошибиться с вероятностью чуть более 1% (p-value = 0.0161 ).
Министерство образования и науки Российской Федерации
Федеральное агентство по образованию города Иркутска
Байкальский государственный университет экономики и права
Кафедра Информатики и Кибернетики
Распределение "хи-квадрат" и его применение
Колмыкова Анна Андреевна
студентка 2 курса
группы ИС-09-1
Иркутск 2010
Введение
1. Распределение "хи-квадрат"
Приложение
Заключение
Список используемой литературы
Введение
Как подходы, идеи и результаты теории вероятностей используются в нашей жизни?
Базой является вероятностная модель реального явления или процесса, т.е. математическая модель, в которой объективные соотношения выражены в терминах теории вероятностей. Вероятности используются, прежде всего, для описания неопределенностей, которые необходимо учитывать при принятии решений. Имеются в виду, как нежелательные возможности (риски), так и привлекательные ("счастливый случай"). Иногда случайность вносится в ситуацию сознательно, например, при жеребьевке, случайном отборе единиц для контроля, проведении лотерей или опросов потребителей.
Теория вероятностей позволяет по одним вероятностям рассчитать другие, интересующие исследователя.
Вероятностная модель явления или процесса является фундаментом математической статистики. Используются два параллельных ряда понятий – относящиеся к теории (вероятностной модели) и относящиеся к практике (выборке результатов наблюдений). Например, теоретической вероятности соответствует частота, найденная по выборке. Математическому ожиданию (теоретический ряд) соответствует выборочное среднее арифметическое (практический ряд). Как правило, выборочные характеристики являются оценками теоретических. При этом величины, относящиеся к теоретическому ряду, "находятся в головах исследователей", относятся к миру идей (по древнегреческому философу Платону), недоступны для непосредственного измерения. Исследователи располагают лишь выборочными данными, с помощью которых они стараются установить интересующие их свойства теоретической вероятностной модели.
Зачем же нужна вероятностная модель? Дело в том, что только с ее помощью можно перенести свойства, установленные по результатам анализа конкретной выборки, на другие выборки, а также на всю так называемую генеральную совокупность. Термин "генеральная совокупность" используется, когда речь идет о большой, но конечной совокупности изучаемых единиц. Например, о совокупности всех жителей России или совокупности всех потребителей растворимого кофе в Москве. Цель маркетинговых или социологических опросов состоит в том, чтобы утверждения, полученные по выборке из сотен или тысяч человек, перенести на генеральные совокупности в несколько миллионов человек. При контроле качества в роли генеральной совокупности выступает партия продукции.
Чтобы перенести выводы с выборки на более обширную совокупность, необходимы те или иные предположения о связи выборочных характеристик с характеристиками этой более обширной совокупности. Эти предположения основаны на соответствующей вероятностной модели.
Конечно, можно обрабатывать выборочные данные, не используя ту или иную вероятностную модель. Например, можно рассчитывать выборочное среднее арифметическое, подсчитывать частоту выполнения тех или иных условий и т.п. Однако результаты расчетов будут относиться только к конкретной выборке, перенос полученных с их помощью выводов на какую-либо иную совокупность некорректен. Иногда подобную деятельность называют "анализ данных". По сравнению с вероятностно-статистическими методами анализ данных имеет ограниченную познавательную ценность.
Итак, использование вероятностных моделей на основе оценивания и проверки гипотез с помощью выборочных характеристик – вот суть вероятностно-статистических методов принятия решений.
Распределение "хи-квадрат"
С помощью нормального распределения определяются три распределения, которые в настоящее время часто используются при статистической обработке данных. Это распределения Пирсона ("хи – квадрат"), Стьюдента и Фишера.
Мы остановимся на распределении
("хи – квадрат"). Впервые это распределение было исследовано астрономом Ф.Хельмертом в 1876 году. В связи с гауссовской теорией ошибок он исследовал суммы квадратов n независимых стандартно нормально распределенных случайных величин. Позднее Карл Пирсон (Karl Pearson) дал имя данной функции распределения "хи – квадрат". И сейчас распределение носит его имя.Благодаря тесной связи с нормальным распределением, χ2-распределение играет важную роль в теории вероятностей и математической статистике. χ2-распределение, и многие другие распределения, которые определяются посредством χ2-распределения (например - распределение Стьюдента), описывают выборочные распределения различных функций от нормально распределенных результатов наблюдений и используются для построения доверительных интервалов и статистических критериев.
Распределение Пирсона
(хи - квадрат) – распределение случайной величиныгде X1, X2,…, Xn - нормальные независимые случайные величины, причем математическое ожидание каждой из них равно нулю, а среднее квадратическое отклонение - единице.Сумма квадратов
распределена по закону
("хи – квадрат").При этом число слагаемых, т.е. n, называется "числом степеней свободы" распределения хи – квадрат. C увеличением числа степеней свободы распределение медленно приближается к нормальному.
Плотность этого распределения

Итак, распределение χ2 зависит от одного параметра n – числа степеней свободы.
Функция распределения χ2 имеет вид:

если χ2≥0. (2.7.)
На Рисунок 1 изображен график плотности вероятности и функции χ2 – распределения для разных степеней свободы.

Рисунок 1 Зависимость плотности вероятности φ (x) в распределении χ2 (хи – квадрат) при разном числе степеней свободы.
Моменты распределения "хи-квадрат":
Распределение "хи-квадрат" используют при оценивании дисперсии (с помощью доверительного интервала), при проверке гипотез согласия, однородности, независимости, прежде всего для качественных (категоризованных) переменных, принимающих конечное число значений, и во многих других задачах статистического анализа данных.
2. "Хи-квадрат" в задачах статистического анализа данных
Статистические методы анализа данных применяются практически во всех областях деятельности человека. Их используют всегда, когда необходимо получить и обосновать какие-либо суждения о группе (объектов или субъектов) с некоторой внутренней неоднородностью.
Современный этап развития статистических методов можно отсчитывать с 1900 г., когда англичанин К. Пирсон основал журнал "Biometrika". Первая треть ХХ в. прошла под знаком параметрической статистики. Изучались методы, основанные на анализе данных из параметрических семейств распределений, описываемых кривыми семейства Пирсона. Наиболее популярным было нормальное распределение. Для проверки гипотез использовались критерии Пирсона, Стьюдента, Фишера. Были предложены метод максимального правдоподобия, дисперсионный анализ, сформулированы основные идеи планирования эксперимента.
Распределение "хи-квадрат" является одним из наиболее широко используемых в статистике для проверки статистических гипотез. На основе распределения "хи-квадрат" построен один из наиболее мощных критериев согласия – критерий "хи-квадрата" Пирсона.
Критерием согласия называют критерий проверки гипотезы о предполагаемом законе неизвестного распределения.
Критерий χ2 ("хи-квадрат") используется для проверки гипотезы различных распределений. В этом заключается его достоинство.
Расчетная формула критерия равна

где m и m’ - соответственно эмпирические и теоретические частоты
рассматриваемого распределения;
n - число степеней свободы.
Для проверки нам необходимо сравнивать эмпирические (наблюдаемые) и теоретические (вычисленные в предположении нормального распределения) частоты.
При полном совпадении эмпирических частот с частотами, вычисленными или ожидаемыми S (Э – Т) = 0 и критерий χ2 тоже будет равен нулю. Если же S (Э – Т) не равно нулю это укажет на несоответствие вычисленных частот эмпирическим частотам ряда. В таких случаях необходимо оценить значимость критерия χ2, который теоретически может изменяться от нуля до бесконечности. Это производится путем сравнения фактически полученной величины χ2ф с его критическим значением (χ2st).Нулевая гипотеза, т. е. предположение, что расхождение между эмпирическими и теоретическими или ожидаемыми частотами носит случайный характер, опровергается, если χ2ф больше или равно χ2st для принятого уровня значимости (a) и числа степеней свободы (n).
Рассмотрим применение в MS EXCEL критерия хи-квадрат Пирсона для проверки простых гипотез.
После получения экспериментальных данных (т.е. когда имеется некая выборка ) обычно производится выбор закона распределения, наиболее хорошо описывающего случайную величину, представленную данной выборкой . Проверка того, насколько хорошо экспериментальные данные описываются выбранным теоретическим законом распределения, осуществляется с использованием критериев согласия . Нулевой гипотезой , обычно выступает гипотеза о равенстве распределения случайной величины некоторому теоретическому закону.
Сначала рассмотрим применение критерия согласия Пирсона Х 2 (хи-квадрат) в отношении простых гипотез (параметры теоретического распределения считаются известными). Затем - , когда задается только форма распределения, а параметры этого распределения и значение статистики Х 2 оцениваются/рассчитываются на основании одной и той же выборки .
Примечание : В англоязычной литературе процедура применения критерия согласия Пирсона Х 2 имеет название The chi-square goodness of fit test .
Напомним процедуру проверки гипотез:
- на основе выборки вычисляется значение статистики , которая соответствует типу проверяемой гипотезы. Например, для используется t -статистика (если не известно);
- при условии истинности нулевой гипотезы , распределение этой статистики известно и может быть использовано для вычисления вероятностей (например, для t -статистики это );
- вычисленное на основе выборки значение статистики сравнивается с критическим для заданного значением ();
- нулевую гипотезу отвергают, если значение статистики больше критического (или если вероятность получить это значение статистики () меньше уровня значимости , что является эквивалентным подходом).
Проведем проверку гипотез для различных распределений.
Дискретный случай
Предположим, что два человека играют в кости. У каждого игрока свой набор костей. Игроки по очереди кидают сразу по 3 кубика. Каждый раунд выигрывает тот, кто выкинет за раз больше шестерок. Результаты записываются. У одного из игроков после 100 раундов возникло подозрение, что кости его соперника – несимметричные, т.к. тот часто выигрывает (часто выбрасывает шестерки). Он решил проанализировать насколько вероятно такое количество исходов противника.
Примечание : Т.к. кубиков 3, то за раз можно выкинуть 0; 1; 2 или 3 шестерки, т.е. случайная величина может принимать 4 значения.
Из теории вероятности нам известно, что если кубики симметричные, то вероятность выпадения шестерок подчиняется . Поэтому, после 100 раундов частоты выпадения шестерок могут быть вычислены с помощью формулы
=БИНОМ.РАСП(A7;3;1/6;ЛОЖЬ)*100
В формуле предполагается, что в ячейке А7 содержится соответствующее количество выпавших шестерок в одном раунде.
Примечание : Расчеты приведены в файле примера на листе Дискретное .
Для сравнения наблюденных (Observed) и теоретических частот (Expected) удобно пользоваться .

При значительном отклонении наблюденных частот от теоретического распределения, нулевая гипотеза о распределении случайной величины по теоретическому закону, должна быть отклонена. Т.е., если игральные кости соперника несимметричны, то наблюденные частоты будут «существенно отличаться» от биномиального распределения .
В нашем случае на первый взгляд частоты достаточно близки и без вычислений сложно сделать однозначный вывод. Применим критерий согласия Пирсона Х 2 , чтобы вместо субъективного высказывания «существенно отличаться», которое можно сделать на основании сравнения гистограмм , использовать математически корректное утверждение.
Используем тот факт, что в силу закона больших чисел наблюденная частота (Observed) с ростом объема выборки n стремится к вероятности, соответствующей теоретическому закону (в нашем случае, биномиальному закону ). В нашем случае объем выборки n равен 100.
Введем тестовую статистику , которую обозначим Х 2:

где O l – это наблюденная частота событий, что случайная величина приняла определенные допустимые значения, E l – это соответствующая теоретическая частота (Expected). L – это количество значений, которые может принимать случайная величина (в нашем случае равна 4).
Как видно из формулы, эта статистика является мерой близости наблюденных частот к теоретическим, т.е. с помощью нее можно оценить «расстояния» между этими частотами. Если сумма этих «расстояний» «слишком велика», то эти частоты «существенно отличаются». Понятно, что если наш кубик симметричный (т.е. применим биномиальный закон ), то вероятность того, что сумма «расстояний» будет «слишком велика» будет малой. Чтобы вычислить эту вероятность нам необходимо знать распределение статистики Х 2 (статистика Х 2 вычислена на основе случайной выборки , поэтому она является случайной величиной и, следовательно, имеет свое распределение вероятностей ).
Из многомерного аналога интегральной теоремы Муавра-Лапласа известно, что при n->∞ наша случайная величина Х 2 асимптотически с L - 1 степенями свободы.
Итак, если вычисленное значение статистики Х 2 (сумма «расстояний» между частотами) будет больше чем некое предельное значение, то у нас будет основание отвергнуть нулевую гипотезу . Как и при проверке параметрических гипотез , предельное значение задается через уровень значимости . Если вероятность того, что статистика Х 2 примет значение меньше или равное вычисленному (p -значение ), будет меньше уровня значимости , то нулевую гипотезу можно отвергнуть.
В нашем случае, значение статистики равно 22,757. Вероятность, что статистика Х 2 примет значение больше или равное 22,757 очень мала (0,000045) и может быть вычислена по формулам
=ХИ2.РАСП.ПХ(22,757;4-1)
или
=ХИ2.ТЕСТ(Observed; Expected)
Примечание : Функция ХИ2.ТЕСТ() специально создана для проверки связи между двумя категориальными переменными (см. ).
Вероятность 0,000045 существенно меньше обычного уровня значимости 0,05. Так что, у игрока есть все основания подозревать своего противника в нечестности (нулевая гипотеза о его честности отвергается).

При применении критерия Х 2 необходимо следить за тем, чтобы объем выборки n был достаточно большой, иначе будет неправомочна аппроксимация распределения статистики Х 2 . Обычно считается, что для этого достаточно, чтобы наблюденные частоты (Observed) были больше 5. Если это не так, то малые частоты объединяются в одно или присоединяются к другим частотам, причем объединенному значению приписывается суммарная вероятность и, соответственно, уменьшается число степеней свободы Х 2 -распределения .
Для того чтобы улучшить качество применения критерия Х 2 (), необходимо уменьшать интервалы разбиения (увеличивать L и, соответственно, увеличивать количество степеней свободы ), однако этому препятствует ограничение на количество попавших в каждый интервал наблюдений (д.б.>5).
Непрерывный случай
Критерий согласия Пирсона Х 2 можно применить так же в случае .
Рассмотрим некую выборку , состоящую из 200 значений. Нулевая гипотеза утверждает, что выборка сделана из .
Примечание : Cлучайные величины в файле примера на листе Непрерывное сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) . Поэтому, новые значения выборки генерируются при каждом пересчете листа.
Соответствует ли имеющийся набор данных можно визуально оценить .

Как видно из диаграммы, значения выборки довольно хорошо укладываются вдоль прямой. Однако, как и в для проверки гипотезы применим Критерий согласия Пирсона Х 2 .
Для этого разобьем диапазон изменения случайной величины на интервалы с шагом 0,5 . Вычислим наблюденные и теоретические частоты. Наблюденные частоты вычислим с помощью функции ЧАСТОТА() , а теоретические – с помощью функции НОРМ.СТ.РАСП() .
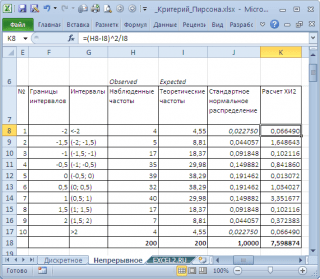
Примечание : Как и для дискретного случая , необходимо следить, чтобы выборка была достаточно большая, а в интервал попадало >5 значений.
Вычислим статистику Х 2 и сравним ее с критическим значением для заданного уровня значимости
(0,05). Т.к. мы разбили диапазон изменения случайной величины на 10 интервалов, то число степеней свободы равно 9. Критическое значение можно вычислить по формуле
=ХИ2.ОБР.ПХ(0,05;9)
или
=ХИ2.ОБР(1-0,05;9)
На диаграмме выше видно, что значение статистики равно 8,19, что существенно выше критического значения – нулевая гипотеза не отвергается.
Ниже приведена , на которой выборка приняла маловероятное значение и на основании критерия согласия Пирсона Х 2 нулевая гипотеза была отклонена (не смотря на то, что случайные значения были сгенерированы с помощью формулы =НОРМ.СТ.ОБР(СЛЧИС()) , обеспечивающей выборку из стандартного нормального распределения ).

Нулевая гипотеза отклонена, хотя визуально данные располагаются довольно близко к прямой линии.
В качестве примера также возьмем выборку из U(-3; 3). В этом случае, даже из графика очевидно, что нулевая гипотеза должна быть отклонена.

Критерий согласия Пирсона Х 2 также подтверждает, что нулевая гипотеза должна быть отклонена.
В этой статье речь будет идти о исследовании зависимости между признаками, или как больше нравится - случайными величинами, переменными. В частности, мы разберем как ввести меру зависимости между признаками, используя критерий Хи-квадрат и сравним её с коэффициентом корреляции.
Для чего это может понадобиться? К примеру, для того, чтобы понять какие признаки сильнее зависимы от целевой переменной при построении кредитного скоринга - определении вероятности дефолта клиента. Или, как в моем случае, понять какие показатели нобходимо использовать для программирования торгового робота.
Отдельно отмечу, что для анализа данных я использую язык c#. Возможно это все уже реализовано на R или Python, но использование c# для меня позволяет детально разобраться в теме, более того это мой любимый язык программирования.
Начнем с совсем простого примера, создадим в экселе четыре колонки, используя генератор случайных чисел:
X
=СЛУЧМЕЖДУ(-100;100)
Y
=X
*10+20
Z
=X
*X
T
=СЛУЧМЕЖДУ(-100;100)
Как видно, переменная Y линейно зависима от X ; переменная Z квадратично зависима от X ; переменные X и Т независимы. Такой выбор я сделал специально, потому что нашу меру зависимости мы будем сравнивать с коэффициентом корреляции . Как известно, между двумя случайными величинами он равен по модулю 1 если между ними самый «жесткий» вид зависимости - линейный. Между двумя независимыми случайными величинами корреляция нулевая, но из равенства коэффициента корреляции нулю не следует независимость . Далее мы это увидим на примере переменных X и Z .
Сохраняем файл как data.csv и начинаем первые прикиди. Для начала рассчитаем коэффициент корреляции между величинами. Код в статью я вставлять не стал, он есть на моем github . Получаем корреляцию по всевозможным парам:

Видно, что у линейно зависимых X и Y коэффициент корреляции равен 1. А вот у X и Z он равен 0.01, хотя зависимость мы задали явную Z =X *X . Ясно, что нам нужна мера, которая «чувствует» зависимость лучше. Но прежде, чем переходить к критерию Хи-квадрат, давайте рассмотрим что такое матрица сопряженности.
Чтобы построить матрицу сопряженности мы разобьём диапазон значений переменных на интервалы (или категорируем). Есть много способов такого разбиения, при этом какого-то универсального не существует. Некоторые из них разбивают на интервалы так, чтобы в них попадало одинаковое количество переменных, другие разбивают на равные по длине интервалы. Мне лично по духу комбинировать эти подходы. Я решил воспользоваться таким способом: из переменной я вычитаю оценку мат. ожидания, потом полученное делю на оценку стандартного отклонения. Иными словами я центрирую и нормирую случайную величину. Полученное значение умножается на коэффициент (в этом примере он равен 1), после чего все округляется до целого. На выходе получается переменная типа int, являющаяся идентификатором класса.
Итак, возьмем наши признаки X и Z , категорируем описанным выше способом, после чего посчитаем количество и вероятности появления каждого класса и вероятности появления пар признаков:

Это матрица по количеству. Здесь в строках - количества появлений классов переменной X , в столбцах - количества появлений классов переменной Z , в клетках - количества появлений пар классов одновременно. К примеру, класс 0 встретился 865 раз для переменной X , 823 раза для переменной Z и ни разу не было пары (0,0). Перейдем к вероятностям, поделив все значения на 3000 (общее число наблюдений):

Получили матрицу сопряженности, полученную после категорирования признаков. Теперь пора задуматься над критерием. По определению, случайные величины независимы, если независимы сигма-алгебры , порожденные этими случайными величинами. Независимость сигма-алгебр подразумевает попарную независимость событий из них. Два события называются независимыми, если вероятность их совместного появления равна произведению вероятностей этих событий: Pij = Pi*Pj . Именно этой формулой мы будем пользоваться для построения критерия.
Нулевая гипотеза : категорированные признаки X и Z независимы. Эквивалентная ей: распределение матрицы сопряженности задается исключительно вероятностями появления классов переменных (вероятности строк и столбцов). Или так: ячейки матрицы находятся произведением соответствующих вероятностей строк и столбцов. Эту формулировку нулевой гипотезы мы будем использовать для построения решающего правила: существенное расхождение между Pij и Pi*Pj будет являться основанием для отклонения нулевой гипотезы.
Пусть - вероятность появления класса 0 у переменной X
. Всего у нас n
классов у X
и m
классов у Z
. Получается, чтобы задать распределение матрицы нам нужно знать эти n
и m
вероятностей. Но на самом деле если мы знаем n-1
вероятность для X
, то последняя находится вычитанием из 1 суммы других. Таким образом для нахождения распределения матрицы сопряженности нам надо знать l=(n-1)+(m-1)
значений. Или мы имеем l
-мерное параметрическое пространство, вектор из которого задает нам наше искомое распределение. Статистика Хи-квадрат будет иметь следующий вид:
и, согласно теореме Фишера, иметь распределение Хи-квадрат с n*m-l-1=(n-1)(m-1)
степенями свободы.
Зададимся уровнем значимости 0.95 (или вероятность ошибки первого рода равна 0.05). Найдем квантиль распределения Хи квадрат для данного уровня значимости и степеней свободы из примера (n-1)(m-1)=4*3=12 : 21.02606982. Сама статистика Хи-квадрат для переменных X и Z равна 4088.006631. Видно, что гипотеза о независимости не принимается. Удобно рассматривать отношение статистики Хи-квадрат к пороговому значению - в данном случае оно равно Chi2Coeff=194.4256186 . Если это отношение меньше 1, то гипотеза о независимости принимается, если больше, то нет. Найдем это отношение для всех пар признаков:

Здесь Factor1
и Factor2
- имена признаков
src_cnt1
и src_cnt2
- количество уникальных значений исходных признаков
mod_cnt1
и mod_cnt2
- количество уникальных значений признаков после категорирования
chi2
- статистика Хи-квадрат
chi2max
- пороговое значение статистики Хи-квадрат для уровня значимости 0.95
chi2Coeff
- отношение статистики Хи-квадрат к пороговому значению
corr
- коэффициент корреляции
Видно, что независимы (chi2coeff<1) получились следующие пары признаков - (X,T ), (Y,T ) и (Z,T ), что логично, так как переменная T генерируется случайно. Переменные X и Z зависимы, но менее, чем линейно зависимые X и Y , что тоже логично.
Код утилиты, рассчитывающей данные показатели я выложил на github, там же файл data.csv. Утилита принимает на вход csv-файл и высчитывает зависимости между всеми парами колонок: PtProject.Dependency.exe data.csv
