Построение линейного тренда. Расчет параметров уравнения тренда
Ряда. Уравнение тренда.
Кривые роста, описывающие закономерности развития явлений во времени, - это результат аналитического выравнивания динамических рядов. Выравнивание ряда с помощью тех или иных функций (т. е. их подгонка к данным) в большинстве случаев оказывается удобным средством описания эмпирических данных. Это средство при соблюдении ряда условий можно применить и для прогнозирования. Процесс выравнивания состоит из следующих основных этапов:
Выбора типа кривой, форма которой соответствует характеру изменения динамического ряда;
Определения численных значений (оценивание) параметров кривой;
Апостериорного контроля качества выбранного тренда.
В современных ППП все перечисленные этапы реализуются одновременно, как правило, в рамках одной процедуры.
Аналитическое сглаживание с использованием той или иной функции позволяет получить выравненные, или, как их иногда не вполне правомерно называют, теоретические значения уровней динамического ряда, т. е. те уровни, которые наблюдались бы, если бы динамика явления полностью совпадала с кривой. Эта же функция с некоторой корректировкой или без нее, применяется в качестве модели для экстраполяции (прогноза).
Вопрос о выборе типа кривой является основным при выравнивании ряда. При всех прочих равных условиях ошибка в решении этого вопроса оказывается более значимой по своим последствиям (особенно для прогнозирования), чем ошибка, связанная со статистическим оцениванием параметров.
Поскольку форма тренда объективно существует, то при выявлении ее следует исходить из материальной природы изучаемого явления, исследуя внутренние причины его развития, а также внешние условия и факторы на него влияющие. Только после глубокого содержательного анализа можно переходить к использованию специальных приемов, разработанных статистикой.
Весьма распространенным приемом выявления формы тренда является графическое изображение временного ряда. Но при этом велико влияние субъективного фактора, даже при отображении выровненных уровней.
Наиболее надежные методы выбора уравнения тренда основаны на свойствах различных кривых, применяемых при аналитическом выравнивании. Такой подход позволяет увязать тип тренда с теми или иными качественными свойствами развития явления. Нам представляется, что в большинстве случаев практически приемлемым является метод, который основывается на сравнении характеристик изменения приростов исследуемого динамического ряда с соответствующими характеристиками кривых роста. Для выравнивания выбирается та кривая, закон изменения прироста которой наиболее близок к закономерности изменения фактических данных.
В табл. 4 приводится перечень наиболее употребительных при анализе экономических рядов видов кривых и указываются соответствующие «симптомы», по которым можно определить, какой вид кривых подходит для выравнивания.
При выборе формы кривой надо иметь в виду еще одно обстоятельство. Рост сложности кривой в целом ряде случаев может действительно увеличить точность описания тренда в прошлом, однако в связи с тем, что более сложные кривые содержат большее число параметров и более высокие степени независимой переменной, их доверительные интервалы будут в общем существенно шире, чем у более простых кривых при одном и том же периоде упреждения.
Таблица 4
Характер изменения показателей, основанных
на средних приростах для различных видов кривых
| Показатель | Характер изменения показателей во времени | Вид кривой |
| Примерно одинаковые | Прямая | |
| Линейно изменяются | Парабола второй степени | |
| Линейно изменяются | Парабола третьей степени | |
| Примерно одинаковые | Экспонента | |
| Линейно изменяются | Логарифмическая парабола | |
| Линейно изменяются | Модифицированная экспонента | |
| Линейно изменяются | Кривая Гомперца |
В настоящее время, когда использование специальных программ без особых усилий позволяет одновременно строить несколько видов уравнений, широко эксплуатируются формальные статистические критерии для определения лучшего уравнения тренда.
Из сказанного выше, по-видимому, можно сделать вывод о том, что выбор формы кривой для выравнивания представляет собой задачу, которая не решается однозначно, а сводится к получению ряда альтернатив. Окончательный выбор не может лежать в области формального анализа, тем более, если предполагается с помощью выравнивания не только статистически описать закономерность поведения уровня в прошлом, но и экстраполировать найденную закономерность в будущее. Вместе с тем различные статистические приемы обработки данных наблюдения могут принести существенную пользу, по крайней мере, с их помощью можно отвергнуть заведомо непригодные варианты и тем самым существенно ограничить поле выбора.
Рассмотрим наиболее используемые типы уравнений тренда:
1.Линейная форма тренда:
где - уровень ряда, полученный в результате выравнивания по прямой;
Начальный уровень тренда;
Средний абсолютный прирост; константа тренда.
Для линейной формы тренда характерно равенство так называемых первых разностей (абсолютных приростов) и нулевые вторые разности, т. е. ускорения.
2.Параболическая (полином 2-ой степени) форма тренда:
![]()
Для данного типа кривой постоянными являются вторые разности (ускорение), а нулевыми – третьи разности.
Параболическая форма тренда соответствует ускоренному или замедленному изменению уровней ряда с постоянным ускорением. Если < 0 и > 0, то квадратическая парабола имеет максимум, если > 0 и < 0 – минимум. Для отыскания экстремума первую производную параболы по t приравнивают 0 и решают уравнение относительно t.
3.Экспоненциальная форма тренда:
где - константа тренда; средний темп изменения уровня ряда.
При > 1 данный тренд может отражать тенденцию ускоренного и все более ускоряющегося возрастания уровней ряда. При < 1 – тенденцию постоянно, все более замедляющегося снижения уровней временного ряда.
4.Гиперболическая форма тренда (1 типа):
Данная форма тренда может отображать тенденцию процессов, ограниченных предельным значением уровня.
5.Логарифмическая форма тренда:
где - константа тренда.
Логарифмическим трендом может быть описана тенденция, проявляющаяся в замедлении роста уровней ряда динамики при отсутствии предельно возможного значения. При достаточно большом t логарифмическая кривая становится мало отличимой от прямой линии.
6.Обратнологарифмическая форма тренда:
![]()
7.Мультипликативная (степенная) форма тренда:
8.Обратная (гиперболическая 2 типа) форма тренда:
9.Гиперболическая форма тренда 3 типа:
10.Полином 3-ей степени:
![]()
Для всех нелинейных, относительно исходных переменных моделей (уравнений регрессии), а их здесь большинство, требуется провести вспомогательные преобразования, представленные в таблице ниже.
Таблица 5
Модели, сводящиеся к линейному тренду
| Модель | Уравнение | Преобразование |
| Мультипликативная (Степенная) | ||
| Гиперболическая I типа | ||
| Гиперболическая II типа | ||
| Гиперболическая III типа | ||
| Логарифмическая | ||
| Обратнологарифмическая |
В формулах, перечисленных в таблице, как и во всех формулах, описывающих модель тренда, есть коэффициенты уравнений.
Однако, при практическом использовании линеаризации с помощью преобразования исследуемых переменных следует иметь ввиду, что оценки параметров, полученных линеаризацией с помощью М.Н.К. (метод наименьших квадратов), минимизируют сумму квадратов отклонений для преобразованных, а не исходных переменных. Поэтому полученные с помощью линеаризации зависимостей оценки нуждаются в уточнении.
Для решения поставленной задачи по аналитическому сглаживанию динамических рядов в системе STATISTICA нам потребуется создать несколько новых дополнительных переменных, необходимых для выполнения дальнейшей работы, а также осуществить некоторые вспомогательные операции по преобразованию нелинейных моделей тренда в линейные.
Итак, нам предстоит построить уравнение тренда, которое по существу является уравнением регрессии, в котором в качестве фактора выступает «время». Прежде всего, мы создадим переменную «Т», содержащую моменты времени четвертого периода. Так как четвертый период включает 12 лет, то переменная «Т» будет состоять из натуральных чисел от 1 до 12, соответствующих месяцам года.
Кроме того, для работы с некоторыми моделями тренда нам потребуется еще несколько переменных, содержание которых можно понять из их обозначения. Это переменные, получаемые из временного ряда: «Т^2», «Т^3», «1/Т» и «ln T». А также переменные, получаемые из исходных данных за четвертый период: «1/Import4» и «ln Import4». Также необходимо создать такую же таблицу для экспорта. Все это предлагается сделать на новом рабочем листе, скопировав туда данные за 4-й период.
Для этого воспользуемся уже известным нам меню Workbook/Insert.
В итоге получаем следующие электронные таблицы.

Рис. 38. Таблица со вспомогательными переменными для импорта

Рис. 39. Таблица со вспомогательными переменными для экспорта
Для аналитического выравнивания рядов динамики мы будем использовать модуль Multiple Regression в меню Statistics. Рассмотрим пример построения графического изображения и определение численных параметров тренда, выраженного линейной зависимостью.

Рис. 40. Модуль Multiple Regression в меню Statistics
Для выбора зависимых и независимых переменных воспользуемся кнопкой Variables.
В открывшемся окне в левом информационном поле мы выбираем зависимую переменную Y t , (в нашем случае это Import 4 – данные по четвертому периоду). Номера выбранных зависимых переменных отображаются внизу в поле Dependent var. (or list for batch). Соответственно в правом поле мы выбираем независимые переменные (в нашем случае одну – время «Т»). Номера выбранных независимых переменных высвечиваются внизу в поле Independent variable list.
После того, как завершен выбор переменных, нажимаем ОК. Система выдает окно с обобщенными результатами расчета параметров тренда (далее они будут рассмотрены более подробно) и возможностью выбора направления для последующего детального анализа. Заметим, что значение оценки, высвеченное красным цветом, указывает на статистическую значимость результатов.

Рис. 41. Закладка Advanced
На закладке располагается несколько кнопок, позволяющих получить максимально детализированные сведения по интересующему нас направлению анализа. При нажатии на нее получаем две таблицы с результатами регрессионного анализа. В первой представлены результаты расчета параметров уравнения регрессии, во второй – основные показатели уравнения.

Рис. 42. Основные показатели уравнения для данных импорта за четвертый период (линейный тренд)
Здесь N = – объем результативной переменной. В верхнем поле расположены показатели R, , Adjusted R, F, p, Std.Error of Estimate , означающие соответственно теоретическое корреляционное отношение, коэффициент детерминации, уточненный коэффициент детерминации, расчетное значение критерия Фишера (в скобках дано число степеней свободы), уровень значимости, стандартная ошибка уравнения (эти же показатели можно увидеть во второй таблице). В самой таблице нас интересуют столбец В , в котором расположены коэффициенты уравнения, столбец t и столбец p-level , обозначающие расчетное значение t-критерия и расчетный уровень значимости, необходимые для оценки значимости параметров уравнения. При этом система помогает пользователю: когда процедура предполагает проверку на значимость, STATISTICA выделяет значимые элементы красным цветом (т.е. отвергается нулевая гипотеза о равенстве параметров нулю). В нашем случае |t факт | > t табл для обоих параметров, следовательно они значимы.

Рис. 43. Параметры уравнения регрессии для данных импорта за четвертый период (линейный тренд)
Для оценки статистической значимости уравнения в целом на закладке Advanced воспользуемся кнопкой ANOVA (Goodness Of Fit), позволяющей получить таблицу дисперсионного анализа и значение F-критерия Фишера.

Рис. 44. Таблица дисперсионного анализа
Sums of Squares – сумма квадратов отклонений: на пересечении со строкой Regression – сумма квадратов отклонений теоретических (полученных по уравнению регрессии) значений признака от средней величины. Эта сумма квадратов используется для расчета факторной, объясненной дисперсии зависимой переменной. На пересечении со строкой Residual – сумма квадратов отклонений теоретических и фактических значений переменной (для расчета остаточной, необъясненной дисперсии), Total – отклонений фактических значений переменной от средней величины (для расчета общей дисперсии). Столбец df – число степеней свободы, Means Squares обозначает дисперсию: на пересечении со строкой Regression – факторную, со строкой Residual - остаточную, F – критерий Фишера, используемый для оценки общей значимости уравнения и коэффициента детерминации, p-level – уровень значимости.
Параметры уравнения тренда в STATISTICA, как и в большинстве других программ, рассчитываются по метод наименьших квадратов (МНК).
Метод позволяет получить значения параметров, при которых обеспечивается минимизация суммы квадратов отклонений фактических уровней от сглаженных, т. е. полученных в результате аналитического выравнивания.
Математический аппарат метода наименьших квадратов описан в большинстве работ по математической статистике, поэтому нет необходимости подробно на нем останавливаться. Напомним только некоторые моменты. Так, для нахождения параметров линейного тренда (2.10) необходимо решить систему уравнений:

Данная система уравнений упрощается, если значения t подобрать таким образом, чтобы их сумма равнялась нулю, т. е. начало отсчета времени перенести в середину рассматриваемого периода. Очевидно, что перенос начала координат имеет смысл только при ручной обработке динамического ряда.
Если , то , .
В общем виде систему уравнений для нахождения параметров полинома ![]() можно записать как
можно записать как

При сглаживании временного ряда по экспоненте (которая часто используется в экономических исследованиях) для определения параметров следует применить метод наименьших квадратов к логарифмам исходных данных.
![]()
После переноса начала отсчета времени в середину ряда получают:
![]()
следовательно:

Если наблюдаются более сложные изменения уровней временного ряда и выравнивание осуществляется по показательной функции вида , то параметры определяются в результате решения следующей системы уравнений:

В практике исследования социально-экономических явлений исключительно редко встречаются динамические ряды, характеристики которых полностью соответствуют признакам эталонных математических функций. Это обусловлено значительным числом факторов разного характера, влияющих на уровни ряда и тенденцию их изменения.
На практике чаще всего строят целый ряд функций, описывающих тренд, а затем выбирают лучшую на основе того или иного формального критерия.

Рис. 45. Закладка Residuals/Assumptions/Prediction
Здесь воспользуемся кнопкой Perform Residual Analysis, открывающую модуль анализа остатков. Под остатками (Residuals) в данном случае понимается отклонение исходных значений динамического ряда от прогнозируемых, в соответствии с выбранным уравнением тренда. Сразу же переходим к закладке Advanced.

Рис. 46. Закладка Advanced в Perform Residual Analysis
Воспользуемся кнопкой Summary: Residuals & Predicted, позволяющую получить одноименную таблицу, которая содержит исходные значения динамического ряда Observed Value, прогнозируемые значения по выбранной модели тренда Predicted Value, отклонения прогнозных значений от исходных Residual Value, а также различные специальные показатели и стандартизированные значения. Также в таблице представлены максимальное, минимальное значения, средняя и медиана по каждому столбцу.

Рис. 47. Таблица, содержащая показатели и специальные значения для линейного тренда
В данной таблицы наибольший интерес для нас представляет столбец Residual Value, значения которого в дальнейшем используются для характеристики качества подбора тренда, а также столбец Predicted Value, который содержит прогнозные значения динамического ряда в соответствии с выбранной моделью тренда (в нашем случае – линейной).
Далее построим график исходного временного ряда совместно с вычисленными в соответствии с линейным уравнением тренда прогнозными значениями для четвертого периода. Для этого лучше всего скопировать значения из столбца Predicted Value в таблицу, в которой были созданы переменные для построения трендов.

Рис. 48. Третий период динамического ряда импорта (млрд. $) и линейный тренд
Итак, мы получили все необходимые результаты расчета параметров тренда, выраженного линейной моделью, для четвертого периода исходного динамического ряда, а также построили график данного ряда, совмещенный с линией тренда. Далее будут представлены остальные модели трендов.
Следует заметить, что в результате линеаризации степенной и экспоненциальной функций STATISTICA возвращает значение линеаризованной функции равное , поэтому для дальнейшего использования их надо преобразовать с помощью следующей элементарной транзакции , в том числе и для построения графических изображений. Для гиперболических функций, а также для обратнологарифмической функции необходимо выполнить преобразование вида .
Для этого также целесообразно создать дополнительные переменные и получить их с помощью формул на основе уже имеющихся переменных.
Итак, при решении задачи с помощью процедуры Multiple Regression, необходимо в качестве переменных выбрать натуральные логарифмы исходного ряда и оси времени.

Рис. 49. Основные показатели уравнения для данных импорта за третий период (степенная модель)

Рис. 50. Параметры уравнения регрессии для данных импорта за третий период (степенная модель)

Рис. 51. Таблица дисперсионного анализа

Рис. 52. Таблица, содержащая показатели и специальные значения для степенной модели
Затем, как и в случае с линейным трендом, копируем значения из столбца Predicted Value в таблицу, но там для этого строим еще одну переменную, в которой получаем прогнозные значения по степенной функции с помощью преобразования .

Рис. 53. Создание дополнительной переменной

Рис. 54. Таблица со всеми переменными

Рис. 55. Третий период динамического ряда импорта (млрд. $) и степенная модель

Рис.56. Основные показатели уравнения для данных импорта за третий период (экспоненциальная модель)

Рис. 57. Третий период динамического ряда импорта (млрд. $) и экспоненциальная модель

Рис.58. Основные показатели уравнения для данных импорта за третий период (обратная модель)

Рис. 59. Третий период динамического ряда импорта (млрд. $) и обратная модель

Рис. 60. Основные показатели уравнения для данных импорта за третий период (полином второй степени)

Рис. 61. Третий период динамического ряда импорта (млрд. $) и полином второй степени

Рис. 62. Основные показатели уравнения для данных импорта за третий период (полином 3-й степени)

Рис. 63. Третий период динамического ряда импорт (млрд. $) и полином 3-й степени

Рис. 64. Основные показатели уравнения для данных импорта за третий период (гипербола 1-ого вида)

Рис. 65. Третий период динамического ряда импорт (млрд. $) и гипербола 1-ого вида

Рис. 66. Основные показатели уравнения для данных импорта за третий период (гипербола 3 типа)

Рис. 67. Третий период динамического ряда импорт и гипербола 3 типа

Рис. 68. Основные показатели уравнения для данных импорта за третий период (логарифмическая модель)

Рис. 69. Третий период динамического ряда импорт (млрд. $) и логарифмическая модель

Рис. 70. Основные показатели уравнения для данных импорта за третий период (обратнологарифмическая модель)

Рис. 71. Третий период динамического ряда импорт (млрд. $) и обратнологарифмическая модель
Затем построим таблицу со вспомогательными переменными для построения трендов для экспорта.

Рис. 72. Таблица со вспомогательными переменными
Проделаем те же операции что и для четвертого период импорта.

Рис. 73. Основные показатели уравнения для данных экспорта за третий период (линейная модель)

Рис. 74. Третий период динамического ряда экспорта (млрд. $) и линейная модель

Рис. 75. Основные показатели уравнения для данных экспорта за третий период (степенная модель тренда)

Рис. 76. Третий период динамического ряда экспорта и степенная модель

Рис. 77. Основные показатели уравнения для данных экспорта за третий период (экспоненциальная модель тренда)

Рис. 78. Третий период динамического ряда экспорта (млрд. $) и экспоненциальная модель

Рис. 79. Основные показатели уравнения для данных экспорта за третий период (обратная модель тренда)
 Рис. 80. Третий период динамического ряда экспорта (млрд. $) и обратная модель
Рис. 80. Третий период динамического ряда экспорта (млрд. $) и обратная модель

Рис. 81. Основные показатели уравнения для данных экспорта за третий период (полином второй степени)

Рис. 82. Третий период динамического ряда экспорта (млрд. $) и полином второй степени

Рис. 83. Основные показатели уравнения для данных экспорта за третий период (полином третей степени)

Рис. 84. Третий период динамического ряда экспорта (млрд. $) и полином третей степени

Рис. 85. Основные показатели уравнения для данных экспорта за третий период (гипербола 1-ого вида)

Рис. 86. Третий период динамического ряда экспорта и гипербола 1-ого типа

Рис. 87. Основные показатели уравнения для данных экспорта за третий период (гипербола 3-ого вида)

Рис. 88. Третий период динамического ряда экспорта (млрд. $) и гипербола 3-ого типа

Рис. 89. Основные показатели уравнения для данных экспорта за третий период (логарифмическая модель)

Рис. 90. Третий период динамического ряда экспорта (млрд. $) и логарифмическая модель

Рис. 91. Основные показатели уравнения для данных экспорта за третий период (обратнологарифмическая модель)

Рис. 91. Третий период динамического ряда экспорта (млрд. $) и обратнологарифмическая модель
Выбор наилучшего тренда
Как уже отмечалось, проблема выбора формы кривой - одна из основных проблем, с которой сталкиваются при выравнивании ряда динамики. Решение этой проблемы во многом определяет результаты экстраполяции тренда. В большинстве специализированных программ для выбора лучшего уравнения тренда предоставляется возможность воспользоваться следующими критериями:
Минимальное значение среднеквадратической ошибки тренда:
 ,
,
где - фактические уровни ряда динамики;
Уровни ряда, определенные по уравнению тренда;
n - число уровней ряда;
p - число факторовв уравнении тренда.
- минимальное значение остаточной дисперсии:
![]()
Минимальное значение средней ошибки аппроксимации;
Минимальное значение средней абсолютной ошибки;
Максимальное значение коэффициента детерминации;
Максимальное значение F- критерия Фишера:
 : ,
: ,
где k – число степеней свободы факторной дисперсии,равное числу независимых переменных (признаков-факторов) в уравнении;
n-k-1 - число степеней свободы остаточной дисперсии.
Применение формального критерия для выбора формы кривой, по-видимому, даст практически пригодные результаты в том случае, если отбор будет проходить в два этапа. На первом этапе отбираются зависимости, пригодные с позиции содержательного подхода к задаче, в результате чего происходит ограничение круга потенциально приемлемых функций. На втором этапе для этих функций подсчитываются значения критерия и выбирается та из кривых, которой соответствует минимальное его значение.
В данном пособии для идентификации тренда используется формальный метод, который основывается на использовании численного критерия. В качестве такого критерия рассматривается максимальный коэффициент детерминации:
 .
.
Расшифровка обозначений и формулы данных показателей даны в предыдущих разделах. Коэффициент детерминации показывает, какая доля общей дисперсии результативного признака обусловлена вариацией признака – фактора. В таблицах STATISTICA он обозначается как R?.
В следующей ниже таблице будут представлены уравнения моделей трендов и коэффициенты детерминации данных импорта.
Таблица 6
Уравнения моделей трендов и коэффициенты детерминации Import.
Сопоставив значения коэффициентов детерминации для различных типов кривых можно сделать вывод о том, что для исследуемого третьего периода лучшей формой тренда будет полином третей степени для импорта и для экспорта.
Далее необходимо проанализировать выбранную модель тренда с точки зрения ее адекватности реальным тенденциям исследуемого временного ряда через оценку надежности полученных уравнений трендов по F-критерию Фишера. В данном случае расчетное значение критерия Фишера для импорта равно 16,573; для экспорта – 13,098, а табличное значение при уровне значимости равно 3,07. Следовательно, эта модель тренда признается адекватно отражающей реальную тенденцию изучаемого явления.
Для наглядной иллюстрации тенденций изменения цены применяется линия тренда. Элемент технического анализа представляет собой геометрическое изображение средних значений анализируемого показателя.
Рассмотрим, как добавить линию тренда на график в Excel.
Добавление линии тренда на график
Для примера возьмем средние цены на нефть с 2000 года из открытых источников. Данные для анализа внесем в таблицу:


Линия тренда в Excel – это график аппроксимирующей функции. Для чего он нужен – для составления прогнозов на основе статистических данных. С этой целью необходимо продлить линию и определить ее значения.
Если R2 = 1, то ошибка аппроксимации равняется нулю. В нашем примере выбор линейной аппроксимации дал низкую достоверность и плохой результат. Прогноз будет неточным.
Внимание!!! Линию тренда нельзя добавить следующим типам графиков и диаграмм:
- лепестковый;
- круговой;
- поверхностный;
- кольцевой;
- объемный;
- с накоплением.
Уравнение линии тренда в Excel
В предложенном выше примере была выбрана линейная аппроксимация только для иллюстрации алгоритма. Как показала величина достоверности, выбор был не совсем удачным.
Следует выбирать тот тип отображения, который наиболее точно проиллюстрирует тенденцию изменений вводимых пользователем данных. Разберемся с вариантами.
Линейная аппроксимация
Ее геометрическое изображение – прямая. Следовательно, линейная аппроксимация применяется для иллюстрации показателя, который растет или уменьшается с постоянной скоростью.
Рассмотрим условное количество заключенных менеджером контрактов на протяжении 10 месяцев:

На основании данных в таблице Excel построим точечную диаграмму (она поможет проиллюстрировать линейный тип):

Выделяем диаграмму – «добавить линию тренда». В параметрах выбираем линейный тип. Добавляем величину достоверности аппроксимации и уравнение линии тренда в Excel (достаточно просто поставить галочки внизу окна «Параметры»).

Получаем результат:

Обратите внимание! При линейном типе аппроксимации точки данных расположены максимально близко к прямой. Данный вид использует следующее уравнение:
y = 4,503x + 6,1333
- где 4,503 – показатель наклона;
- 6,1333 – смещения;
- y – последовательность значений,
- х – номер периода.
Прямая линия на графике отображает стабильный рост качества работы менеджера. Величина достоверности аппроксимации равняется 0,9929, что указывает на хорошее совпадение расчетной прямой с исходными данными. Прогнозы должны получиться точными.
Чтобы спрогнозировать количество заключенных контрактов, например, в 11 периоде, нужно подставить в уравнение число 11 вместо х. В ходе расчетов узнаем, что в 11 периоде этот менеджер заключит 55-56 контрактов.
Экспоненциальная линия тренда
Данный тип будет полезен, если вводимые значения меняются с непрерывно возрастающей скоростью. Экспоненциальная аппроксимация не применяется при наличии нулевых или отрицательных характеристик.
Построим экспоненциальную линию тренда в Excel. Возьмем для примера условные значения полезного отпуска электроэнергии в регионе Х:

Строим график. Добавляем экспоненциальную линию.

Уравнение имеет следующий вид:
y = 7,6403е^-0,084x
- где 7,6403 и -0,084 – константы;
- е – основание натурального логарифма.
Показатель величины достоверности аппроксимации составил 0,938 – кривая соответствует данным, ошибка минимальна, прогнозы будут точными.
Логарифмическая линия тренда в Excel
Используется при следующих изменениях показателя: сначала быстрый рост или убывание, потом – относительная стабильность. Оптимизированная кривая хорошо адаптируется к подобному «поведению» величины. Логарифмический тренд подходит для прогнозирования продаж нового товара, который только вводится на рынок.
На начальном этапе задача производителя – увеличение клиентской базы. Когда у товара будет свой покупатель, его нужно удержать, обслужить.
Построим график и добавим логарифмическую линию тренда для прогноза продаж условного продукта:

R2 близок по значению к 1 (0,9633), что указывает на минимальную ошибку аппроксимации. Спрогнозируем объемы продаж в последующие периоды. Для этого нужно в уравнение вместо х подставлять номер периода.
Например:
| Период | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| Прогноз | 1005,4 | 1024,18 | 1041,74 | 1058,24 | 1073,8 | 1088,51 | 1102,47 |
Для расчета прогнозных цифр использовалась формула вида: =272,14*LN(B18)+287,21. Где В18 – номер периода.
Полиномиальная линия тренда в Excel
Данной кривой свойственны переменные возрастание и убывание. Для полиномов (многочленов) определяется степень (по количеству максимальных и минимальных величин). К примеру, один экстремум (минимум и максимум) – это вторая степень, два экстремума – третья степень, три – четвертая.
Полиномиальный тренд в Excel применяется для анализа большого набора данных о нестабильной величине. Посмотрим на примере первого набора значений (цены на нефть).

Чтобы получить такую величину достоверности аппроксимации (0,9256), пришлось поставить 6 степень.
Зато такой тренд позволяет составлять более-менее точные прогнозы.
Когда тип тренда установлен, необходимо вычислить оптимальные значения параметров тренда исходя из фактических уровней. Для этого обычно используют метод наименьших квадратов (МНК). Его значение уже рассмотрено в предыдущих главах учебного пособия, в данном случае оптимизация состоит в минимизации суммы квадратов отклонений фактических уровней ряда от выравненных уровней (от тренда). Для каждого типа тренда МНК дает систему нормальных уравнений, решая которую вычисляют параметры тренда. Рассмотрим лишь три такие системы: для прямой, для параболы 2-го порядка и для экспоненты. Приемы определения параметров других типов тренда рассматриваются в специальной монографической литературе.
Для линейного тренда нормальные уравнения МНК имеют вид:


Нормальные уравнения МНК для экспоненты имеют следующий вид:

По данным табл. 9.1 рассчитаем все три перечисленных тренда для динамического ряда урожайности картофеля с целью их сравнения (см. табл. 9.5).
Таблица 9.5
Расчет параметров трендов

Согласно формуле (9.29) параметры линейного тренда равны а = 1894/11 = 172,2 ц/га; b = 486/110 = 4,418 ц/га. Уравнение линейного тренда имеет вид:
у ̂ = 172,2 + 4,418t , где t = 0 в 1987 г Это означает,что средний фактический и выравненный уровень, отнесенный к середине периода, т.е. к 1991 г., равен 172 ц с 1 ra a среднегодовой прирост составляет 4,418 ц/га в год
Параметры параболического тренда согласно (9.23) равны- b = 4,418; a = 177,75; с = -0,5571. Уравнение параболического тренда имеет вид у̃ = 177,75 + 4,418t - 0.5571t 2 ; t = 0 в 1991 г. Это означает, что абсолютный прирост урожайности замедляется в среднем на 2·0,56 ц/га в год за год. Сам же абсолютный прирост уже не является константой параболического тренда, а является средней величиной за период. В год, принятый за начало отсчета т.е. 1991 г., тренд проходит через точку с ординатой 77,75 ц/га; Свободный член параболического тренда не является средним уровнем за период. Параметры экспоненциального тренда вычисляются по формулам(9.32) и (9.33) lnа = 56,5658/11 = 5,1423; потенцируя, получаем а = 171,1; lnk = 2,853:110 = 0,025936; потенцируя, получаем k = 1,02628.
Уравнение экспоненциального тренда имеет вид: y ̅ = 171,1·1,02628 t .
Это означает, что среднегодовой темп поста урожайности за период составил 102,63%. В точке принятК начало отсчета, тренд проходит точку с ординатой 171,1 ц/га.
Рассчитанные по уравнениям трендов уровни записаны в трех последних графах табл. 9.5. Как видно по этим данным. расчетные значения уровней по всем трем видам трендов различаются ненамного, так как и ускорение параболы, и темп роста экспоненты невелики. Существенное отличие имеет парабола - рост уровней с 1995 г. прекращается, в то время как при линейном тренде уровни растут и далее, а при экспоненте их ост ускоряется. Поэтому для прогнозов на будущее эти три тренда неравноправны: при экстраполяции параболы на будущие годы уровни резко разойдутся с прямой и экспонентой, что видно из табл. 9.6. В этой таблице представлена распечатка решения на ПЭВМ по программе «Statgraphics» тех же трех трендов. Отличие их свободных членов от приведенных выше объясняется тем, что программа нумерует года не от середины, а от начала, так что свободные члены трендов относятся к 1986 г., для которого t = 0. Уравнение экспоненты на распечатке оставлено в логарифмированном виде. Прогноз сделан на 5 лет вперед, т.е. до 2001 г.. При изменении начала координат (отсчета времени) в уравнении параболы меняется и средний абсолютной прирост, параметр b . так как в результате отрицательного ускорения прирост все время сокращается, а его максимум - в начале периода. Константой параболы является только ускорение.

В строке «Data» приводятся уровни исходного ряда; «Forecast summary» означает сводные данные для прогноза. В следующих строках - уравнения прямой, параболы, экспоненты - в логарифмическом виде. Графа ME означает среднее расхождение между уровнями исходного ряда и уровнями тренда (выравненными). Для прямой и параболы это расхождение всегда равно нулю. Уровни экспоненты в среднем на 0,48852 ниже уровней исходного ряда. Точное совпадение возможно, если истинный тренд - экспонента; в данном случае совпадения нет, но различие, мало. Графа МАЕ -это дисперсия s 2 - мера колеблемости фактических уровней относительно тренда, о чем сказано в п. 9.7. Графа МАЕ - среднее линейное отклонение уровней от тренда по модулю (см. параграф 5.8); графа МАРЕ - относительное линейное отклонение в процентах. Здесь они приведены как показатели пригодности выбранного вида тренда. Меньшую дисперсию и модуль отклонения имеет парабола: она за период 1986 - 1996 гг. ближе к фактическим уровням. Но выбор типа тренда нельзя сводить лишь к этому критерию. На самом деле замедление прироста есть результат большого отрицательного отклонения, т. е. неурожая в 1996 г.
Вторая половина таблицы - это прогноз уровней урожайности по трем видам трендов на годы; t = 12, 13, 14, 15 и 16 от начала отсчета (1986 г.). Прогнозируемые уровни по экспоненте вплоть до 16-го года ненамного выше,.чем по прямой. Уровни тренда-параболы - снижаются, все более расходясь с другими трендами.
Как видно в табл. 9.4, при вычислении параметров тренда уровни исходного ряда входят с разными весами - значениями t p и их квадратов. Поэтому влияние колебаний уровней на параметры тренда зависит от того, на какой номер года приходится урожайный либо неурожайный год. Если резкое отклонение приходится на год с нулевым номером (t i = 0 ), то оно никакого влияния на параметры тренда не окажет, а если попадет на начало и конец ряда, то повлияет сильно. Следовательно, однократное аналитическое выравнивание неполно освобождает параметры тренда от влияния колеблемости, и при сильных колебаниях они могут быть сильно искажены, что в нашем примере случилось с параболой. Для дальнейшего исключения искажающего влияния колебаний на параметры тренда следует применить метод многократного скользящего выравнивания.
Этот прием состоит в том, что параметры тренда вычисляются не сразу по всему ряду, а скользящим методом, сначала за первые т периодов времени или моментов, затем за период от 2-го до т + 1, от 3-го до (т + 2)-го уровня и т.п. Если число исходных уровней ряда равно п, а длина каждой скользящей базы расчета параметров равна т, то число таких скользящих баз t или отдельных значений параметров, которые будут по ним определены, составит:
L = п + 1 - т.
Применение методики скользящего многократного выравнивания рассматривать, как видно из приведенных расчетов, возможно только при достаточно большом числе уровней ряда, как правило 15 и более. Рассмотрим эту методику на примере данных табл. 9.4 -динамики цен на нетопливные товары развивающихся стран, что опять же дает возможность читателю участвовать в небольшом научном исследовании. На этом же примере продолжим и методику прогнозирования в разделе 9.10.
Если вычислять в нашем ряду параметры по 11 -летним периодам (по 11 уровням), то t = 17 + 1 - 11 = 7. Смысл многократного скользящего выравнивания в том, что при последовательных сдвигах базы расчета параметров на концах ее и в середине окажутся разные уровни с разными по знаку и величине отклонениями от тренда. Поэтому при одних сдвигах базы параметры будут завышаться, при других - занижаться, а при последующем усреднении значений параметров по всем сдвигам базы расчета произойдет дальнейшее взаимопогашение искажений параметров тренда колебаниями уровней.
Многократное скользящее выравнивание не только позволяет получить более точную и надежную оценку параметров тренда, но и осуществить контроль правильности выбора типа уравнения тренда. Если окажется, что ведущий параметр тренда, его константа при расчете по скользящим базам не беспорядочно колеблется, а систематически изменяет свою величину существенным образом, значит, тип тренда был выбран неверно, данный параметр константой не является.
Что касается свободного члена при многократном выравнивании, то нет необходимости и, более того, просто неверно вычислять его величину как среднюю по всем сдвигам базы, ибо при таком способе отдельные уровни исходного ряда входили бы в расчет средней с разными весами, и сумма выравненных уровней разошлась бы с суммой членов исходного ряда. Свободный член тренда - это средняя величина уровня за период, при условии отсчета времени от середины периода. При отсчете от начала, если первый уровень t i = 1, свободный член будет равен: a 0 = у ̅ - b ((N-1)/2). Рекомендуется длину скользящей базы расчета параметров тренда выбирать не менее 9-11 уровней, чтобы в достаточной мере погасить колебания уровней. Если исходный ряд очень длинный, база может составлять до 0,7 - 0,8 его длины. Для устранения влияния долго-периодических (циклических) колебаний на параметры тренда, число сдвигов базы должно быть равно или кратно длине цикла колебаний. Тогда начало и конец базы будут последовательно «пробегать» все фазы цикла и при усреднении параметра по всем сдвигам его искажения от циклических колебаний будут взаимопогашаться. Другой способ - взять длину скользящей базы, равной длине цикла, чтобы начало базы и конец базы всегда приходились на одну и ту же фазу цикла колебаний.
Поскольку по данным табл. 9.4, уже было установлено, что тренд имеет линейную форму, проводим расчет среднегодового абсолютного прироста, т. е. параметра b уравнения линейного тренда скользящим способом по 11-летним базам (см. табл. 9.7). В ней же приведен расчет данных, необходимых для последующего изучения колеблемости в параграфе 9.7. Остановимся подробнее на методике многократного выравнивания по скользящим базам. Рассчитаем параметр b по всем базам:

Таблица 9.7
Многократное скользящее выравнивание по прямой
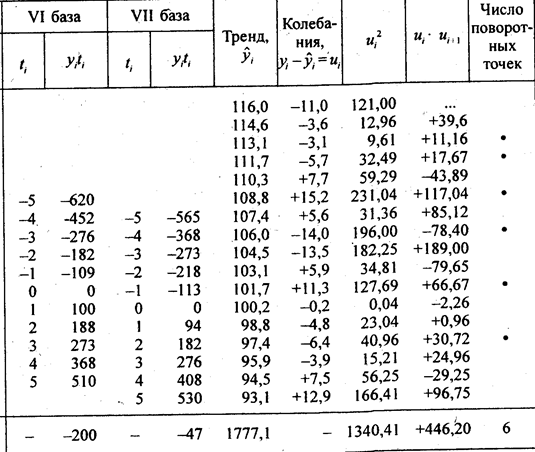

Уравнение тренда: у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г. Итак, индекс цен в среднем за год снижался на 1,433 пункта. Однократное выравнивание по всем 17 уровням может исказить этот параметр, ибо начальный уровень содержит значительное отрицательное отклонение, а конечный уровень - положительное. В самом деле, однократное выравнивание дает величину среднегодового изменения индекса всего на 0,953 пункта.
9.7. Методика изучения и показатели колеблемости
Если при изучении и измерении тенденции динамики колебания уровней играли лишь роль помех, «информационного шума», от которого следовало по возможности абстрагироваться, то в дальнейшем сама колеблемость становится предметом статистического исследования. Значение изучения колебаний уровней динамического ряда очевидно: колебания урожайности, продуктивности скота, производства мяса экономически нежелательны, так как потребность в продукции агрокомплекса постоянна. Эти колебания следует уменьшать, применяя прогрессивную технологию и другие меры. Напротив, сезонные колебания объемов производства зимней и летней обуви, одежды, мороженого, зонтиков, коньков - необходимы и закономерны, так как спрос на эти товары тоже колеблется по сезонам и равномерное производство требует лишних затрат на хранение запасов. Регулирование рыночной экономики как со стороны государства, так и производителей в значительной мере состоит в регулировании колебаний экономических процессов.
Типы колебаний статистических показателей весьма разнообразны, но все же можно выделить три основных: пилообразную или маятниковую колеблемость, циклическую долгопериодическую и случайно распределенную во времени колеблемость. Их свойства и отличия друг от друга хорошо видны при графическом изображении рис. 9.2.
Пилообразная или маятниковая колеблемость состоит в попеременных отклонениях уровней от тренда в одну и в другую сторону. Таковы автоколебания маятника. Такие автоколебания можно наблюдать в динамике урожайности при невысоком уровне агротехники: высокий урожай при благоприятных условиях погоды выносит из почвы больше питательных веществ, чем их образуется естественным путем за год; почва обедняется, что вызывает снижение следу- ющего урожая ниже тренда, он выносит меньше питательных веществ, чем образуется за год, плодородие возрастает и т.д.

Рис. 9.2. Виды колебаний
Циклическая долгопериодическая колеблемость свойственна, например, солнечной активности (10-11-летние циклы), а значит, и связанным с ней на Земле процессам - полярным сияниям, грозовой деятельности, урожайности отдельных культур в ряде районов, некоторым заболеваниям людей, растений. Для этого типа характерны редкая смена знаков отклонений от тренда и кумулятивный (накапливающийся) эффект отклонений одного знака, который может тяжело отражаться на экономике. Зато колебания хорошо прогнозируются.
Случайно распределенная во времени колеблемость - нерегулярная, хаотическая. Она может возникать при наложении (интерференции) множества колебаний с разными по длительности циклами. Но может возникать в результате столь же хаотической колеблемости главной причины существования колебаний, например суммы осадков за летний период, температуры воздуха в среднем за месяц в разные годы.
Для определения типа колебаний применяются графическое изображение, метод «поворотных точек» М. Кендэла, вычисление коэффициентов автокорреляции отклонений от тренда. Эти методы будут рассмотрены далее.
Основными показателями, характеризующими силу колеблемости уровней, выступают уже известные по главе 5 показатели, характеризующие вариацию значений признака в пространственной совокупности. Однако вариация в пространстве и колеблемость во времени принципиально различны. Прежде всего различны их основные причины. Вариация значений признака у одновременно существующих единиц возникает из-за различий в условиях существования единиц совокупности. Например, разная урожайность картофеля в совхозах области в 1990 г. вызвана различиями в плодородии почв, в качестве семян, в агротехнике. А вот суммы эффективных температур за вегетационный период и осадков не являются причинами пространственной вариации, так как в одном и том же году на территории области эти факторы почти не варьируют. Напротив, главными причинами колебания урожайности картофеля в области за ряд лет как раз являются колебания метеорологических факторов, а качество почв колебаний почти не имеет. Что же касается общего прогресса агротехники, то он является причиной тренда, но не колеблемости.
Второе коренное отличие состоит в том, что значения варьирующего признака в пространственной совокупности можно считать в основном не зависимыми друг от друга, напротив, уровни динамического ряда, как правило, являются зависимыми: это показатели развивающегося процесса, каждая стадия которого связана с предыдущими состояниями.
В-третьих, вариация в пространственной совокупности измеряется отклонениями индивидуальных значений признака от среднего значения, а колеблемость уровней динамического ряда измеряется не их отличиями от среднего уровня (эти отличия включают и тренд, и колебания), а отклонениями уровней от тренда.
Поэтому лучше использовать разные термины: различия признака в пространственной совокупности называть только вариацией, но не колебаниями: никто же не станет называть различия численности населения Москвы, Петербурга, Киева и Ташкента «колебаниями числа жителей»! Отклонения уровней динамического ряда от тренда будем называть всегда колеблемостью. Колебания всегда происходят во времени, не может существовать колебаний вне времени, в фиксированный момент.
На основе качественного содержания понятия колеблемости строится и система ее показателей. Показателями силы колебании уровней являются: амплитуда отклонений уровней отдельных периодов или моментов от тренда (по модулю), среднее абсолютное отклонение уровней от тренда (по модулю), среднее квадратическое откло;-нение уровней от тренда. Относительные меры колеблемости: относительное линейное отклонение от тренда и коэффициент колеблемости - аналог коэффициента вариации.
Особенностью методики вычисления средних отклонений от тренда является необходимость учета потерь степеней свободы колебаний на величину, равную числу параметров уравнения тренда. Например, прямая линия имеет два параметра, и, как известно из геометрии, через любые две точки можно провести прямую линию. Значит, имея лишь два уровня, мы проведем линию тренда точно через эти два уровня, и никаких отклонений уровней от тренда не окажется, хотя на самом деле и эти два уровня включали колебания, не были свободны от действия факторов колеблемости. Парабола второго порядка пройдет точно через любые три точки и т.п.
Учитывая потерю степеней свободы, основные абсолютные показатели колеблемости вычисляются по формулам (9.34) и (9.35):
среднее линейное отклонение
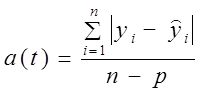 (9.34)
(9.34)
среднее квадратичное отклонение
 (9.35)
(9.35)
где y i - фактический уровень;
y ̂ i - выравненный уровень, тренд;
n - число уровней;
р - число параметров тренда.
Знак времени «t » в скобках после показателя означает, что это показатель не обычной пространственной вариации, как в главе V, а показатель колеблемости во времени.
Относительные показатели колеблемости вычисляются делением абсолютных показателей на средний уровень за весь изучаемый период. Расчет показателей колеблемости проведем по результатам анализа динамики индекса цен (см. табл. 9.7). Тренд примем по результатам многократного скользящего выравнивания, т. е. у ̂ = 104,53 - 1,433t ; t = 0 в 1987 г.
1. Амплитуда колебаний составила от -14,0 в 1986 г. до +15,2 в 1984 г., т.е. 29,2 пункта.
2. Среднее линейное отклонение по модулю найдем, сложив модули |u i | (их сумма равна 132,3), и разделив на (п - р), согласно формуле (9.34):
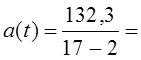 =8,82 пункта.
=8,82 пункта.
3. Среднее квадратическое отклонение уровней от тренда по формуле (9.35) составило:
 = 9,45 пункта.
= 9,45 пункта.
Небольшое превышение среднего квадратического отклонения над линейным указывает на отсутствие среди отклонений резко выделяющихся по абсолютной величине.
4. Коэффициент колеблемости: 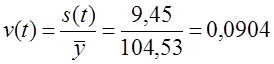 или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
или 9,04%. Колеблемость умеренная, не сильная. Для сравнения приводим показатели (без расчета) по колебаниям урожайности картофеля, данные таблиц 9.1 и 9.5 - отклонение от линейного тренда:
s (t ) = 14,38 ц с 1 га, v (t ) = 8,35%.
Для выявления типа колебаний воспользуемся приемом, предложенным М. Кендэлом. Он состоит в подсчете так называемых «поворотных точек» в ряду отклонений от тренда и i т. е. локальных экстремумов. Отклонение, либо большее по алгебраической величине, либо меньшее двух соседних, отмечается точкой. Обратимся к рис. 9.2. При маятниковой колеблемости все отклонения, кроме двух крайних, будут «поворотными», следовательно, их число составит п - 1. При долгопериодических циклах на цикл приходятся один минимум и один максимум, а общее число точек составит 2(n : l ), где l - длительность цикла. При случайно распределенной во времени колеблемости, как доказал М. Кендэл, число поворотных точек в среднем составит: 2/3 (n - 2). В нашем примере при маятниковой колеблемости было бы 15 точек, при связанной с 11-летним циклом было бы 2-(17: 11) ≈ 3 точки, при случайно распределенной во времени в среднем было бы (2/3)·(17-2) =10 точек.
Фактическое число точек 6 выходит за границы двукратного среднего квадратического отклонения числа поворотных точек, которое по Кендэлу равно , в нашем случае 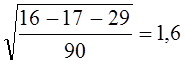 .
.
Наличие 6 точек, при 2 точках за цикл, означает, что в ряду могут быть примерно 3 цикла, продолжительность периода которых 5,5 - 6 лет. Возможно сочетание таких циклических колебаний со случайными.
Другой метод анализа типа колеблемости и поиска длины цикла основан на вычислении коэффициентов автокорреляции отклонений от тренда.
Автокорреляция - это корреляция между уровнями ряда или отклонениями от тренда, взятыми со сдвигом во времени: на 1 период (год), на 2, на 3 и т. д., поэтому говорят о коэффициентах автокорреляции разных порядков: первого, второго и т. д. Рассмотрим сначала коэффициент автокорреляции отклонений от тренда первого порядка.
Одна из основных формул для расчета коэффициента автокорреляции отклонений от тренда имеет вид:
 (9.36)
(9.36)
Как легко видеть по табл. 9.7, первое и последнее в ряду отклонения участвуют только в одном произведении в числителе, а все прочие отклонения от второго до (п - 1)-го - в двух. Поэтому и в знаменателе квадраты первого и последнего отклонений следует взять с половинным весом, как в хронологической средней. По данным табл. 9.7 имеем:

Теперь обратимся к рис. 9.2. При маятниковой колеблемости все произведения в числителе будут отрицательными величинами, и коэффициент автокорреляции первого порядка будет близок к -1. При долголериодических циклах будут преобладать положительные произведения соседних отклонений, а смена знака происходит лишь дважды за цикл. Чем длиннее Цикл, тем больше перевес положительных произведений в числителе, и коэффициент автокорреляции первого порядка ближе к +1. При случайно распределенной во времени колеблемости знаки отклонений чередуются хаотически, число положительных произведений близко к числу отрицательных, ввиду чего коэффициент автокорреляции близок к нулю. Полученное значение говорит о наличии как случайно распределенных во времени колебаний, так и циклических. Коэффициенты автокорреляции следующих порядков: II = - 0,577; Ш = -0,611; IV == -0,095; V = +0,376; VI = +0,404; VII = +0,044. Следовательно, противофаза цикла ближе всего кЗ годам (наибольший отрицательный коэффициент при сдвиге на 3 года), а совпадающие фазы ближе к б годам, что и дает длину цикла колебаний. Эти максимальные по абсолютной величине коэффициенты не близки к единице. Это означает, что циклическая колеблемость смешана со значительной случайной колеблемостью. Таким образом, подробный автокорреляционный анализ в целом дал те же результаты, что и выводы по автокорреляции первого порядка.
Если динамический ряд достаточно длинен, можно поставить и решить задачу об изменении показателей колеблемости с течением времени. Для этого рассчитывают эти показатели по подпериодам, но длительностью не менее 9-11 лет, иначе измерения колеблемости ненадежны. Кроме того, можно рассчитывать показатели колеблемости скользящим способом, а затем произвести их выравнивание, т. е. вычислить тренд показателей колеблемости. Это полезно, чтобы сделать вывод о действенности мер, применявшихся для уменьшения колебаний урожайности и других нежелательных колебаний, а также для того, чтобы по тренду сделать прогноз ожидаемых в будущем размеров колебаний.
9.8. Измерение устойчивости в динамике
Понятие «устойчивость» используется в весьма различных смыслах. По отношению к статистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивость как категория, противоположная колеблемости; 2) устойчивость направленности изменений, т. е. устойчивость тенденции.
В первом понимании показатель устойчивости, который может быть только относительным, должен изменяться от нуля до единицы (100%). Это разность между единицей и относительным показателем колеблемости. Коэффициент колеблемости составил 9,0%. Следовательно, коэффициент устойчивости равен 100% - 9,0% = 91,0%. Этот показатель характеризует близость фактических уровней к тренду и совершенно не зависит от характера последнего. Слабая колеблемость и высокая устойчивость уровней в данном смысле могут существовать даже при полном застое в развитии, когда тренд выражен горизонтальной прямой.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс их направленного изменения. Можно узнать, например, насколько устойчив процесс сокращения удельных затрат ресурсов на производство единицы продукции, является ли устойчивой тенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостью направленного изменения уровней динамического ряда следует считать такое изменение, в процессе которого каждый следующий уровень либо выше всех предшествующих (устойчивый рост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строго ранжированной последовательности уровней свидетельствует о неполной устойчивости изменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя. В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч. Спирмэна (Spearman) - r x .

где п - число уровней;
Δ i - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов) времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Это значение соответствует случаю полной устойчивости возрастания уровней. При полной противоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означает полную устойчивость процесса сокращения уровней. При хаотическом чередовании рангов уровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции. Приведем расчет коэффициента корреляции Спирмэна по данным о динамике индекса цен (табл. 9.7) в табл. 9.8.
Таблица 9.8
Расчет коэффициентов корреляции рангов Спирмена
|
Ранг лет, Р x |
Ранг уровней, Р у |
Р x -Р y |
(P x -P y ) 2 |
||
Ввиду наличия трех пар «связанных рангов» применяем формулу (8.26):
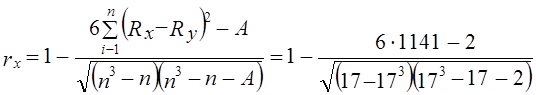
Отрицательное значение r x указывает на наличие тенденции снижения уровней, причем устойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в ряду динамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже 100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокий коэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. В целом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большая устойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
Устойчивость тенденции развития или комплексная устойчивость, в динамике может быть охарактеризована соотношением между среднегодовым абсолютным изменением и средним квадратическим (либо линейным) отклонением уровней от тренда:
Если, как нередко бывает, распределение отклонений уровней ряда от тренда близко к нормальному, то с вероятностью 0,95 отклонение от тренда вниз не превысит 1,645s (t ) по величине. Следовательно, если в ряду динамики
с > 1,64, то уровни, более низкие, чем предыдущие, в среднем будут встречаться менее 5раз за 100 периодов, или 1 раз из 20, т. е. устойчивость тренда будет высока. При с = 1 нарушения ранжированности уровней будут встречаться в среднем 16 раз из 100, а при с = 0,5 – уже 31 раз из 100, т. е. устойчивость тенденции будет низкой. Можно также пользоваться отношением среднего темпа прироста к коэффициенту колеблемости, что дает показатель, близкий к с - показателю устойчивости. Этот показатель более пригоден для экспоненциального тренда. О показателях устойчивости нелинейных трендов и об общих проблемах устойчивости экономических и социальных процессов можно подробнее прочесть в рекомендуемой к данной главе литературе .
Приняв в качестве гипотетической функции теоретических уровней прямую , определим параметры последней:


Решение этой системы можно осуществить по формулам:
Отсюда искомое уравнение тренда: ![]() . Подставляя в полученное уравнении значения 1, 2, 3, 4, 5, определяем теоретические уровни ряда (см. предпоследнюю графу табл. 4.3). Сравнивая значения эмпирических и теоретических уровней, видим, что они близки, т.е. можно сказать, что найденное уравнение весьма удачно характеризует основную тенденцию изменения уровней именно как линейную функцию.
. Подставляя в полученное уравнении значения 1, 2, 3, 4, 5, определяем теоретические уровни ряда (см. предпоследнюю графу табл. 4.3). Сравнивая значения эмпирических и теоретических уровней, видим, что они близки, т.е. можно сказать, что найденное уравнение весьма удачно характеризует основную тенденцию изменения уровней именно как линейную функцию.
Система нормальных уравнений упрощается, если отсчет времени ведется от середины ряда. Например, при нечетном числе уровней
серединная точка (год, месяц) принимается за нуль. Тогда предшествующие периоды обозначаются соответственно -1, -2, -3 и т.д., а следующие за средним – соответственно +1, +2, +3 и т.д. При четном числе уровней два срединных момента (периода) времени обозначают −1 и +1, а все последующие и предыдущие, соответственно, через два интервала: ![]() и т.д.
и т.д.
При таком порядке отсчета времени (от середины ряда) , система нормальных уравнений упрощается до следующих двух уравнений, каждое из которых решается самостоятельно:

Важное значение при построении модели временного ряда имеет учет сезонных и циклических колебаний. Простейшим подходом, позволяющим учесть в модели сезонные и циклические колебания, является расчет значений сезонной/циклической компоненты и построение аддитивной и мультипликативной модели временного ряда.
Общий вид аддитивной модели следующий: Y=T+S+E . Эта модель предполагает, что каждый уровень временного уровня ряда может быть представлен как сумма трендовой T , сезонной S и случайной компонент. Общий вид мультипликативной модели выглядит как: Y=T∙S∙E .
Выбор одной из двух моделей проводится на основе анализа структуры сезонных колебаний. Если амплитуда колебаний приблизительно постоянна, строят аддитивную модель временного ряда, в которой значения сезонной компоненты предполагаются постоянными для различных циклов. Если амплитуда сезонных колебаний возрастает или уменьшается, строят мультипликативную модель временного ряда, которая ставит уровни ряда в зависимость от значений сезонной компоненты.
Построение аддитивной и мультипликативной моделей сводится к расчету T, S, E для каждого уровня ряда. Этапы построения модели включают в себя следующие шаги:
1. Выравнивание исходного ряда методом скользящей средней
2. Расчет значений сезонной компоненты S .
3. Устранение сезонной компоненты из исходных уровней ряда и получение выровненных данных в аддитивной (T+E) или мультипликативной (T∙E) модели.
4. Аналитическое выравнивание уровней (T+E) или (T∙E) и расчет значений T с использованием полученного уравнения тренда.
5. Расчет полученных по модели значений (T+E) или (T∙E) .
6. Расчет абсолютных и/или относительных ошибок. Если полученные значения не содержат автокорреляции, ими можно заменить исходные уровни ряда и в дальнейшем использовать временной ряд ошибок E для анализа взаимосвязи исходного ряда и других временных рядов.
Рассмотрим другие методы анализа взаимосвязи, предположив что изучаемые временные ряды не содержат периодических колебаний. Допустим, что изучается зависимость между рядами х и у . Для количественной характеристики этой зависимости используется линейный коэффициент корреляции. Если рассматриваемые временные ряды имеют тенденцию, коэффициент корреляции по абсолютной величине будет высоким. Однако это не говорит о том, что х причина у . Высокий коэффициент корреляции в данном случае – это результат того, что х и у зависят от времени, или содержат тенденцию. При этом одинаковую или противоположную тенденцию могут иметь ряды, совершенно не связанные друг с другом причинно-следственной зависимостью. Например, коэффициент корреляции между численностью выпускников вузов и числом домов отдыха в РФ в период с 1970-1990 г. составил 0,8. Однако, это не говорит о том, что количество домов отдыха способствует росту числа выпускников или наоборот.
Для того чтобы получить коэффициенты корреляции, характеризующие причинно-следственную связь между изучаемыми рядами, следует избавиться от так называемой ложной корреляции, вызванной наличием тенденции в каждом ряду, которую устраняют одним из методов.
Предположим, что по двум временным рядам х t
и у t
строится уравнение парной регрессии линейной регрессии вида: ![]() . наличие тенденции в каждом из этих временных рядов означает, что на зависимую у t
и независимую х t
переменные модели оказывает воздействие фактор времени, который непосредственно в модели не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков за текущий и предыдущие моменты времени, которая получила название автокорреляции в остатках.
. наличие тенденции в каждом из этих временных рядов означает, что на зависимую у t
и независимую х t
переменные модели оказывает воздействие фактор времени, который непосредственно в модели не учтен. Влияние фактора времени будет выражено в корреляционной зависимости между значениями остатков за текущий и предыдущие моменты времени, которая получила название автокорреляции в остатках.
Автокорреляция в остатках – это нарушение одной из основных предпосылок МНК – предпосылки о случайности остатков, полученных по уравнению регрессии. Один из возможных путей решения этой проблемы состоит в применении обобщенного МНК.
Для устранения тенденции используются две группы методов:
Методы, основанные на преобразовании уровней исходного ряда в новые переменные, не содержащие тенденции (метод последовательных разностей и метод отклонения от трендов);
Методы, основанные на изучении взаимосвязи исходных уровней временных рядов при элиминировании воздействия фактора времени на зависимую и независимую переменные модели (включение в модель регрессии по временным рядам фактора времени).
Пусть имеются два временных ряда и , каждый из которых содержит трендовую компоненту Т и случайную составляющую . Аналитическое выравнивание каждого из этих рядов позволяет найти параметры соответствующих уравнений трендов и определить расчетные по тренду уровни и соответственное. Эти расчетные значения можно принять за оценку трендовой компоненты Т каждого ряда. Поэтому влияние тенденции можно устранить путем вычитания расчетных значений уровней ряда из фактических. Эту процедуру проделывают для каждого временного ряда в модели. Дальнейший анализ взаимосвязи рядов проводят с использованием не исходных уровней, а отклонений от тренда и . Именно в этом и заключается метод отклонений от тренда.
В ряде случаев вместо аналитического выравнивания временного ряда с целью устранения тенденции можно применить более простой метод – метод последовательных разностей. Если временной ряд содержит ярко выраженную линейную тенденцию, ее можно устранить путем замены исходных уровней ряда цепными абсолютными приростами (первыми разностями).
Коэффициент b – константа, которая не зависит от времени. При наличии сильной линейной тенденции отставки достаточно малы и в соответствии с предпосылками МНК носят случайный характер. Поэтому первые разности уровней ряда не зависят от переменной времени, их можно использовать для дальнейшего анализа.
Если временной ряд содержит тенденцию в форме параболы второго порядка, то для ее устранения можно заменить исходные уровни ряда на вторые разности: .
Если тенденции временного ряда соответствует экспоненциальной, или степенной, тренд, метод последовательных разностей следует применять не к исходным уровням ряда, а к их логарифмам.
Модель вида: ![]() также относится к группе моделей, включающих фактор времени. Преимущество данной модели перед методами отклонений от трендов и последовательных разностей состоит в том, что она позволяет учесть всю информацию, содержащуюся в исходных данных, поскольку значения и – это уровни исходных временных рядов. Кроме того, модель строится по всей совокупности данных за рассматриваемый период в отличие от метода последовательных разностей, который приводит к потере числа наблюдений. Параметры этой модели определяются обычным МНК.
также относится к группе моделей, включающих фактор времени. Преимущество данной модели перед методами отклонений от трендов и последовательных разностей состоит в том, что она позволяет учесть всю информацию, содержащуюся в исходных данных, поскольку значения и – это уровни исходных временных рядов. Кроме того, модель строится по всей совокупности данных за рассматриваемый период в отличие от метода последовательных разностей, который приводит к потере числа наблюдений. Параметры этой модели определяются обычным МНК.
Пример. Построим уравнение тренда по исходным данным таблицы 4.4.
Таблица 4.4
Расходы на конечное потребление и совокупный доход (усл. ед.)
Система нормальных уравнений имеет вид:

По исходным данным рассчитаем необходимые величины и подставим в систему:

Уравнение регрессии имеет вид: .
Интерпретация параметров уравнения следующая: характеризует, что при увеличении совокупного дохода на 1 д.е. расходы на конечное потребление возрастут в среднем на 0,49 д.е в условиях существования неизменной тенденции. Параметр означает, что воздействие всех факторов, кроме совокупного дохода, на расходы на конечное потребление приведет к его среднегодовому абсолютному приросту на 0,63 д.е.
Рассмотрим уравнение регрессии вида: ![]() . Для каждого момента времени значение компоненты определяются как или . Рассматривая последовательность остатков как временной ряд, можно построить график их зависимости от времени. В соответствии с предпосылками МНК остатки должны быть случайными (рис. 4.4).
. Для каждого момента времени значение компоненты определяются как или . Рассматривая последовательность остатков как временной ряд, можно построить график их зависимости от времени. В соответствии с предпосылками МНК остатки должны быть случайными (рис. 4.4).
Рис. 4.4 Случайные остатки
Однако при моделировании временных рядов нередко встречаются ситуации, когда остатки содержат тенденцию или циклические колебания (рис. 4.5). Это говорит о том, что каждое следующее значение остатков зависит от предшествующих. В этом случае говорят о наличии автокорреляции в остатках.
а) б)
Рис. 4.5 Убывающая тенденция (а ) и циклические колебания (б )
в остатках
Автокорреляция случайной составляющей - корреляционная зависимость текущих и предыдущих значений случайной составляющей. Последствия автокорреляции случайной составляющей:
Коэффициенты регрессии становятся неэффективными;
Стандартные ошибки коэффициентов регрессии становятся заниженными, а значения t –критерия завышенными.
Для определения автокорреляции остатков известны два наиболее распространенных метода определения автокорреляции остатков. Первый метод – это построение графика зависимости остатков от времени и визуальное определение наличия или отсутствия автокорреляции. Второй метод – это использование критерия Дарбина-Уотсона, который сводится к проверке гипотезы:
Н0 (основная гипотеза): автокорреляция отсутствует;
Н1 и Н2 (альтернативные гипотезы): присутствует положительная или отрицательная автокорреляция в остатках соответственно.
Для проверки основной гипотезы используется статистика критерия Дарбина-Уотсона:
 где .
где .
На больших выборках d≈2(1- ), где - коэффициент автокорреляции 1-го порядка.
 .
.
Если в остатках существует полная положительная автокорреляция и =1, то d=0; если в остатках есть полная отрицательная автокорреляция, то = -1 и d=4; если автокорреляция остатков отсутствует, то = 0, то d=2. Следовательно, 0.
Существуют специальные статистические таблицы для определения нижней и верхней критических границ d -статистики – d L и d U . Они определяются в зависимости от n, числа независимых переменных k и уровня значимости .
Если d набл ‹d L , то принимается гипотеза Н1: положительная автокорреляция.
Если d и ‹d набл ‹2,
Если 2‹d набл ‹4-d и, то принимается гипотеза Н0: автокорреляции нет.
Если d набл ›4-d L , то принимается гипотеза Н2: отрицательная автокорреляция.
Если 4-d и ‹d набл ‹4-d L , и d L ‹d набл ‹d и, то имеет место случай неопределенности.
0 d L d U 2 4- d U 4- d L 4
Рис. 4.6 Алгоритм проверки гипотезы о наличии автокорреляции остатков
Для применения критерия Дарбина-Уотсона есть ограничения. Он неприменим для моделей, включающих в качестве независимых переменных лаговые значения результативного признака, т.е. к моделям авторегрессии. Методика направлена только на выявление автокорреляции остатков первого порядка. Результаты являются более достоверными при работе с большими выборками.
В тех случаях, когда имеет место автокорреляция остатков, для определения оценок параметров a, b используют обобщенный метод МНК, который заключается в последовательности следующих шагов:
1. Преобразовать исходные переменные y t и x t к виду

2. Применив обычный МНК к уравнению ![]() , где
, где ![]() определить оценки параметров и b.
определить оценки параметров и b.
4. Выписать исходное уравнение ![]() .
.
Среди эконометрических моделей, построенных по временным данным, выделяют динамические модели.
Эконометрическая модель является динамической , если в данный момент времени t она учитывает значения входящих в нее переменных, относящихся как к текущему, так и к предыдущим моментам времени, т.е. эта модель отражает динамику исследуемых переменных в каждый момент времени.
Существует два основных типа динамических эконометрических моделей. К моделям первого типа относятся модели авторегрессии и модели с распределенным лагом, в которых значение переменной за прошлые периоды времени (лаговые переменные) непосредственно включены в модель. Модели второго типа учитывают динамическую информацию в неявном виде. В эти модели включены переменные, характеризующие ожидаемый и желаемый уровень результата, или один из факторов в момент времени t.
Модель с распределенным лагом имеет вид:
Построение моделей с распределенным лагом и моделей авторегрессии имеет свою специфику. Во-первых, оценка параметров моделей авторегрессии, а в большинстве случаев и моделей распределенным лагом не может быть проведена с помощью обычного МНК ввиду нарушения его предпосылок и требует специальных статистических методов. Во-вторых, исследователям приходится решать проблемы выбора оптимальной величины лага и определения его структуры. Наконец, в третьих, между моделями с распределенным лагом и моделями авторегрессии имеется определенная взаимосвязь, и в некоторых случаях необходимо осуществить переход от одноного типа моделей к другому.
Рассмотрим модель с распределенным лагом в предположении, что максимальная величина лага конечна:
Даная модель говорит о том, что если в некоторый момент времени t происходит изменение независимой переменной x , то это изменение будет влиять на значения переменной y в течение l следующих моментов времени.
Коэффициент регрессии b 0 при переменной x t характеризует среднее абсолютное изменение y t при изменении x t на 1 ед. своего измерения в некоторый фиксированный момент времени t , без учета воздействия лаговых значений фактора x. Этот коэффициент называется краткосрочным мультипликатором.
В момент t+1 воздействие факторной переменной x t на результат y t составит (b 0 +b 1) условных единиц; в момент времени t+2 это воздействие можно охарактеризовать суммой (b 0 +b 1 +b 2) и т.д. Полученные таким образом суммы называются промежуточными мультипликаторами .
С учетом конечной величины лага можно сказать, что изменение переменной x t в момент времени t на 1 условную единицу приведет к общему изменению результата через l моментов времени (b 0 +b 1 +b 2 +…+b l ).
Введем следующее обозначение: b=(b 0 +b 1 +b 2 +…+b l ). Величину b называется долгосрочным мультипликатором , который показывает абсолютное изменение в долгосрочном периоде t+l результата y под влиянием изменения на 1 ед. фактора x .
Величины ![]() называются относительными коэффициентами
модели с распределенным лагом. Если все коэффициенты b j
имеют одинаковые знаки,
то .
Относительные коэффициенты являются весами для соответствующих коэффициентов b j
. Каждый из них измеряет долю общего изменения результативного признака в момент времени t+j
.
называются относительными коэффициентами
модели с распределенным лагом. Если все коэффициенты b j
имеют одинаковые знаки,
то .
Относительные коэффициенты являются весами для соответствующих коэффициентов b j
. Каждый из них измеряет долю общего изменения результативного признака в момент времени t+j
.
Зная величины , с помощью стандартных формул можно определить еще две важные характеристики модели множественной регрессии: величину среднего и медианного лагов.
Средний лаг рассчитывается по формуле средней арифметической взвешенной:
и представляет собой средний период, в течение которого будет происходить изменение результата под воздействием изменения фактора x в момент t. Если значение среднего лага небольшое, то это говорит о довольно быстром реагировании y на изменение x. Высокое значение среднего лага говорит о том, что воздействие фактора на результат будет сказываться в течение длительного периода времени.
Медианный лаг (L Me) – это величина лага, для которого период, в течение которого . Это тот период времени, в течение которого с момента времени t будет реализована половина общего воздействия фактора на результат.
Изложенные выше приемы анализа параметров модели с распределенным лагом действительны только в предположении, что все коэффициенты при текущем и лаговых значениях исследуемого фактора имеют одинаковые знаки. Это предположение вполне оправдано с экономической точки зрения: воздействие одного и того же фактора на результат должно быть однонаправленным независимо от того, с каким временным лагом измеряется сила или теснота связи между этими признаками. Однако на практике получить статистически значимую модель, параметры которой имели бы одинаковые знаки, особенно при большой величине лага l , чрезвычайно сложно.
Применение обычного МНК к таким моделям в большинстве случаев затруднительно по следующим причинам:
Текущие и лаговые значения независимой переменной, как правило, тесно связаны друг с другом, тем самым оценка параметров модели проводится в условиях высокой мультиколлинеарности;
При большой величине лага снижается число наблюдений, по которому строится модель, и увеличивается число ее факторных признаков, что ведет к потере числа степеней свободы в модели;
В моделях с распределенным лагом часто возникает проблема автокорреляции остатков.
Как и в модели с распределенным лагом, b 0 в этой модели характеризует краткосрочное изменение y t под воздействием изменения x t на 1 ед. Однако промежуточные и долгосрочный мультипликаторы в модели авторегрессии несколько иные. К моменту времени t+1 результат y t изменился под воздействием изменения изучаемого фактора в момент времени t на b 0 единиц, а y t +1 – под воздействием своего изменения в непосредственно предшествующим момент времени на с 1 единиц. Таким образом, общее абсолютное изменение результата в момент t+1 составит b 0 с 1 . Аналогично в момент времени t+2 абсолютное изменение результата составит b 0 с 1 2 единиц и т.д. Следовательно, долгосрочный мультипликатор в модели авторегрессии можно рассчитать как сумму краткосрочного и промежуточного мультипликаторов:
Такая интерпретация коэффициентов модели авторегрессии и расчет долгосрочного мультипликатора основаны на предпосылке о наличии бесконечного лага в воздействии текущего значения зависимой переменной на ее будущие значения.
Пример. Предположим, по данным о динамике показателей потребления и дохода в регионе была получена модель авторегрессии, описывающая зависимость среднедушевого объема потребления за год (С, млн. руб.) от среднедушевого совокупного годового дохода (Y, млн. руб.) и объема потребления предшествующего года:
![]() .
.
Краткосрочный мультипликатор равен 0,85. В этой модели он представляет собой предельную склонность к потреблению в краткосрочном периоде. Следовательно, увеличение среднедушевого совокупного дохода на 1 млн. руб. приводит к росту объема потребления в тот же год в среднем на 850 тыс. руб. Долгосрочную предельную склонность к потреблению в данной модели можно определить как
![]() .
.
В долгосрочной перспективе рост среднедушевого совокупного дохода на 1 млн. руб. приведет к росту объема потребления в среднем на 944 тыс. руб. Промежуточные показатели предельной склонности к потреблению можно определить, рассчитав необходимые частные суммы за соответствующие периоды времени. Например, для момента времени t+1 получим:
Это означает, что увеличение среднедушевого совокупного дохода в текущем периоде на 1 млн. руб. ведет к увеличению объема потребления в среднем на 935 тыс. руб. в ближайшем следующем периоде.
Линейное уравнение тренда имеет вид y = at + b.
Параметры уравнений функции тренда находят с помощью теории корреляции методом наименьших квадратов.
1.Метод наименьших квадратов.
Метод наименьших квадратов МНК), является одним из способов противостоять ошибкам измерений.(Как в Физике погрешность отклонений)
Этот метод как правило используют для нахождения параметров уравнений (Линий, гипербол парабол и т.д.)
Этот способ заключается в минимизации суммы квадратов отклонений.
Смысл МНК можно выразить через вот этот график
2. Анализ точности определения оценок параметров уравнения тренда(по таблице стьюдента находим ТТабл и делаем интервальный прогноз,т.е. выявляем реднеквадратическую ошибку)
3.Проверка гипотез относительно коэффициентов линейного уравнения тренда(статистика критерий стьюдента,фишера)
Проверка на наличие автокорреляции остатков.
Важной предпосылкой построения качественной регрессионной модели по МНК является независимость значений случайных отклонений от значений отклонений во всех других наблюдениях. Это гарантирует отсутствие коррелированности между любыми отклонениями и, в частности, между соседними отклонениями.
Автокорреляция (последовательная корреляция)
Автокорреляция остатков (отклонений) обычно встречается в регрессионном анализе при использовании данных временных рядов и очень редко при использовании перекрестных данных.
Проверка наличия гетероскедастичности
.
1) Методом графического анализа остатков
.
В этом случае по оси абсцисс откладываются значения объясняющей переменной X, а по оси ординат либо отклонения e i , либо их квадраты e 2 i .
Если имеется определенная связь между отклонениями, то гетероскедастичность имеет место. Отсутствие зависимости скорее всего будет свидетельствовать об отсутствии гетероскедастичности.
2) При помощи теста ранговой корреляции Спирмена.
Коэффициент ранговой корреляции Спирмена.
36. Методы измерения устойчивости тенденций динамики (коэффициент рангов Спирмена).
Понятие «устойчивость» используется в весьма различных смыслах. По отношению кстатистическому изучению динамики мы рассмотрим два аспекта этого понятия: 1) устойчивостькак категория, противоположная колеблемости; 2) устойчивость направленности изменений, т.е. устойчивость тенденции.
Устойчивость во втором смысле характеризует не сами по себе уровни, а процесс ихнаправленного изменения. Можно узнать, например, насколько устойчив процесс сокращенияудельных затрат ресурсов на производство единицы продукции, является ли устойчивойтенденция снижения детской смертности и т. д. С этой точки зрения полной устойчивостьюнаправленного изменения уровней динамического ряда следует считать такое изменение, впроцессе которого каждый следующий уровень либо выше всех предшествующих (устойчивыйрост), либо ниже всех предшествующих (устойчивое снижение). Всякое нарушение строгоранжированной последовательности уровней свидетельствует о неполной устойчивостиизменений.
Из определения понятия устойчивости тенденции вытекает и метод построения ее показателя.В качестве показателя устойчивости можно использовать коэффициент корреляции рангов Ч.Спирмэна (Spearman) - rx.
где п - число уровней;
I - разность рангов уровней и номеров периодов времени.
При полном совпадении рангов уровней, начиная с наименьшего, и номеров периодов (моментов)времени по их хронологическому порядку коэффициент корреляции рангов равен +1. Этозначение соответствует случаю полной устойчивости возрастания уровней. При полнойпротивоположности рангов уровней рангам лет коэффициент Спирмэна равен -1, что означаетполную устойчивость процесса сокращения уровней. При хаотическом чередовании ранговуровней коэффициент близок к нулю, это означает неустойчивость какой-либо тенденции.
Отрицательное значение rx указывает на наличие тенденции снижения уровней, причемустойчивость этой тенденции ниже средней.
При этом следует иметь в виду, что даже при 100%-ной устойчивости тенденции в рядудинамики может быть колеблемость уровней, и коэффициент их устойчивости будет ниже100%. При слабой колеблемости, но еще более слабой тенденции, напротив, возможен высокийкоэффициент устойчивости уровней, но близкий к нулю коэффициент устойчивости тренда. Вцелом же оба показателя связаны, конечно, прямой зависимостью: чаще всего большаяустойчивость уровней наблюдается одновременно с большей устойчивостью тренда.
37. Моделирование тенденции ряда динамики при наличии структурных изменений.
От сезонных и циклических колебаний следует отличать единовременные изменения характера тенденции временного ряда, вызванные структурными изменениями в экономике или иными факторами. В этом случае, начиная с некоторого момента времени t, происходит изменение характера динамики изучаемого показателя, что приводит к изменению параметров тренда, описывающего эту динамику.
Момент t сопровождается значительными изменениями ряда факторов, оказывающих сильное воздействие на изучаемый показатель Моделирование тенденции временного ряда при наличии структурных изменений.. Чаще всего эти изменения вызваны изменениями в общеэкономической ситуации или событиями глобального характера, приведшими к изменению структуры экономики. Если исследуемый временной ряд включает в себя соответствующий момент времени, то одной из задач его изучения становится выяснение вопроса о том, значительно ли повлияли общие структурные изменения на характер этой тенденции.
Если это влияние значимо, то для моделирования тенденции данного временного ряда следует использовать кусочно-линейные модели регрессии, т.е. разделить исходную совокупность на 2 подсовокупности (до момента времени t и после) и строить отдельно по каждой подсовокупности уравнения линейной регрессии.
Если структурные изменения незначительно повлияли на характер тенденции ряда Моделирование тенденции временного ряда при наличии структурных изменений., то ее можно писать с помощью единого для всей совокупности данных уравнения тренда.
Каждый из описанных выше подходов имеет свои положительные и отрицательные стороны. При построении кусочно-линейной модели снижается остаточная сумма квадратов по сравнению с единым для всей совокупности уравнением тренда. Но разделение совокупности на части ведет к потере числа наблюдений, и к снижению числа степеней свободы в каждом уравнении кусочно-линейной модели. Построение единого уравнения тренда позволяет сохранить число наблюдений исходной совокупности, но остаточная сумма квадратов по этому уравнению будет выше по сравнению с кусочно-линейной моделью. Очевидно, что выбор модели зависит от соотношения между снижением остаточной дисперсии и потерей числа степеней свободы при переходе от единого уравнения регрессии к кусочно-линейной модели.
38. Регрессионный анализ связных динамических рядов.
Многомерные временные ряды, показывающие зависимость результативного признака от одного или нескольких факторных, называютсвязными рядами динамики. Применение методов наименьших квадратов для обработки рядов динамики не требует выдвижения никаких предположений о законах распределения исходных данных. Однако при использовании метода наименьших квадратов для обработки связных рядов следует учитывать наличие автокорреляции (авторегрессии), которая не учитывалась при обработке одномерных рядов динамики, поскольку ее наличие способствовало более плотному и четкому выявлению тенденции развития рассматриваемого социально – экономического явления во времени.
Выявление автокорреляции в уровнях ряда динамики
В рядах динамики экономических процессов между уровнями, особенно близко расположенными, существует взаимосвязь. Ее удобно представить в виде корреляционной зависимости между рядами y1,y2,y3,…..yn h y1+h, y2+h,…, yn+h. Временное смещение L называется сдвигом,а само явление взаимосвязи – автокорреляцией.
Автокорреляционная зависимость особенно существенна между последующими и предшествующими уровнями ряда динамики.
Различают два вида автокорреляции:
Автокорреляция в наблюдениях за одной или более переменными;
Автокорреляция ошибок или автокорреляция в отклонениях от тренда.
Наличие последней приводит к искажению величин средних квадратических ошибок коэффициентов регрессии, что затрудняет построение доверительных интервалов для коэффициентов регрессии, а так же проверку их значимости.
Автокорреляцию измеряют при помощи циклического коэффициента автокорреляции, который может рассчитываться не только между соседними уровнями, т.е. сдвинутыми на один период, но и между сдвинутыми на любое число единиц времени (L). Этот сдвиг, именуемыйвременным лагом, определяет и порядок коэффициентов автокорреляции: первого порядка (при L=1), второго порядка (при L=2) и т.д. Однако наибольший интерес для исследования представляет вычисление нециклического коэффициента (первого порядка), так как наиболее сильные искажения результатов анализа возникают при корреляции между исходными уровнями ряда и теми же уровнями, сдвинутыми на одну единицу времени.
Для суждения о наличии или отсутствия автокорреляции в исследуемом ряду фактическое значение коэффициентов автокорреляции сопоставляется с табличным (критическим) для 5% - го или 1% - го уровня значимости.
Если фактическое значение коэффициента автокорреляции меньше табличного, то гипотеза об отсутствии автокорреляции в ряду может быть принята. Когда же фактическое значение больше табличного, можно сделать вывод о наличии автокорреляции в ряду динамики.
